Naiad: A timely dataflow system
What is in a name?
Naiad is from Microsoft Research. Dryad, a general purpose runtime for execution of data parallel applications, was also from Microsoft Research. An application written for Dryad is modeled as a directed acyclic graph (DAG) and Dryad is the "tree nymph" in Greek mythology. Naiad is a stream processing platform and Naiad is the "stream nymph" in Greek mythology.Naiad is an opensource project that has been receiving a lot of attention recently. I expect we will hear more about Naiad, because it is very useful for low-latency real-time querying and high-throughput incremental-processing of streaming big data. What is not to like?
Naiad is useful especially in incremental processing of graphs. As has been observed before, MapReduce is inappropriate for graph processing because of the large number of iterations needed in graph applications. MapReduce is a functional language, so using MapReduce requires passing the entire state of the graph from one stage to the next, which is inefficient. And for real-time applications batch processing delays of MapReduce becomes unacceptable.
Dataflow graph
The developer supplies a a logical graph to Naiad to describe the dataflow of computation. (Don't confuse this with the large scale input graph that Naiad computes on). The edges in this graph show dataflow. The vertices are stateful computation stages.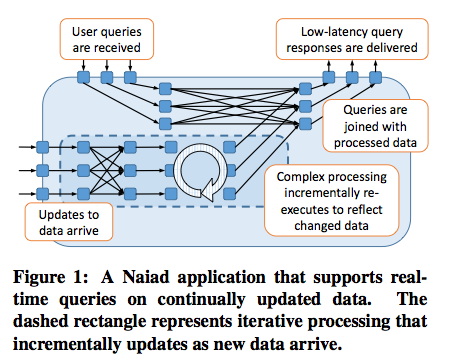
Figure 1 shows the overall architecture, with two main separate components: (1) incremental processing of incoming updates and (2) low-latency realtime querying of the application state. The query path is cleanly separated from the update path. Queries are done separately on a slightly stale version of the current application state. This way, the query path does not get blocked or incur delays due to the update processing. This also avoids complexity: If queries shared the same path with updates, the queries could be accessing partially-processed/incomplete/inconsistent states, and we would have to worry about how to prevent this.
With this architecture, Naiad is able to provide <100ms interactive query processing, <1s batch updates, and <1ms loop iterations.
(The separate query path is not a new idea. In big data processing, there is a batch layer that does occasional/periodic batch processing. This batch processing would output indexed state (new graph) and queries were performed over this output state in the serving layer in a read-only and quick manner.)
Loops in dataflow graph
The logical dataflow graph can have loops and even nested loops. (Note that, in contrast, a MapReduce computation dataflow does not have any loops, it is a chain of stages; at each stage you progress forward using output of previous stage and producing input for the next stage.)The loop concept in the dataflow graph is very useful as it enables new applications that may not be possible to compute with MapReduce like frameworks (at least in a reasonably efficient manner). Loops are natural way of dealing with iterative graph processing as in PageRank and machine learning applications.
Naiad even allows nested loops. But, as useful as they are, loops complicate the job of a stream processing system significantly. How do you keep track of when data is purged out, and that data doesn't keep looping in the system? How do you keep differentiate between older data looping in the system versus new data that is just entering the loop? To deal with these issues the paper introduces an epoch based timestamp to label data that is being processed. These timestamps make the model suitable for tracking global progress in iterative algorithms in a local manner. The progress tracking looks like a deep topic, the Naiad paper refers the readers to a separate 2013 paper for the full explanation of the progress tracking algorithm.
The paper calls the resulting model, the timely dataflow model. In sum, the timely dataflow model supports:
+ structured loops allowing feedback in the dataflow,
+ stateful data flow vertices capable of consuming and producing records without global coordination, and
+ notifications for vertices once they have received all records for a given round of input or loop iteration.
Naiad runtime

The logical dataflow graph, which denotes the stages of computation and the dataflow between these stages, is mapped on the physical worker machines in many-to-1 fashion. Each worker may host several stages of the dataflow graph. The workers are data nodes. They keep a portion of the input data (usually a large-scale input graph, such as Twitter follower graph) in memory. So it makes sense to move computation (dataflow graph stages) to the data (the partitioned input graph).
Writing programs with Naiad
A vertex (of the logical dataflow graph) may invoke two system-provided methods:this.SendBy(e : Edge, m : Message, t : Timestamp)
this.NotifyAt(t : Timestamp).
Each call to u.SendBy(e,m,t) results in a corresponding invocation of v.OnRecv(e,m,t), where e is an edge from u to v, and each call to v.NotifyAt(t) results in a corresponding invocation of v.OnNotify(t).
The OnRecv method may send elements on the first output as soon as they are first observed, allowing for low latency, but to ensure correctness the vertex must use OnNotify to delay sending a final synopsis until all inputs have been observed. In other words, SendBy and OnRecv are more suitable for streaming, and NotifyAt and OnNotify are more suitable for batching.
As such, Naiad provides tunable consistency. The developer can use loose-consistency operation like OnReceive or a strong consistency operation (that requires waiting) like OnNotify.
A prototypical Naiad program is given in the paper as follows.

Evaluation results
The paper has extensive evaluation results. Naiad was deployed on up to 64 computers and scalability results are shown for throughput, global barrier latency, progress tracking and speedup. PageRank (on Twitter follower graph), logistic regression (as an example of batch iterative machine learning) and k-Exposure algorithms (for Twitter topics) are used as examples.Discussion
A feedback first: It would have been very useful if the paper used different words for edges/vertices in logical dataflow graph versus those in the input graph that workers compute and modify. This gets very confusing at places. (See it even became confusing as I wrote the above.)The paper is 16 pages long, and packed with information. But several things remain unclear to me after reading.
How does Naiad do rate control? Within a loop at each epoch a larger neighborhood of a vertex may get affected/triggered (e.g., think of a PageRank like spreading application). How does this not cause an input avalanche? How does Naiad do rate control to send/initiate only as much as it can consume on the worker nodes?
It is not clear if we can implement tightly coordinated applications in Naiad. By tightly coordinated applications I mean applications that require multihop transactions on input graph, such as graph coloring and graph subcoloring.





Comments