VL2: A Scalable and Flexible Data Center Network
This paper is by MS Research and appeared in Sigcomm 2009. The paper investigates data center networking, the same problem as the Portland paper (which also appeared in Sigcomm 2009!). Naturally there are similarities in the approaches recommended by the two papers.
The motivation for this paper is from a slightly different angle than the Portland paper. This paper puts more emphasis on the network capacity problem in the data centers. The paper argues that the network is the bottleneck of the computation, since the switches at the higher levels (i.e., aggregation and core switches) are oversubscribed heavily. Servers typically have 1:1 over-subscription to other servers in the same rack --that is, they can communicate at the full rate of their interfaces (e.g., 1 Gbps). However, up-links from top of the rack (ToR) switches are typically 1:20 oversubscribed (i.e., 1 Gbps of up-link for 20 servers), and paths through the highest layer of the tree can be 1:240 oversubscribed.
The paper focuses on the question of providing uniform high capacity for any server to server communication such that traffic flow should be limited only by the available capacity on the network-interface cards of the sending and receiving servers. However, that is only half of the story. In addition to removing the network bottleneck from computation, the data centers must achieve high utilization in order to be profitable. The key to high utilization is the property of agility--the capacity to assign any server to any service. Without agility, each service must pre-allocate enough servers to meet difficult to predict demand spikes, or risk failure at the brink of success. With agility, the data center operator can meet the fluctuating demands of individual services from a large shared server pool, resulting in higher server utilization and lower costs. In order to achieve agility, assigning servers to a service should be independent of network topology.
Scale-out Clos topology and Valiant load balancing
To answer the uniform high capacity problem, the paper proposes a Clos topology as in Figure 5. This topology provides a tree that is "fatter" than the fat tree used in the Portland paper.
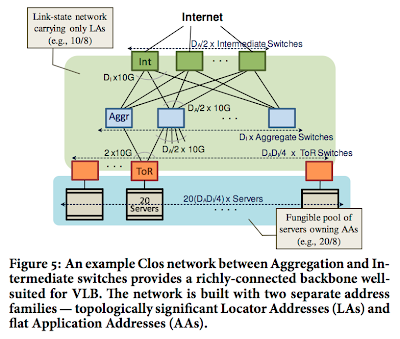 However, providing a very fat tree alone is not sufficient to solve the network bottleneck problems; we also need to ensure that traffic is allocated across these multiple available paths appropriately so that one path does not choke down with lots of traffic and reduce the effective rate of communication for the servers communicating over that path. The question is how to achieve such an allocation? Are there any patterns in the data center traffic that will enable us to partition the multiple paths in an optimal way among the servers?
However, providing a very fat tree alone is not sufficient to solve the network bottleneck problems; we also need to ensure that traffic is allocated across these multiple available paths appropriately so that one path does not choke down with lots of traffic and reduce the effective rate of communication for the servers communicating over that path. The question is how to achieve such an allocation? Are there any patterns in the data center traffic that will enable us to partition the multiple paths in an optimal way among the servers?
To answer these questions the paper provides extensive experiments and analysis of data center traffic. The analysis found that 90% of flows are small-size (mice), but still 95% of bytes are in big-size flows (elephants). The analysis also show a lot of volatility (unpredictability) in traffic. The variability in datacenter traffic is not amenable to concise summarization and hence engineering routes for just a few traffic matrices is unlikely to work well for the traffic encountered in practice. Armed with these analysis results, the paper proposes to use valiant load balancing (vlb) to randomize end-to-end communication paths to cope with volatility and achieve load balancing. In this scheme, the ToR switch randomly chooses an intermediate switch (among many available options) on a per flow basis.
The paper also provides extensive experiments on network equipment failure characteristics---this was sorely missing in Google's globally available storage paper. The analysis of network failures found that most failures are small in size (e.g., 50% of network device failures involve < 4 devices and 95% of network device failures involve < 20 devices) and large correlated failures are rare (e.g., the largest correlated failure involved 217 switches). Still, downtimes can be significant, and with no obvious way to eliminate all failures from the top of the hierarchy, this paper's approach is to broaden (fatten) the topmost levels of the network so that the impact of failures is muted and performance degrades gracefully.
Virtual layer 2 networking
To answer the agility problem, the paper proposes VL2, which stands for Virtual Layer 2 as far as I can make out --the acronym is not defined in the paper. The key idea of VL2 is separating names from locators. VL2 assigns servers IP addresses that act as names alone, with no topological significance. When a server sends a packet, the shim-layer (a layer 2.5 if you will) on the server invokes a directory system to learn the actual location of the destination and then tunnels the original packet there. The shim-layer also helps eliminate the scalability problems created by ARP in layer-2 networks.
 The separation of location-specific IP addresses (LAs) and application-specific IP addresses (AAs) was chosen for two reasons. First, this makes it possible to use low-cost switches, which often have small routing tables that can hold only LA route intervals, without concern for the huge number of AAs. Second, this reduces overhead in the network control plane by preventing it from seeing the churn in host state (change in AAs), tasking it instead to the more scalable directory system (which we discuss below). As such, the network infrastructure operates using LAs; all switches and interfaces are assigned LAs, and switches run an IP-based (layer-3) link-state routing protocol that disseminates only these LAs (end-host information AAs are not disseminated). This allows switches to obtain the complete switch-level topology, as well as forward packets encapsulated with LAs along shortest paths using standard proven network protocols such as OSPF. On the other hand, applications use AAs, which remain unaltered no matter how servers' locations change due to virtual-machine migration or re-provisioning.
The separation of location-specific IP addresses (LAs) and application-specific IP addresses (AAs) was chosen for two reasons. First, this makes it possible to use low-cost switches, which often have small routing tables that can hold only LA route intervals, without concern for the huge number of AAs. Second, this reduces overhead in the network control plane by preventing it from seeing the churn in host state (change in AAs), tasking it instead to the more scalable directory system (which we discuss below). As such, the network infrastructure operates using LAs; all switches and interfaces are assigned LAs, and switches run an IP-based (layer-3) link-state routing protocol that disseminates only these LAs (end-host information AAs are not disseminated). This allows switches to obtain the complete switch-level topology, as well as forward packets encapsulated with LAs along shortest paths using standard proven network protocols such as OSPF. On the other hand, applications use AAs, which remain unaltered no matter how servers' locations change due to virtual-machine migration or re-provisioning.
To route traffic between servers, which use AA addresses, on an underlying network that knows routes for LA addresses, the VL2 agent at each server traps packets from the host and encapsulates the packet with the LA address of the ToR of the destination as shown in Figure 6. Once the packet arrives at the LA (the destination ToR), the switch decapsulates the packet and delivers it to the destination AA carried in the inner header.
The crux of offering layer-2 semantics via VL2 is having servers believe they share a single large IP subnet (i.e., the entire AA space), while eliminating the ARP and DHCP scaling bottlenecks that plague large Ethernets. From the cloud service programmer's point of view VL2 *efficiently* provides the abstraction that all the servers assigned to the programmer are plugged in to the same LAN--where any IP address can be connected to any port of an Ethernet switch due to flat addressing.
Directory lookup
The VL2 directory system stores the mapping of AAs to LAs. VL2 uses end-system based address resolution to scale to large server pools, without introducing complexity to the network control plane. When an application sends a packet to an AA for the first time, the networking stack on the host generates a broadcast ARP request for the destination AA. The VL2 agent running on the host intercepts this ARP request and converts it to a unicast query to the VL2 directory system. The directory system answers the query with the LA of the ToR to which packets should be tunneled. The VL2 agent caches this mapping from AA to LA addresses, similar to a host's ARP cache, such that subsequent communication need not entail a directory lookup.
 The directory system design consists of a modest number (50-100 servers for 100K servers) of read-optimized, replicated directory servers that cache AA-to-LA mappings to handle queries from VL2 agents, and a small number (5-10 servers) of write-optimized, asynchronous replicated state machine (RSM) servers that offer a strongly consistent, reliable store of AA-to-LA mappings. In other words, the directory lookups are handled using read optimized servers, which are just caches of the write optimized Paxos-running RSMs that hold persistent state.
The directory system design consists of a modest number (50-100 servers for 100K servers) of read-optimized, replicated directory servers that cache AA-to-LA mappings to handle queries from VL2 agents, and a small number (5-10 servers) of write-optimized, asynchronous replicated state machine (RSM) servers that offer a strongly consistent, reliable store of AA-to-LA mappings. In other words, the directory lookups are handled using read optimized servers, which are just caches of the write optimized Paxos-running RSMs that hold persistent state.
To achieve high availability and low latency, an agent sends a lookup to k randomly-chosen directory servers, and uses the first answer it receives back. The network provisioning system sends directory updates to a randomly-chosen directory server, which then forwards the update to a RSM server. VL2 does not require the use of a fabric manager proposed in Portland, instead the directory system serves the IP-to-LA mapping. While the fabric manager is a single machine and centralized solution, the directory service provides a decentralized solution.
Evaluation
The evaluation results shows that VL2 provides an effective substrate for a scalable data center network; VL2 achieves (1) 94% optimal network capacity, (2) a TCP fairness index of 0.995, (3) graceful degradation under failures with fast reconvergence, and (4) 50K lookups/sec under 10ms for fast address resolution.
The Clos network topology pays off, as the goodput is more than 10x of what the network in current data centers can achieve with the same investment. Another striking result is that comparing the cost of a VL2 network for 35K servers with a traditional data center network shows that a VL2 network with no over-subscription can be built for the same cost as the traditional network that has 1:240 over-subscription.
Conclusions
This is a very well written, definitive paper on data center networking. The paper illustrates the challenges in data center networking via extensive analysis, and offers a simple design that can be realized today with available networking technologies, re-utilizing time-tested/proven network protocols, and avoiding changes to switch control and data plane capabilities. This is a must-read for anyone interested in the data center networking topic.
The motivation for this paper is from a slightly different angle than the Portland paper. This paper puts more emphasis on the network capacity problem in the data centers. The paper argues that the network is the bottleneck of the computation, since the switches at the higher levels (i.e., aggregation and core switches) are oversubscribed heavily. Servers typically have 1:1 over-subscription to other servers in the same rack --that is, they can communicate at the full rate of their interfaces (e.g., 1 Gbps). However, up-links from top of the rack (ToR) switches are typically 1:20 oversubscribed (i.e., 1 Gbps of up-link for 20 servers), and paths through the highest layer of the tree can be 1:240 oversubscribed.
The paper focuses on the question of providing uniform high capacity for any server to server communication such that traffic flow should be limited only by the available capacity on the network-interface cards of the sending and receiving servers. However, that is only half of the story. In addition to removing the network bottleneck from computation, the data centers must achieve high utilization in order to be profitable. The key to high utilization is the property of agility--the capacity to assign any server to any service. Without agility, each service must pre-allocate enough servers to meet difficult to predict demand spikes, or risk failure at the brink of success. With agility, the data center operator can meet the fluctuating demands of individual services from a large shared server pool, resulting in higher server utilization and lower costs. In order to achieve agility, assigning servers to a service should be independent of network topology.
Scale-out Clos topology and Valiant load balancing
To answer the uniform high capacity problem, the paper proposes a Clos topology as in Figure 5. This topology provides a tree that is "fatter" than the fat tree used in the Portland paper.
 However, providing a very fat tree alone is not sufficient to solve the network bottleneck problems; we also need to ensure that traffic is allocated across these multiple available paths appropriately so that one path does not choke down with lots of traffic and reduce the effective rate of communication for the servers communicating over that path. The question is how to achieve such an allocation? Are there any patterns in the data center traffic that will enable us to partition the multiple paths in an optimal way among the servers?
However, providing a very fat tree alone is not sufficient to solve the network bottleneck problems; we also need to ensure that traffic is allocated across these multiple available paths appropriately so that one path does not choke down with lots of traffic and reduce the effective rate of communication for the servers communicating over that path. The question is how to achieve such an allocation? Are there any patterns in the data center traffic that will enable us to partition the multiple paths in an optimal way among the servers?To answer these questions the paper provides extensive experiments and analysis of data center traffic. The analysis found that 90% of flows are small-size (mice), but still 95% of bytes are in big-size flows (elephants). The analysis also show a lot of volatility (unpredictability) in traffic. The variability in datacenter traffic is not amenable to concise summarization and hence engineering routes for just a few traffic matrices is unlikely to work well for the traffic encountered in practice. Armed with these analysis results, the paper proposes to use valiant load balancing (vlb) to randomize end-to-end communication paths to cope with volatility and achieve load balancing. In this scheme, the ToR switch randomly chooses an intermediate switch (among many available options) on a per flow basis.
The paper also provides extensive experiments on network equipment failure characteristics---this was sorely missing in Google's globally available storage paper. The analysis of network failures found that most failures are small in size (e.g., 50% of network device failures involve < 4 devices and 95% of network device failures involve < 20 devices) and large correlated failures are rare (e.g., the largest correlated failure involved 217 switches). Still, downtimes can be significant, and with no obvious way to eliminate all failures from the top of the hierarchy, this paper's approach is to broaden (fatten) the topmost levels of the network so that the impact of failures is muted and performance degrades gracefully.
Virtual layer 2 networking
To answer the agility problem, the paper proposes VL2, which stands for Virtual Layer 2 as far as I can make out --the acronym is not defined in the paper. The key idea of VL2 is separating names from locators. VL2 assigns servers IP addresses that act as names alone, with no topological significance. When a server sends a packet, the shim-layer (a layer 2.5 if you will) on the server invokes a directory system to learn the actual location of the destination and then tunnels the original packet there. The shim-layer also helps eliminate the scalability problems created by ARP in layer-2 networks.
 The separation of location-specific IP addresses (LAs) and application-specific IP addresses (AAs) was chosen for two reasons. First, this makes it possible to use low-cost switches, which often have small routing tables that can hold only LA route intervals, without concern for the huge number of AAs. Second, this reduces overhead in the network control plane by preventing it from seeing the churn in host state (change in AAs), tasking it instead to the more scalable directory system (which we discuss below). As such, the network infrastructure operates using LAs; all switches and interfaces are assigned LAs, and switches run an IP-based (layer-3) link-state routing protocol that disseminates only these LAs (end-host information AAs are not disseminated). This allows switches to obtain the complete switch-level topology, as well as forward packets encapsulated with LAs along shortest paths using standard proven network protocols such as OSPF. On the other hand, applications use AAs, which remain unaltered no matter how servers' locations change due to virtual-machine migration or re-provisioning.
The separation of location-specific IP addresses (LAs) and application-specific IP addresses (AAs) was chosen for two reasons. First, this makes it possible to use low-cost switches, which often have small routing tables that can hold only LA route intervals, without concern for the huge number of AAs. Second, this reduces overhead in the network control plane by preventing it from seeing the churn in host state (change in AAs), tasking it instead to the more scalable directory system (which we discuss below). As such, the network infrastructure operates using LAs; all switches and interfaces are assigned LAs, and switches run an IP-based (layer-3) link-state routing protocol that disseminates only these LAs (end-host information AAs are not disseminated). This allows switches to obtain the complete switch-level topology, as well as forward packets encapsulated with LAs along shortest paths using standard proven network protocols such as OSPF. On the other hand, applications use AAs, which remain unaltered no matter how servers' locations change due to virtual-machine migration or re-provisioning.To route traffic between servers, which use AA addresses, on an underlying network that knows routes for LA addresses, the VL2 agent at each server traps packets from the host and encapsulates the packet with the LA address of the ToR of the destination as shown in Figure 6. Once the packet arrives at the LA (the destination ToR), the switch decapsulates the packet and delivers it to the destination AA carried in the inner header.
The crux of offering layer-2 semantics via VL2 is having servers believe they share a single large IP subnet (i.e., the entire AA space), while eliminating the ARP and DHCP scaling bottlenecks that plague large Ethernets. From the cloud service programmer's point of view VL2 *efficiently* provides the abstraction that all the servers assigned to the programmer are plugged in to the same LAN--where any IP address can be connected to any port of an Ethernet switch due to flat addressing.
Directory lookup
The VL2 directory system stores the mapping of AAs to LAs. VL2 uses end-system based address resolution to scale to large server pools, without introducing complexity to the network control plane. When an application sends a packet to an AA for the first time, the networking stack on the host generates a broadcast ARP request for the destination AA. The VL2 agent running on the host intercepts this ARP request and converts it to a unicast query to the VL2 directory system. The directory system answers the query with the LA of the ToR to which packets should be tunneled. The VL2 agent caches this mapping from AA to LA addresses, similar to a host's ARP cache, such that subsequent communication need not entail a directory lookup.
 The directory system design consists of a modest number (50-100 servers for 100K servers) of read-optimized, replicated directory servers that cache AA-to-LA mappings to handle queries from VL2 agents, and a small number (5-10 servers) of write-optimized, asynchronous replicated state machine (RSM) servers that offer a strongly consistent, reliable store of AA-to-LA mappings. In other words, the directory lookups are handled using read optimized servers, which are just caches of the write optimized Paxos-running RSMs that hold persistent state.
The directory system design consists of a modest number (50-100 servers for 100K servers) of read-optimized, replicated directory servers that cache AA-to-LA mappings to handle queries from VL2 agents, and a small number (5-10 servers) of write-optimized, asynchronous replicated state machine (RSM) servers that offer a strongly consistent, reliable store of AA-to-LA mappings. In other words, the directory lookups are handled using read optimized servers, which are just caches of the write optimized Paxos-running RSMs that hold persistent state.To achieve high availability and low latency, an agent sends a lookup to k randomly-chosen directory servers, and uses the first answer it receives back. The network provisioning system sends directory updates to a randomly-chosen directory server, which then forwards the update to a RSM server. VL2 does not require the use of a fabric manager proposed in Portland, instead the directory system serves the IP-to-LA mapping. While the fabric manager is a single machine and centralized solution, the directory service provides a decentralized solution.
Evaluation
The evaluation results shows that VL2 provides an effective substrate for a scalable data center network; VL2 achieves (1) 94% optimal network capacity, (2) a TCP fairness index of 0.995, (3) graceful degradation under failures with fast reconvergence, and (4) 50K lookups/sec under 10ms for fast address resolution.
The Clos network topology pays off, as the goodput is more than 10x of what the network in current data centers can achieve with the same investment. Another striking result is that comparing the cost of a VL2 network for 35K servers with a traditional data center network shows that a VL2 network with no over-subscription can be built for the same cost as the traditional network that has 1:240 over-subscription.
Conclusions
This is a very well written, definitive paper on data center networking. The paper illustrates the challenges in data center networking via extensive analysis, and offers a simple design that can be realized today with available networking technologies, re-utilizing time-tested/proven network protocols, and avoiding changes to switch control and data plane capabilities. This is a must-read for anyone interested in the data center networking topic.






Comments
BTW, James Hamilton who is one of the authors wrote a blog article about VL2 - http://perspectives.mvdirona.com/2009/10/05/VL2AScalableAndFlexibleDataCenterNetwork.aspx