Paper Summary: High-availability distributed logging with BookKeeper
This paper is brought to you by the Yahoo Research group that developed the ZooKeeper, and it appeared in LADIS'12.
BookKeeper targets the logging problem. More specifically, the distributed logging problem where high-availability is important and where many distributed clients are interested in reading the logs.
Most current applications log to the local disk, but this constitutes a single point of failure (SPOF) and betrays high-availability. A hasty remedy is to write to an NFS partition to store log files remotely. But now the NFS server becomes the SPOF. (We can of course replicate the NSF server, but the performance would suffer.) Another solution is to use NetApp filers that implement RAID. This costs money, and still does not completely solve SPOF.
BookKeeper provides a no-SPOF efficient data store for serving a large number of concurrent single-writer, multiple-reader logs. It stripes log entries across servers, leading to higher throughput. BookKeeper is opensource and is used in production systems.
BookKeeper presents two case studies: Hedwig and HDFS Namenode. Hedwig is a scalable topic-based publish-subscribe system. To guarantee the delivery of messages despite partitions and server failures, Hedwig uses logging to persist published messages, which is implemented with BookKeeper. Hedwig is in production use and serves push notifications for Yahoo! properties (e.g., notifications for mobile devices).
The other use case concerns replicating the HDFS Namenode, the component of HDFS (Hadoop Distributed File System) that manages the file system metadata. On each update, the Namenode writes synchronously to a journal to guarantee that the update is durable. But unfortunately the Namenode is a SPOF. To enable efficient journaling and strong durability through replication, BookKeeper is used for implementing a journal manager for HDFS. The implementation is currently part of the HDFS codebase.
BookKeeper assumes that there is only a single client writing to a ledger (clients can employ ZooKeeper coordination for this), and in return it guarantees that, once a ledger is closed, all other clients that read from it read the same sequence of entries.
Here is the happy path for BookKeeper. An application using BookKeeper initially designates a ledger writer. This ledger writer creates a ledger and appends data to the ledger; only the ledger writer is able to append entries to the ledger. Eventually, after appending an arbitrary number of entries to the ledger, the ledger writer closes it. Once the ledger is closed, its content is immutable. Clients can open closed ledgers for reading and any individual ledger can have multiple readers over time, and even concurrent readers.
The main calls in the API enable applications to:
All these calls have both a synchronous and an asynchronous version.
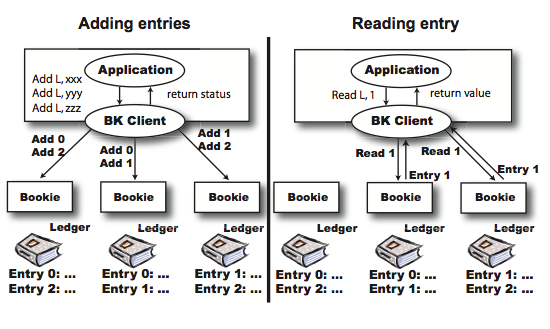 Creating and using a ledger.
Creating and using a ledger.
When a client creates a ledger, it selects a set of bookies to form an ensemble for the ledger and stores the ensemble information as part of the ledger metadata on ZooKeeper. For each entry the ledger writer adds to the ledger, it replicates the entry across f+1 bookies. A request to add an entry e completes successfully if e has been successfully replicated across f+1 bookies. If a bookie crashes, then the client replaces that bookie. BookKeeper uses ZooKeeper to keep track of configuration changes for a ledger.
Closing a ledger.
When closing a ledger, the ledger writer writes to ZooKeeper the last entry that has been written successfully, as part of the ledger metadata. If a ledger writer crashes prematurely, before it closes its open ledger, a ledger reader would need to do ledger recovery.
Ledger recovery.
When a ledger reader opens a ledger for reading, it first obtains the ledger metadata. If it finds that it has not been closed by checking the state of the ledger, the ledger reader triggers a recovery procedure. The first step of recovery for a given ledger consists of having the reader client asking each bookie in the ensemble for the last add confirmed (LAC) field in the last entry that the bookie has processed for the ledger. Since reads are based on entry id, the recovery process can start reading from the highest LAC it receives, and thus it is not necessary to read the entire ledger.
Reading from an open ledger.
BookKeeper also enables clients to read from open ledgers. When clients need to read from an open ledger, they invoke a call to open the ledger that does not try to recover it if it is not closed. To avoid reading partially replicated entries from the ledger, which may not be in the ledger once it is closed, the client asks bookies for their LAC values. Reading entry i ≤ LAC is safe, since the ledger writer has marked it as successfully replicated.
 To enable recovery, upon each request to append an entry to a ledger, a bookie appends this entry to the journal and flushes the write to the local disk device. A bookie only acknowledges to the client once it receives a confirmation that the flush operation has completed successfully. Note that the journal is shared across all active ledgers the bookie is currently storing. A bookie also writes entries to the ledger device to serve read requests. Thus, read traffic does not affect the performance of writes to the journal device.
To enable recovery, upon each request to append an entry to a ledger, a bookie appends this entry to the journal and flushes the write to the local disk device. A bookie only acknowledges to the client once it receives a confirmation that the flush operation has completed successfully. Note that the journal is shared across all active ledgers the bookie is currently storing. A bookie also writes entries to the ledger device to serve read requests. Thus, read traffic does not affect the performance of writes to the journal device.
The ledger device stores ledger entries along with an index for each ledger. Bookie has a single file, called entry log, and interleaves entries of different ledgers by appending entries of all ledgers. For each ledger, Bookie also keeps in-memory an index mapping the entry identifier to its position in the entry log.
This design targets workloads dominated by writes, while not neglecting the performance of reads. Requests to add an entry to a ledger return as soon as the entry is flushed to the journal of a bookie, and writes to the ledger device are asynchronous and mostly sequential to enable the writes to this device to keep up with the writes to the journal device. To serve a read request, it is necessary to obtain the position of the entry in the entry log. If the index page is cached, then the read requires one disk seek.
BookKeeper stores metadata on ZooKeeper.
The ledger metadata includes the ensemble composition of ledgers, write quorum size, ledger status, the last entry successfully written to a closed ledger. For the metadata store, BookKeeper uses ZooKeeper. "A different, more scalable data store becomes necessary when the number of active ledgers is of the order of tens to hundreds of millions." For the availability of bookies, BookKeeper relies upon ZooKeeper because it provides ephemeral znodes and watches.
 Using a 3E-2Q configuration, Figure shows throughput and latency for a single client as the maximum number of outstanding operations is increased. This leads to a higher throughput, in particular for 128-byte entries. No batching tricks employed to improve throughput, the processing of an operation is triggered by the call.
Using a 3E-2Q configuration, Figure shows throughput and latency for a single client as the maximum number of outstanding operations is increased. This leads to a higher throughput, in particular for 128-byte entries. No batching tricks employed to improve throughput, the processing of an operation is triggered by the call.
 Here 12 clients write simultaneously to a set of bookies, and the aggregate throughput is measured. Compared to the results for a single client writer, the aggregate throughput is substantially higher for shorter entries. For longer entries, throughput is limited by the speed with which bookies are able to write to disk, so adding more bookies to the pool (configurations with 6E) results in increased throughput.
Here 12 clients write simultaneously to a set of bookies, and the aggregate throughput is measured. Compared to the results for a single client writer, the aggregate throughput is substantially higher for shorter entries. For longer entries, throughput is limited by the speed with which bookies are able to write to disk, so adding more bookies to the pool (configurations with 6E) results in increased throughput.
The Tango paper mentions BookKeeper and states that it has an implementation of BookKeeper in 300 lines. How would you implement BookKeeper in Tango? What can you speculate about the performance of BookKeeper versus TangoBookKeeper? Could you implement Tango using BookKeeper? How about transactions?
After reading the paper, I was kept with this question. What happens if the bookie writes the entry to its journal and acknowledges it, but dies before asynchronously writing this entry to its ledger? Does this cause any problems?
Final remarks
The paper does not talk about consistency of logging, because every consistency concern is exported to the ZooKeeper. I guess we can chalk this up as success points for ZooKeeper. BookKeeper's bottleneck for WAN deployment is ZooKeeper. If ZooKeeper is consulted infrequently things are OK. But if ZooKeeper is consulted frequently for LAC information in order to read from open ledgers, performance suffers.
Related links:
Flavio's blog post on BookKeeper
Flavio's presentation on BookKeeper
BookKeeper targets the logging problem. More specifically, the distributed logging problem where high-availability is important and where many distributed clients are interested in reading the logs.
Most current applications log to the local disk, but this constitutes a single point of failure (SPOF) and betrays high-availability. A hasty remedy is to write to an NFS partition to store log files remotely. But now the NFS server becomes the SPOF. (We can of course replicate the NSF server, but the performance would suffer.) Another solution is to use NetApp filers that implement RAID. This costs money, and still does not completely solve SPOF.
BookKeeper provides a no-SPOF efficient data store for serving a large number of concurrent single-writer, multiple-reader logs. It stripes log entries across servers, leading to higher throughput. BookKeeper is opensource and is used in production systems.
BookKeeper presents two case studies: Hedwig and HDFS Namenode. Hedwig is a scalable topic-based publish-subscribe system. To guarantee the delivery of messages despite partitions and server failures, Hedwig uses logging to persist published messages, which is implemented with BookKeeper. Hedwig is in production use and serves push notifications for Yahoo! properties (e.g., notifications for mobile devices).
The other use case concerns replicating the HDFS Namenode, the component of HDFS (Hadoop Distributed File System) that manages the file system metadata. On each update, the Namenode writes synchronously to a journal to guarantee that the update is durable. But unfortunately the Namenode is a SPOF. To enable efficient journaling and strong durability through replication, BookKeeper is used for implementing a journal manager for HDFS. The implementation is currently part of the HDFS codebase.
BookKeeper design and architecture
BookKeeper has 3 main components:- A bookie is a BookKeeper storage server, and each bookie stores ledger fragments. A ledger is written across f+1 bookies for fault-tolerance and striping.
- BookKeeper client is used for interacting with bookies.
- Ledger abstracts a log file. It is a sequence of entries identified by a sequence number (id).
BookKeeper assumes that there is only a single client writing to a ledger (clients can employ ZooKeeper coordination for this), and in return it guarantees that, once a ledger is closed, all other clients that read from it read the same sequence of entries.
Here is the happy path for BookKeeper. An application using BookKeeper initially designates a ledger writer. This ledger writer creates a ledger and appends data to the ledger; only the ledger writer is able to append entries to the ledger. Eventually, after appending an arbitrary number of entries to the ledger, the ledger writer closes it. Once the ledger is closed, its content is immutable. Clients can open closed ledgers for reading and any individual ledger can have multiple readers over time, and even concurrent readers.
The main calls in the API enable applications to:
- Create a ledger;
- Add entries to a ledger;
- Open a ledger for reading;
- Read entries from a ledger;
- Close a ledger to prevent further writes;
- Delete a ledger.
All these calls have both a synchronous and an asynchronous version.
When a client creates a ledger, it selects a set of bookies to form an ensemble for the ledger and stores the ensemble information as part of the ledger metadata on ZooKeeper. For each entry the ledger writer adds to the ledger, it replicates the entry across f+1 bookies. A request to add an entry e completes successfully if e has been successfully replicated across f+1 bookies. If a bookie crashes, then the client replaces that bookie. BookKeeper uses ZooKeeper to keep track of configuration changes for a ledger.
Closing a ledger.
When closing a ledger, the ledger writer writes to ZooKeeper the last entry that has been written successfully, as part of the ledger metadata. If a ledger writer crashes prematurely, before it closes its open ledger, a ledger reader would need to do ledger recovery.
Ledger recovery.
When a ledger reader opens a ledger for reading, it first obtains the ledger metadata. If it finds that it has not been closed by checking the state of the ledger, the ledger reader triggers a recovery procedure. The first step of recovery for a given ledger consists of having the reader client asking each bookie in the ensemble for the last add confirmed (LAC) field in the last entry that the bookie has processed for the ledger. Since reads are based on entry id, the recovery process can start reading from the highest LAC it receives, and thus it is not necessary to read the entire ledger.
Reading from an open ledger.
BookKeeper also enables clients to read from open ledgers. When clients need to read from an open ledger, they invoke a call to open the ledger that does not try to recover it if it is not closed. To avoid reading partially replicated entries from the ledger, which may not be in the ledger once it is closed, the client asks bookies for their LAC values. Reading entry i ≤ LAC is safe, since the ledger writer has marked it as successfully replicated.
Dealing with multiple ledgers
The ledger device stores ledger entries along with an index for each ledger. Bookie has a single file, called entry log, and interleaves entries of different ledgers by appending entries of all ledgers. For each ledger, Bookie also keeps in-memory an index mapping the entry identifier to its position in the entry log.
This design targets workloads dominated by writes, while not neglecting the performance of reads. Requests to add an entry to a ledger return as soon as the entry is flushed to the journal of a bookie, and writes to the ledger device are asynchronous and mostly sequential to enable the writes to this device to keep up with the writes to the journal device. To serve a read request, it is necessary to obtain the position of the entry in the entry log. If the index page is cached, then the read requires one disk seek.
BookKeeper stores metadata on ZooKeeper.
The ledger metadata includes the ensemble composition of ledgers, write quorum size, ledger status, the last entry successfully written to a closed ledger. For the metadata store, BookKeeper uses ZooKeeper. "A different, more scalable data store becomes necessary when the number of active ledgers is of the order of tens to hundreds of millions." For the availability of bookies, BookKeeper relies upon ZooKeeper because it provides ephemeral znodes and watches.
Evaluation
Experiments are conducted using a cluster of identical machines: 2 Quad Core Intel Xeon 2.5Ghz, 16GB of RAM, one 1 Gbit/s network interface, and four SATA drives of 1TB and rotational speed of 7200 RPM. Each machine in the cluster mounts an enterprise class filer via NFS (NetApp FAS3050). This hardware gives a raw performance of 1.2 milliseconds for the latency of add operations and 22.5k adds/sec for 1 kbyte entries when writing to a single bookie. nE-qQ denotes a ledger configuration with ensemble size n and write quorum q.Discussion
BookKeeper resembles chain replication a little. The chain replication approach is to export consensus to Paxos, and only store data providing high throughput. BookKeeper also does that, but chain replication is not referred to in the paper at all. Of course, chain replication lacks striping, and does not by default provide disjoint read replicas (in addition to write replicas) to improve read throughput.The Tango paper mentions BookKeeper and states that it has an implementation of BookKeeper in 300 lines. How would you implement BookKeeper in Tango? What can you speculate about the performance of BookKeeper versus TangoBookKeeper? Could you implement Tango using BookKeeper? How about transactions?
After reading the paper, I was kept with this question. What happens if the bookie writes the entry to its journal and acknowledges it, but dies before asynchronously writing this entry to its ledger? Does this cause any problems?
Final remarks
The paper does not talk about consistency of logging, because every consistency concern is exported to the ZooKeeper. I guess we can chalk this up as success points for ZooKeeper. BookKeeper's bottleneck for WAN deployment is ZooKeeper. If ZooKeeper is consulted infrequently things are OK. But if ZooKeeper is consulted frequently for LAC information in order to read from open ledgers, performance suffers.
Related links:
Flavio's blog post on BookKeeper
Flavio's presentation on BookKeeper





Comments