Speculative Execution in a Distributed File System
This SOSP'05 paper is about optimization techniques for client server distributed computing model, especially focusing on distributed file systems. In distributed filesystems, providing strong cash-consistency among concurrently editing clients require several synchronization messages to be exhanged between the clients and the server. Network delays, especially in wide area networks, make this unfeasibly slow.
In fact AFS and NFS sacrifice consistency guarantees for speed, and provide weaker consistency guarantees such as close-to-open consistency where a client that opens the file see modifications by clients that have previously closed the file. Even these weaker consistency guarantees require synchronizing with the server and introduce latencies.
Can distributed file systems be safe, consistent, yet fast? The paper states that it is possible to achieve this by using operating system support for lightweight checkpointing and speculative execution.
The idea is simple. The main reason for latency is that, traditionaly, when a client contacts server with request, the client blocks till it gets a reply. To avoid blocking, the paper proposes to use speculation. In this approach, the client contacts the server with a request, client checkpoints & speculatively continues execution using its guess for the result of the communication. When the server replies, if the client's guess was right, the client saves time. Otherwise, the client restores state back to checkpoint and continues from there. So no savings over traditional is achieved when the guess is wrong.
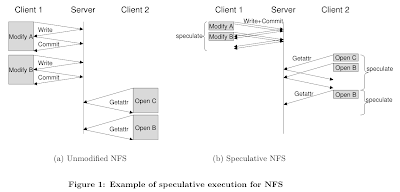
Of course this approach works best when 1. operations are highly predictable, 2. checkpointing is cheaper than network I/O, and 3. computers have resources to spare. All these conditions appear to hold in today's computer systems. Especially, with the advent of multicore processors it is possible to concurrently try multiple guesses while speculating. Condition 2 can be a suspect in LANs with less than 1ms roundtrip times, though. (The paper mentions that the checkpointing time for a 64mb process is about 6ms. Maybe checkpointing can be done faster, and also as the paper mentions, many speculations can share the same checkpoint and amortize costs)
The challenge is how to manage speculative executions so that it does not contaminate other non-speculative processes and cause system wide rollbacks. The speculator (the name of the system the authors build) does not allow a process that is executing speculatively to externalize output until that speculation is proven correct. Note that Speculator does not block read-only calls or calls that modify only task state. Despite blocking external output, dependencies between processes introduced by other indirect paths. For ensuring correct execution without side-effects, Speculator tracks these dependencies passed through fork, exit, signals, pipes, fifos, Unix sockets, and files in local and distributed file systems. All other forms of IPC currently block the speculative process until the speculations on which it depends are resolved. The good news is that since speculation is implemented entirely in the operating system, no application modification is required.
In the evaluation section, results from PostMark and Andrew-style benchmarks show that Speculator improves the performance of NFS by more than a factor of 2 over local-area networks; over net-works with 30ms of round-trip latency, speculation makes NFS more than 14 times faster. To recap from the introduction again, speculation improves file system performance because it hides latency: multiple file system operations can be performed concurrently, and computation can be overlapped with I/O.
This speculation approach is used for different systems including
byzantine fault-tolerant system for replicated state machine in "Tolerating Latency in Replicated State Machines Through Client Speculation" NSDI 2009.
In fact AFS and NFS sacrifice consistency guarantees for speed, and provide weaker consistency guarantees such as close-to-open consistency where a client that opens the file see modifications by clients that have previously closed the file. Even these weaker consistency guarantees require synchronizing with the server and introduce latencies.
Can distributed file systems be safe, consistent, yet fast? The paper states that it is possible to achieve this by using operating system support for lightweight checkpointing and speculative execution.
The idea is simple. The main reason for latency is that, traditionaly, when a client contacts server with request, the client blocks till it gets a reply. To avoid blocking, the paper proposes to use speculation. In this approach, the client contacts the server with a request, client checkpoints & speculatively continues execution using its guess for the result of the communication. When the server replies, if the client's guess was right, the client saves time. Otherwise, the client restores state back to checkpoint and continues from there. So no savings over traditional is achieved when the guess is wrong.

Of course this approach works best when 1. operations are highly predictable, 2. checkpointing is cheaper than network I/O, and 3. computers have resources to spare. All these conditions appear to hold in today's computer systems. Especially, with the advent of multicore processors it is possible to concurrently try multiple guesses while speculating. Condition 2 can be a suspect in LANs with less than 1ms roundtrip times, though. (The paper mentions that the checkpointing time for a 64mb process is about 6ms. Maybe checkpointing can be done faster, and also as the paper mentions, many speculations can share the same checkpoint and amortize costs)
The challenge is how to manage speculative executions so that it does not contaminate other non-speculative processes and cause system wide rollbacks. The speculator (the name of the system the authors build) does not allow a process that is executing speculatively to externalize output until that speculation is proven correct. Note that Speculator does not block read-only calls or calls that modify only task state. Despite blocking external output, dependencies between processes introduced by other indirect paths. For ensuring correct execution without side-effects, Speculator tracks these dependencies passed through fork, exit, signals, pipes, fifos, Unix sockets, and files in local and distributed file systems. All other forms of IPC currently block the speculative process until the speculations on which it depends are resolved. The good news is that since speculation is implemented entirely in the operating system, no application modification is required.
In the evaluation section, results from PostMark and Andrew-style benchmarks show that Speculator improves the performance of NFS by more than a factor of 2 over local-area networks; over net-works with 30ms of round-trip latency, speculation makes NFS more than 14 times faster. To recap from the introduction again, speculation improves file system performance because it hides latency: multiple file system operations can be performed concurrently, and computation can be overlapped with I/O.
This speculation approach is used for different systems including
byzantine fault-tolerant system for replicated state machine in "Tolerating Latency in Replicated State Machines Through Client Speculation" NSDI 2009.







Comments