Sinfonia: A New Paradigm for Building Scalable Distributed Systems
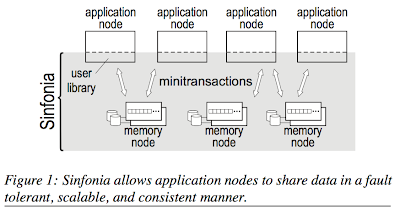
Sinfonia is an in-memory scalable service/infrastructure that aims to simplify the task of building scalable distributed systems. Sinfonia provides a lightweight "minitransaction" primitive that enables applications to atomically access and conditionally modify data at its multiple memory nodes. As the data model, Sinfonia provides a raw linear address space which is accessed directly by client libraries.
Minitransactions
In traditional transactions, a coordinator executes a transaction by asking participants to perform one or more participant-actions (such as retrieving or modifying data items), and at the end of the transaction, the coordinator decides and executes a two-phase commit. In the first phase, the coordinator asks all participants if they are ready to commit. If they all vote yes, in the second phase the coordinator tells them to commit; otherwise the coordinator tells them to abort.
Sinfonia introduces the concept of minitransactions, by making the observation that under certain restrictions/conditions on the transactions, it is possible to optimize the execution of a transaction such that the entire transaction is piggybacked onto just the two-phase commit protocol at the end. For example if the transactions participant-actions do not affect the coordinator's decision to abort or commit then the coordinator can piggyback these actions onto the first phase of the two-phase commit. Taking this a step further, even if a participant-action affects the coordinator's decision to abort or commit, if the participant knows how the coordinator makes this decision, then we can also piggyback the action onto the commit protocol. For example, if the last action is a read and the participant knows that the coordinator will abort if the read returns zero (and will commit otherwise), then the coordinator can piggyback this action onto two-phase commit and the participant can read the item and adjust its vote to abort if the result is zero.
Sinfonia designed its minitransactions so that it is always possible to piggyback the entire transaction execution onto the commit protocol. A minitransaction (Figure 2) consists of a set of compare items, a set of read items, and a set of write items. Items are chosen before the minitransaction starts executing. Upon execution, a minitransaction does the following: (1) compare the locations in the compare items, if any, against the data in the compare items (equality comparison), (2) if all comparisons succeed, or if there are no compare items, return the locations in the read items and write to the locations in the write items, and (3) if some comparison fails, abort. Thus, the compare items control whether the minitransaction commits or aborts, while the read and write items determine what data the minitransaction returns and updates.
To ensure serializability, participants lock the locations accessed by a minitransaction during phase 1 of the commit protocol. Locks are only held until phase 2 of the protocol, a short time. To avoid deadlocks, a participant tries to acquire locks without blocking; if it fails, it releases all locks and votes "abort due to busy lock" upon which the coordinator aborts the minitransaction and retries later. Figure 4 shows the execution and committing of a minitransaction. As a further optimization, if a minitransaction has just one participant, it can be executed in one phase because its outcome depends only on that participant. This case is exactly how key-value stores operate.
Fault-tolerance mechanisms
To provide fault tolerance, Sinfonia uses four mechanisms: disk images, logging, replication, and backup. A disk image keeps a copy of the data at a memory node. For efficiency, the disk image is written asynchronously and so may be slightly out-of-date. To compensate for that, a log keeps recent data updates, and the log is written synchronously to ensure data durability. When a memory node recovers from a crash, it uses a recovery algorithm to replay the log to catch up to its state before the crash. To provide high availability, Sinfonia uses primary-backup approach to replicate memory nodes, so that if a memory node fails, a replica takes over without downtime.
Minitransaction recovery protocols
Recall that in standard two-phase commit, if the coordinator crashes, the system has to block until the coordinator recovers. However, that approach is not suitable for Sinfonia. Recall that participants run on Sinfonia memory nodes whereas coordinators run on application nodes; so coordinators are unstable and very failure-prone. Running a three-phase commit protocol is expensive, and Sinfonia takes a different approach to deal with this issue.
Sinfonia modifies things a little so that instead of blocking on coordinator crashes, Sinfonia blocks on participant crashes. This is reasonable for Sinfonia because participants are memory nodes that keep application data, so if they go down and the application needs to access data, the application has to block anyway. Furthermore, Sinfonia can optionally replicate participants (memory nodes), to reduce such blocking to a minimum. This modification to block on a participant crash, however, complicates the protocols for recovery as we discuss next.
If a coordinator crashes during a minitransaction, it may leave the minitransaction with an uncertain outcome: one in which not all participants have voted yet. To fix this problem, Sinfonia employs a recovery coordinator, which runs at a dedicated management node. The recovery scheme ensures the following: (a) it will not drive the system into an unrecoverable state if the recovery coordinator crashes or if there are memory node crashes during recovery; (b) it ensures correctness even if there is concurrent execution of recovery with the original coordinator (this might happen if recovery starts but the original coordinator is still running); and (c) it allows concurrent execution by multiple recovery coordinators (this might happen if recovery restarts but a previous recovery coordinator is still running).
Concluding remarks
Sinfonia seems to work as promised and simplify the development of scalable distributed systems. The minitransaction primitive is expressive enough to build sophisticated coordination/cooperative algorithms. The authors demonstrate Sinfonia by using it to build two applications: a cluster file system called SinfoniaFS and a group communication service called SinfoniaGCS. Using Sinfonia, the authors built these complex services easily with 3900 and 3500 lines of code, in one and two man-months, respectively. This is not an easy feat.
I, personally, am a big fan of transactions. Transactions really do simplify distributed system development a lot. And transactions does not need to be heavyweight, and Sinfonia shows that by reducing the power of transactions to minitransactions, lightweight transaction execution can be achieved. In my work on wireless sensor networks (WSNs), I had also proposed a similar transactional primitive, Transact, to simplify to development of coordination and cooperation protocols. In Transact, in order to provide a lightweight implementation of transaction processing, we had exploited the inherent atomicity and snooping properties of singlehop wireless broadcast communication in WSNs.
Exercise questions
Recently a reader suggested that I post exercises with each summary, similar to what textbooks do. I decided to give this a try. So here it goes.
1) If we use Sinfonia to build a key-value store (only providing atomic write to single key-value records), what is the overhead of Sinfonia? How would it compare with other popular key-value stores?
2) Is Sinfonia suitable for WAN access, multi-datacenter distribution?

Minitransactions
In traditional transactions, a coordinator executes a transaction by asking participants to perform one or more participant-actions (such as retrieving or modifying data items), and at the end of the transaction, the coordinator decides and executes a two-phase commit. In the first phase, the coordinator asks all participants if they are ready to commit. If they all vote yes, in the second phase the coordinator tells them to commit; otherwise the coordinator tells them to abort.
Sinfonia introduces the concept of minitransactions, by making the observation that under certain restrictions/conditions on the transactions, it is possible to optimize the execution of a transaction such that the entire transaction is piggybacked onto just the two-phase commit protocol at the end. For example if the transactions participant-actions do not affect the coordinator's decision to abort or commit then the coordinator can piggyback these actions onto the first phase of the two-phase commit. Taking this a step further, even if a participant-action affects the coordinator's decision to abort or commit, if the participant knows how the coordinator makes this decision, then we can also piggyback the action onto the commit protocol. For example, if the last action is a read and the participant knows that the coordinator will abort if the read returns zero (and will commit otherwise), then the coordinator can piggyback this action onto two-phase commit and the participant can read the item and adjust its vote to abort if the result is zero.
Sinfonia designed its minitransactions so that it is always possible to piggyback the entire transaction execution onto the commit protocol. A minitransaction (Figure 2) consists of a set of compare items, a set of read items, and a set of write items. Items are chosen before the minitransaction starts executing. Upon execution, a minitransaction does the following: (1) compare the locations in the compare items, if any, against the data in the compare items (equality comparison), (2) if all comparisons succeed, or if there are no compare items, return the locations in the read items and write to the locations in the write items, and (3) if some comparison fails, abort. Thus, the compare items control whether the minitransaction commits or aborts, while the read and write items determine what data the minitransaction returns and updates.

To ensure serializability, participants lock the locations accessed by a minitransaction during phase 1 of the commit protocol. Locks are only held until phase 2 of the protocol, a short time. To avoid deadlocks, a participant tries to acquire locks without blocking; if it fails, it releases all locks and votes "abort due to busy lock" upon which the coordinator aborts the minitransaction and retries later. Figure 4 shows the execution and committing of a minitransaction. As a further optimization, if a minitransaction has just one participant, it can be executed in one phase because its outcome depends only on that participant. This case is exactly how key-value stores operate.

Fault-tolerance mechanisms
To provide fault tolerance, Sinfonia uses four mechanisms: disk images, logging, replication, and backup. A disk image keeps a copy of the data at a memory node. For efficiency, the disk image is written asynchronously and so may be slightly out-of-date. To compensate for that, a log keeps recent data updates, and the log is written synchronously to ensure data durability. When a memory node recovers from a crash, it uses a recovery algorithm to replay the log to catch up to its state before the crash. To provide high availability, Sinfonia uses primary-backup approach to replicate memory nodes, so that if a memory node fails, a replica takes over without downtime.
Minitransaction recovery protocols
Recall that in standard two-phase commit, if the coordinator crashes, the system has to block until the coordinator recovers. However, that approach is not suitable for Sinfonia. Recall that participants run on Sinfonia memory nodes whereas coordinators run on application nodes; so coordinators are unstable and very failure-prone. Running a three-phase commit protocol is expensive, and Sinfonia takes a different approach to deal with this issue.
Sinfonia modifies things a little so that instead of blocking on coordinator crashes, Sinfonia blocks on participant crashes. This is reasonable for Sinfonia because participants are memory nodes that keep application data, so if they go down and the application needs to access data, the application has to block anyway. Furthermore, Sinfonia can optionally replicate participants (memory nodes), to reduce such blocking to a minimum. This modification to block on a participant crash, however, complicates the protocols for recovery as we discuss next.
If a coordinator crashes during a minitransaction, it may leave the minitransaction with an uncertain outcome: one in which not all participants have voted yet. To fix this problem, Sinfonia employs a recovery coordinator, which runs at a dedicated management node. The recovery scheme ensures the following: (a) it will not drive the system into an unrecoverable state if the recovery coordinator crashes or if there are memory node crashes during recovery; (b) it ensures correctness even if there is concurrent execution of recovery with the original coordinator (this might happen if recovery starts but the original coordinator is still running); and (c) it allows concurrent execution by multiple recovery coordinators (this might happen if recovery restarts but a previous recovery coordinator is still running).
Concluding remarks
Sinfonia seems to work as promised and simplify the development of scalable distributed systems. The minitransaction primitive is expressive enough to build sophisticated coordination/cooperative algorithms. The authors demonstrate Sinfonia by using it to build two applications: a cluster file system called SinfoniaFS and a group communication service called SinfoniaGCS. Using Sinfonia, the authors built these complex services easily with 3900 and 3500 lines of code, in one and two man-months, respectively. This is not an easy feat.
I, personally, am a big fan of transactions. Transactions really do simplify distributed system development a lot. And transactions does not need to be heavyweight, and Sinfonia shows that by reducing the power of transactions to minitransactions, lightweight transaction execution can be achieved. In my work on wireless sensor networks (WSNs), I had also proposed a similar transactional primitive, Transact, to simplify to development of coordination and cooperation protocols. In Transact, in order to provide a lightweight implementation of transaction processing, we had exploited the inherent atomicity and snooping properties of singlehop wireless broadcast communication in WSNs.
Exercise questions
Recently a reader suggested that I post exercises with each summary, similar to what textbooks do. I decided to give this a try. So here it goes.
1) If we use Sinfonia to build a key-value store (only providing atomic write to single key-value records), what is the overhead of Sinfonia? How would it compare with other popular key-value stores?
2) Is Sinfonia suitable for WAN access, multi-datacenter distribution?
Comments