RAMCloud reloaded: Log-structured Memory for DRAM-based Storage
I had written a review about "the case for RAMCloud" paper in 2010. RAMCloud advocates storing all the data in the RAM over distributed nodes in a datacenter. A RAMCloud is not a cache like memcached and data is not stored on an I/O device; DRAM is the permanent home for data. Obviously, storing everything in RAM could yield a very high-throughput (100-1000x) and very low-latency (100-1000x) system compared to disk-based systems.
In the last 3 years, the RAMCloud group headed by John Ousterhout at Stanford has done significant work on this project, and this is a good time to write another review on RAMCloud. My review mostly uses (shortened) text form their papers, and focuses on some of the significant ideas in their work.
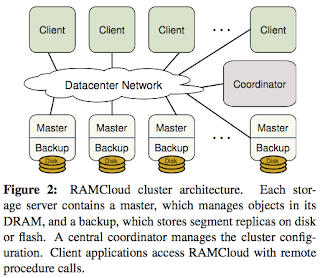
Data model. RAMCloud provides a simple key-value data model consisting of uninterpreted data blobs called objects. Objects are grouped into tables that may span one or more servers in the cluster; a subset of a table stored on a single server is called a tablet. Objects must be read or written in their entirety. RAMCloud is optimized for small objects --a few hundred bytes or less-- but supports objects up to 1 MB.
Each master's memory contains a hash table and a collection of objects stored in DRAM. The hash table contains one entry for each object stored on that master; it allows any object to be located quickly, given its table and key.
RAMCloud recovery. To ensure data durability against crashes and power failures, each master must keep backup copies of its objects on the secondary storage of other servers. The backup data is organized as a log for maximum efficiency. Each master has its own log, which is divided into 8 MB pieces called segments. Each segment is replicated on several backups (typically two or three). A master uses a different set of backups to replicate each segment, so that its segment replicas end up scattered across the entire cluster. E.g., this segment replicated at nodes 11 and 44, and the next segment at nodes 26 and 37.
When a master receives a write request from a client, it adds the new object to its memory and forwards information about that object to the backups. The backups append the new object to segment replicas stored in nonvolatile buffers; they respond to the master as soon as the object has been copied into their buffer, without issuing an I/O to secondary storage. Once the master has received replies from all the backups, it responds to the client. Each backup accumulates data in its buffer until the segment is complete, at which point it writes the segment to secondary storage and reallocates the buffer for another segment.
RAMCloud recovery is then possible by reading from the segments and constructing the hashtables at the masters. The paper describing this recovery process appeared in SOSP 2011.
RAMCloud log cleaner. RAMCloud uses a log cleaner to reclaim free space that accumulates in the logs when objects are deleted or over-written. Each master runs a separate cleaner. The cleaner selects several segments to clean (based on the amount of free space & age of data). The cleaner then scans these segments stored in memory and copies any live objects to new survivor segments. Liveness is determined by checking for a reference to the object in the hash table. The cleaner makes the old segments' memory available for new segments, and notifies the backups for those segments that they can reclaim the storage for the replicas.
In this post, we will look at the paper for the RAMCloud log cleaner, which has been published as a technical report and is under submission at SOSP'13.
GC comes with a trade-off: at some point all of these collectors (even those that label themselves as "incremental") must walk all live data, relocate it, and update references. This is an expensive operation that scales poorly, so GC delay global collections until a large amount of garbage has accumulated. As a result, they typically require 1.5-5x as much space as is actually used in order to maintain high performance. This erases any space savings gained by defragmenting memory.
Pause times are another concern with copying allocators with GC. At some point all collectors must halt the processes' threads to update references when objects are moved. Despite work on real-time garbage collectors, even state-of-art solutions have maximum pause times of hundreds of microseconds, or even milliseconds --this is 100 to 1,000 times longer than the round-trip time for a RAMCloud RPC.

In RAMCloud it was a natural choice to use a logging approach on disk to backup the data stored in main memory (given also that log-structured file-system (LSF) has been introduced by Ousterhout in 1991, it was inevitable actually :-). However, it was surprising to discover that logging also makes sense as a technique for managing the data in DRAM: Log-structured memory (LSM) takes advantage of /the restricted use of pointers/ in storage systems /to eliminate the global memory scans/ that fundamentally limit existing garbage collectors. The result is an efficient and highly incremental form of copying garbage collector that allows memory to be used efficiently even at utilizations of 80-90%.
RAMCloud uses a single log-based approach for managing both disk and main memory, with small policy differences that optimize the usage of each medium. Combining LSM and LSF, RAMCloud adopts a 2-level approach to cleaning with different policies for cleaning data in memory versus secondary storage. Since log data is immutable once appended, the log cleaner can run concurrently with normal read and write operations. Furthermore, multiple cleaners can run in separate threads. In the rest of this post, we will discuss each of these ideas: the LSM logs, 2-level cleaning, and parallel cleaning.
To reclaim free space, the log cleaner should copy live data out of the segments it chooses for cleaning. Unfortunately, the cost of log cleaning at the disk rises rapidly as memory utilization approaches 100%. E.g., if segments are cleaned when 80% of their data are still live, the cleaner must copy four bytes of live data for every byte it frees. If segments are cleaned at 90% utilization, the cleaner must copy 9 bytes of live data for every byte it frees.

The first level of cleaning, called segment compaction, operates only on the in-memory segments on masters. It compacts a single segment at a time, copying its live data into a smaller region of memory and freeing the original storage for new segments. Segment compaction maintains the same logical log in memory and on disk: each segment in memory still has a corresponding segment on disk. However, the segment in memory takes less space because deleted objects and obsolete tombstones have been removed.
The second level of cleaning is called combined cleaning. If the disk log is allowed to grow until it consumes twice as much space as the log in memory, the utilization of segments cleaned on disk will never be greater than 50%, which makes cleaning relatively efficient.
Segments and seglets. With compaction, however, segments in memory can have different sizes. Each RAMCloud master divides its memory into fixed-size 64KB seglets. A segment consists of a collection of seglets, and the number of seglets varies with the size of the segment. Segment compaction cannot reorganize data, since it must preserve the 1-to-1 mapping between segments in memory and those on disk. Combined cleaning is there to enable segment reorganization.

There are 3 points of contention between cleaner threads and service threads handling read and write requests: 1) both cleaner and service threads need to add data at the head of the log, 2) the threads may conflict in updates to the hash table, 3) the cleaner must not free segments that are still in use by service threads. We consider these 3 contention points next.
Head of log contention. The most obvious way to perform cleaning is to copy the live data to the head of the log, but this would create contention for the log head between cleaner threads and service threads that are writing new data. RAMCloud's solution is for the cleaner to write survivor data to different segments than the log head. Each cleaner thread allocates a separate set of segments for its survivor data. Synchronization is required when allocating segments, but once segments are allocated, each cleaner thread can copy data to its own survivor segments without additional synchronization.
Hash table contention. Hash table is used both by service threads and cleaner threads. The cleaner uses the hash table to check whether an object is alive (by seeing if the hash table currently points to that exact object). If the object is alive, the cleaner copies it and updates the hash table to refer to the new location in a survivor segment. To ensure consistency while reducing contention, RAMCloud currently uses fine-grained locks on individual hash table buckets. Although contention for these locks is low (only 0.1% under heavy write and cleaner load) it still means that the cleaner must acquire and release a lock for every object it scans, and read and write requests must also acquire an extra lock. Lockless solution is future work.
Freeing segments in memory. Once a cleaner thread has cleaned a segment, the segment's storage in memory can be freed for reuse. However, it is possible that a service thread had begun using the data in the segment before the cleaner updated the hash table; if so, the cleaner must not free the segment until the service thread has finished using it. A simple solution is to use a reader-writer lock for each segment, with service threads holding reader locks while using a segment and cleaner threads holding writer locks before freeing a segment. However, this would increase the latency of all read requests by adding another lock in the critical path.
Instead, RAMCloud uses a mechanism based on epochs, which avoids locking in service threads. The only additional overhead for service threads is to read a global epoch variable and store it with the RPC. When a cleaner thread finishes a cleaning pass, it increments the epoch and then tags each cleaned segment with the new epoch (after this point, no new request will use the cleaned segment). The cleaner occasionally scans the epochs of active RPCs and frees the segment when all RPCs with epochs less than the segment's epoch have completed. This approach creates additional overhead for segment freeing, but these operations are infrequent and run in a separate thread where they don't impact read and write times.

To recap, this work showed that logging also makes sense as a technique for managing the data in DRAM: Log-structured memory takes advantage of /the restricted use of pointers/ in storage systems /to eliminate the global memory scans/ that fundamentally limit existing garbage collectors. The result is an efficient and highly incremental form of copying garbage collector that allows memory to be used efficiently even at utilizations of 80-90%.
Questions for further thinking along these lines:
"Each object in the log must be self-identifying; when the log is scanned during crash recovery, this information allows RAMCloud to identify the most recent version of an object and reconstruct the hash table." Then, why not backup (copy reconstruct) the hash-table as well?
"Log-structured memory takes advantage of the restricted use of pointers in storage systems to eliminate the global memory scans that fundamentally limit existing garbage collectors." Can you think of similar "restricted use of pointers" approaches to enable log compaction and parallel cleaning?
LSM worked for storage systems. What other applications/use-cases would this be appropriate? What applications/use-cases would this be inappropriate?
In the last 3 years, the RAMCloud group headed by John Ousterhout at Stanford has done significant work on this project, and this is a good time to write another review on RAMCloud. My review mostly uses (shortened) text form their papers, and focuses on some of the significant ideas in their work.
State of the RAMCloud

Data model. RAMCloud provides a simple key-value data model consisting of uninterpreted data blobs called objects. Objects are grouped into tables that may span one or more servers in the cluster; a subset of a table stored on a single server is called a tablet. Objects must be read or written in their entirety. RAMCloud is optimized for small objects --a few hundred bytes or less-- but supports objects up to 1 MB.
Each master's memory contains a hash table and a collection of objects stored in DRAM. The hash table contains one entry for each object stored on that master; it allows any object to be located quickly, given its table and key.
RAMCloud recovery. To ensure data durability against crashes and power failures, each master must keep backup copies of its objects on the secondary storage of other servers. The backup data is organized as a log for maximum efficiency. Each master has its own log, which is divided into 8 MB pieces called segments. Each segment is replicated on several backups (typically two or three). A master uses a different set of backups to replicate each segment, so that its segment replicas end up scattered across the entire cluster. E.g., this segment replicated at nodes 11 and 44, and the next segment at nodes 26 and 37.
When a master receives a write request from a client, it adds the new object to its memory and forwards information about that object to the backups. The backups append the new object to segment replicas stored in nonvolatile buffers; they respond to the master as soon as the object has been copied into their buffer, without issuing an I/O to secondary storage. Once the master has received replies from all the backups, it responds to the client. Each backup accumulates data in its buffer until the segment is complete, at which point it writes the segment to secondary storage and reallocates the buffer for another segment.
RAMCloud recovery is then possible by reading from the segments and constructing the hashtables at the masters. The paper describing this recovery process appeared in SOSP 2011.
RAMCloud log cleaner. RAMCloud uses a log cleaner to reclaim free space that accumulates in the logs when objects are deleted or over-written. Each master runs a separate cleaner. The cleaner selects several segments to clean (based on the amount of free space & age of data). The cleaner then scans these segments stored in memory and copies any live objects to new survivor segments. Liveness is determined by checking for a reference to the object in the hash table. The cleaner makes the old segments' memory available for new segments, and notifies the backups for those segments that they can reclaim the storage for the replicas.
In this post, we will look at the paper for the RAMCloud log cleaner, which has been published as a technical report and is under submission at SOSP'13.
The problem with Memory allocation & Garbage collection
Memory allocators fall into two general classes: noncopying allocators and copying allocators. Non-copying allocators such as malloc cannot move an object once it has been allocated, so they are vulnerable to fragmentation. Non-copying allocators work well for individual applications with a consistent distribution of object sizes, but they can easily waste half of memory when allocation patterns change. Copying allocators are those that can move objects after they have been created. In principle, garbage collecting (GC) can solve the fragmentation problem by moving live data to coalesce free heap space.GC comes with a trade-off: at some point all of these collectors (even those that label themselves as "incremental") must walk all live data, relocate it, and update references. This is an expensive operation that scales poorly, so GC delay global collections until a large amount of garbage has accumulated. As a result, they typically require 1.5-5x as much space as is actually used in order to maintain high performance. This erases any space savings gained by defragmenting memory.
Pause times are another concern with copying allocators with GC. At some point all collectors must halt the processes' threads to update references when objects are moved. Despite work on real-time garbage collectors, even state-of-art solutions have maximum pause times of hundreds of microseconds, or even milliseconds --this is 100 to 1,000 times longer than the round-trip time for a RAMCloud RPC.

Log Structured Memory (LSM)
Existing allocators are not able to use memory efficiently, particularly in the face of changing access patterns, so are not applicable for RAMCloud. An ideal memory allocator for a DRAM-based storage system such as RAMCloud should have two properties: 1) It must be able to copy objects in order to eliminate fragmentation. 2) It must not require a global scan of memory: instead, it must be able to perform the copying incrementally, garbage collecting small regions of memory independently with cost proportional to the size of a region. This paper shows how to use a log-structured approach to memory management to achieve fragmentation-free and fast memory allocation.In RAMCloud it was a natural choice to use a logging approach on disk to backup the data stored in main memory (given also that log-structured file-system (LSF) has been introduced by Ousterhout in 1991, it was inevitable actually :-). However, it was surprising to discover that logging also makes sense as a technique for managing the data in DRAM: Log-structured memory (LSM) takes advantage of /the restricted use of pointers/ in storage systems /to eliminate the global memory scans/ that fundamentally limit existing garbage collectors. The result is an efficient and highly incremental form of copying garbage collector that allows memory to be used efficiently even at utilizations of 80-90%.
RAMCloud uses a single log-based approach for managing both disk and main memory, with small policy differences that optimize the usage of each medium. Combining LSM and LSF, RAMCloud adopts a 2-level approach to cleaning with different policies for cleaning data in memory versus secondary storage. Since log data is immutable once appended, the log cleaner can run concurrently with normal read and write operations. Furthermore, multiple cleaners can run in separate threads. In the rest of this post, we will discuss each of these ideas: the LSM logs, 2-level cleaning, and parallel cleaning.
Log metadata and log cleaning
Each new log segment contains a log digest that describes the entire log. Every segment has a unique identifier, allocated in ascending order within a log (see Fig 3 above). Each object in the log must be self-identifying: it contains the table identifier, key, and version number for the object in addition to its value. Log metadata also contains tombstones that identify deleted objects. When an object is deleted or modified, RAMCloud does not modify the object's existing record in the log. Instead, it appends a tombstone record to the log.To reclaim free space, the log cleaner should copy live data out of the segments it chooses for cleaning. Unfortunately, the cost of log cleaning at the disk rises rapidly as memory utilization approaches 100%. E.g., if segments are cleaned when 80% of their data are still live, the cleaner must copy four bytes of live data for every byte it frees. If segments are cleaned at 90% utilization, the cleaner must copy 9 bytes of live data for every byte it frees.

2-Level cleaning
In the original implementation of RAMCloud, disk and memory cleaning were tied together: cleaning in memory was mirrored to the backup copies on disk. This made it impossible to achieve both high memory utilization and high write throughput. The solution to this is to clean in-memory and on-disk logs independently: 2-level cleaning. This way, memory can have higher utilization than disk. The cleaning cost for memory will be high, but DRAM can easily provide the bandwidth required to clean at 90% utilization or higher. Disk cleaning happens less often. The disk log becomes larger than the in-memory log, so it has lower overall utilization (50%), and this reduces the bandwidth required for cleaning.The first level of cleaning, called segment compaction, operates only on the in-memory segments on masters. It compacts a single segment at a time, copying its live data into a smaller region of memory and freeing the original storage for new segments. Segment compaction maintains the same logical log in memory and on disk: each segment in memory still has a corresponding segment on disk. However, the segment in memory takes less space because deleted objects and obsolete tombstones have been removed.
The second level of cleaning is called combined cleaning. If the disk log is allowed to grow until it consumes twice as much space as the log in memory, the utilization of segments cleaned on disk will never be greater than 50%, which makes cleaning relatively efficient.
Segments and seglets. With compaction, however, segments in memory can have different sizes. Each RAMCloud master divides its memory into fixed-size 64KB seglets. A segment consists of a collection of seglets, and the number of seglets varies with the size of the segment. Segment compaction cannot reorganize data, since it must preserve the 1-to-1 mapping between segments in memory and those on disk. Combined cleaning is there to enable segment reorganization.

Parallel cleaning
Parallel cleaning in RAMCloud is greatly simplified by the use of a log structure and simple metadata: Since segments are immutable after they are created, the cleaner never needs to worry about objects being modified while the cleaner is copying them. This means that the basic cleaning mechanism is very straightforward: the cleaner copies live data to new segments, atomically updates references in the hash table, and frees the cleaned segments.There are 3 points of contention between cleaner threads and service threads handling read and write requests: 1) both cleaner and service threads need to add data at the head of the log, 2) the threads may conflict in updates to the hash table, 3) the cleaner must not free segments that are still in use by service threads. We consider these 3 contention points next.
Head of log contention. The most obvious way to perform cleaning is to copy the live data to the head of the log, but this would create contention for the log head between cleaner threads and service threads that are writing new data. RAMCloud's solution is for the cleaner to write survivor data to different segments than the log head. Each cleaner thread allocates a separate set of segments for its survivor data. Synchronization is required when allocating segments, but once segments are allocated, each cleaner thread can copy data to its own survivor segments without additional synchronization.
Hash table contention. Hash table is used both by service threads and cleaner threads. The cleaner uses the hash table to check whether an object is alive (by seeing if the hash table currently points to that exact object). If the object is alive, the cleaner copies it and updates the hash table to refer to the new location in a survivor segment. To ensure consistency while reducing contention, RAMCloud currently uses fine-grained locks on individual hash table buckets. Although contention for these locks is low (only 0.1% under heavy write and cleaner load) it still means that the cleaner must acquire and release a lock for every object it scans, and read and write requests must also acquire an extra lock. Lockless solution is future work.
Freeing segments in memory. Once a cleaner thread has cleaned a segment, the segment's storage in memory can be freed for reuse. However, it is possible that a service thread had begun using the data in the segment before the cleaner updated the hash table; if so, the cleaner must not free the segment until the service thread has finished using it. A simple solution is to use a reader-writer lock for each segment, with service threads holding reader locks while using a segment and cleaner threads holding writer locks before freeing a segment. However, this would increase the latency of all read requests by adding another lock in the critical path.
Instead, RAMCloud uses a mechanism based on epochs, which avoids locking in service threads. The only additional overhead for service threads is to read a global epoch variable and store it with the RPC. When a cleaner thread finishes a cleaning pass, it increments the epoch and then tags each cleaned segment with the new epoch (after this point, no new request will use the cleaned segment). The cleaner occasionally scans the epochs of active RPCs and frees the segment when all RPCs with epochs less than the segment's epoch have completed. This approach creates additional overhead for segment freeing, but these operations are infrequent and run in a separate thread where they don't impact read and write times.

Evaluation and concluding remarks
In the most stressful workload, a single RAMCloud server can support 230,000-400,000 durable 100-byte writes per second at 90% memory utilization. The two-level approach to cleaning improves performance by 2-8x over a single-level approach at high memory utilization, and reduces disk bandwidth overhead by 2-20x. Parallel cleaning effectively hides the cost of cleaning: an active cleaner adds only about 3% to the latency of typical client write requests. For detailed evaluation results, you can check the paper.To recap, this work showed that logging also makes sense as a technique for managing the data in DRAM: Log-structured memory takes advantage of /the restricted use of pointers/ in storage systems /to eliminate the global memory scans/ that fundamentally limit existing garbage collectors. The result is an efficient and highly incremental form of copying garbage collector that allows memory to be used efficiently even at utilizations of 80-90%.
Questions for further thinking along these lines:
"Each object in the log must be self-identifying; when the log is scanned during crash recovery, this information allows RAMCloud to identify the most recent version of an object and reconstruct the hash table." Then, why not backup (copy reconstruct) the hash-table as well?
"Log-structured memory takes advantage of the restricted use of pointers in storage systems to eliminate the global memory scans that fundamentally limit existing garbage collectors." Can you think of similar "restricted use of pointers" approaches to enable log compaction and parallel cleaning?
LSM worked for storage systems. What other applications/use-cases would this be appropriate? What applications/use-cases would this be inappropriate?






Comments
Ruby Badcoe