Replex: A Scalable, Highly Available Multi-Index Data Store
This paper received the best paper award at Usenix ATC'16 last week. It considers a timely important problem. With NoSQL databases, we got scalability, availability, and performance, but we lost secondary keys. How do we put back the secondary indices, without compromising scalability, availability, and performance.
The paper mentions that previous work on Hyperdex did a good job of re-introducing secondary keys to NoSQL, but with overhead: Hyperdex generates and partitions an additional copy of the datastore for each key. This introduces overhead for both storage and performance: supporting just one secondary key doubles storage requirements and write latencies.
Replex adds secondary keys to NoSQL databases without that overhead. The key insight of Replex is to combine the need to replicate for fault-tolerance and the need to replicate for index availability. After replication, Replex has both replicated and indexed a row, so there is no need for explicit indexing.
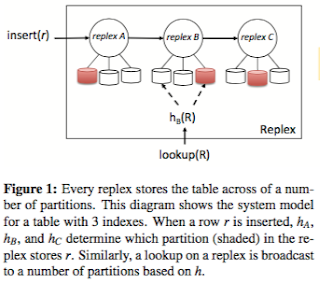 All replexes store the same data (every row in the table), the only difference across replexes is the way data is partitioned and sorted, which is by the sorting key of the index associated with the replex. Each replex is associated with a sharding function, h, such that h(r) defines the partition number in the replex that stores row r.
All replexes store the same data (every row in the table), the only difference across replexes is the way data is partitioned and sorted, which is by the sorting key of the index associated with the replex. Each replex is associated with a sharding function, h, such that h(r) defines the partition number in the replex that stores row r.
So, that was easy. But, there is an additional complication that needs to be dealt with. The difficulty arises because individual replexes can have requirements, such as uniqueness constraints, that cause the same operation to be both valid and invalid depending on the replex. Figure 2 gives an example scenario, linearizability requirement for a distributed log.

To deal with this problem, datastores with global secondary indexes need to employ a distributed transaction for update operations, because an operation must be atomically replicated as valid or invalid across all the indexes. But to use a distributed transaction for every update operation would cripple system throughput.
To remove the need for a distributed transaction in the replication protocol, they modify chain replication to include a consensus protocol. Figure 3 illustrates this solution. When the consensus phase (going to the right in Figure 3) reaches the last partition in the chain, the last partition aggregates each partition's decision into a final decision, which is simply the logical AND of all decisions. Then comes the replication phase, where the last partition initiates the propagation of this final decision back up the chain. As each partition receives this final decision, if the decision is to abort, then the partition discards that operation. If the decision is to commit, then that partition commits the operation to disk and continues propagating the decision.

This has similarities to the CRAQ protocol for chain replication. Linked is an earlier post that contains a summary of chain replication and CRAQ protocol.
If a partition fails, a simple recovery protocol would redirect queries originally destined for the failed partition to the other replex. Then the failure amplification is maximal: the read must now be broadcast to every partition in the other replex, and at each partition, a read becomes a brute-force search that must iterate through the entire local storage of a partition.
On the other hand, to avoid failure amplification within a failure threshold f, one could introduce f replexes with the same sharding function, h; as exact replicas. There is no failure amplification within the failure threshold, because sharding is identical across exact replicas. But the cost is storage and network overhead in the steady-state.
This is the tradeoff, and the paper dedicates "Section 3: Hybrid Replexes" to explore this tradeoff space.
Replex solves an important problem with less overhead than previous solutions. The hybrid replexes method (explained in Section 3) can also be useful in other problems for preventing failure amplification.
The paper mentions that previous work on Hyperdex did a good job of re-introducing secondary keys to NoSQL, but with overhead: Hyperdex generates and partitions an additional copy of the datastore for each key. This introduces overhead for both storage and performance: supporting just one secondary key doubles storage requirements and write latencies.
Replex adds secondary keys to NoSQL databases without that overhead. The key insight of Replex is to combine the need to replicate for fault-tolerance and the need to replicate for index availability. After replication, Replex has both replicated and indexed a row, so there is no need for explicit indexing.
How does Replex work?

So, that was easy. But, there is an additional complication that needs to be dealt with. The difficulty arises because individual replexes can have requirements, such as uniqueness constraints, that cause the same operation to be both valid and invalid depending on the replex. Figure 2 gives an example scenario, linearizability requirement for a distributed log.

To deal with this problem, datastores with global secondary indexes need to employ a distributed transaction for update operations, because an operation must be atomically replicated as valid or invalid across all the indexes. But to use a distributed transaction for every update operation would cripple system throughput.
To remove the need for a distributed transaction in the replication protocol, they modify chain replication to include a consensus protocol. Figure 3 illustrates this solution. When the consensus phase (going to the right in Figure 3) reaches the last partition in the chain, the last partition aggregates each partition's decision into a final decision, which is simply the logical AND of all decisions. Then comes the replication phase, where the last partition initiates the propagation of this final decision back up the chain. As each partition receives this final decision, if the decision is to abort, then the partition discards that operation. If the decision is to commit, then that partition commits the operation to disk and continues propagating the decision.

This has similarities to the CRAQ protocol for chain replication. Linked is an earlier post that contains a summary of chain replication and CRAQ protocol.
Fault-tolerance
There is additional complexity due to failure of the replicas. Failed partitions bring up two concerns: how to reconstruct the failed partition and how to respond to queries that would have been serviced by the failed partition.If a partition fails, a simple recovery protocol would redirect queries originally destined for the failed partition to the other replex. Then the failure amplification is maximal: the read must now be broadcast to every partition in the other replex, and at each partition, a read becomes a brute-force search that must iterate through the entire local storage of a partition.
On the other hand, to avoid failure amplification within a failure threshold f, one could introduce f replexes with the same sharding function, h; as exact replicas. There is no failure amplification within the failure threshold, because sharding is identical across exact replicas. But the cost is storage and network overhead in the steady-state.
This is the tradeoff, and the paper dedicates "Section 3: Hybrid Replexes" to explore this tradeoff space.
Concluding remarks
The paper compares Replex to Hyperdex and Cassandra and shows that Replex's steady-state performance is 76% better than Hyperdex and on par with Cassandra for writes. For reads, Replex outperforms Cassandra by as much as 2-9x while maintaining performance equivalent with HyperDex. In addition, the paper shows that Replex can recover from one or two failures 2-3x faster than Hyperdex.Replex solves an important problem with less overhead than previous solutions. The hybrid replexes method (explained in Section 3) can also be useful in other problems for preventing failure amplification.





Comments