Megastore: Providing scalable, highly available storage for interactive services
Google's Megastore is the structured data store supporting the Google Application Engine. Megastore handles more than 3 billion write and 20 billion read transactions daily and stores a petabyte of primary data across many global datacenters.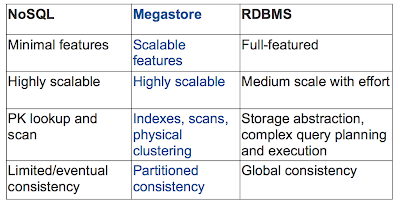 Megastore tries to provide the convenience of using traditional RDBMS with the scalability of NOSQL: It is a scalable transactional indexed record manager (built on top of BigTable), providing full ACID semantics within partitions but lower consistency guarantees across partitions (aka, entity groups in Figure 1). To achieve these strict consistency requirements, Megastore employs a Paxos-based algorithm for synchronous replication across geographically distributed datacenters.
Megastore tries to provide the convenience of using traditional RDBMS with the scalability of NOSQL: It is a scalable transactional indexed record manager (built on top of BigTable), providing full ACID semantics within partitions but lower consistency guarantees across partitions (aka, entity groups in Figure 1). To achieve these strict consistency requirements, Megastore employs a Paxos-based algorithm for synchronous replication across geographically distributed datacenters. 
I have some problems with Megastore, but I save them to the end of the review to explain Megastore first.
Paxos
Megastore uses Paxos, a proven, optimal, fault-tolerant consensus algorithm with no requirement for a distinguished master. (Paxos is hard to cover in a blog post, as I mentioned earlier, so I will not attempt to.) The reason Paxos got much more popular than other consensus protocols (such as 2-phase and 3-phase commit) is that Paxos satisfies safety properties of consensus even under asynchrony and arbitrary message loss. This does not conflict with the coordinated attack and FLP impossibility results. Those impossibility results said that you can't achieve consensus (both safety and liveness at the same time), they did not say you have to sacrifice safety under message-losses or asynchrony conditions. So Paxos preserves safety under all conditions and achieves liveness when conditions improve outside the impossibility realm (less message losses, some timing assumptions start to hold).
Basic Paxos is a 2-phase protocol. In the prepare phase the leader replica tries to get the other nonleader replicas recognize it as the leader for that consensus instance. In the accept phase the leader tries to get the nonleader replicas accept the vote it proposes. So basic Paxos requires at least two round trips, and that is very inefficient for WAN usage. Fortunately, there has been several Paxos variants to optimize the performance. One optimization is MultiPaxos, which permits single-roundtrip writes by basically piggybacking the prepare phase of the upcoming consensus instance onto the accept phase of the current consensus instance.
Another optimization is for optimizing the cost of reads. In basic Paxos, a read operation also needs to go through the two phase protocol involving all the replicas (or at least a majority of them) to be serialized and served. The read optimization enables serving reads locally but only at the leader replica. When a nonleader replica gets a read request, it has to forward it to the leader to be served locally there. The read optimization was made possible by having the leader impose a lease on being a leader at other replicas (during which the replicas cannot accept another leader's prepare phase). Thanks to the lease the leader is guaranteed to be the leader until the lease expires, and is guaranteed to have the most up-to-date view of the system and can serve the read locally. The nice thing about the MultiPaxos and local-read-at-the-leader optimizations are that they did not modify any guarantees of Paxos; safety is preserved under all conditions, and progress is satisfied when the conditions are sufficient for making progress.
Megastore's use of PaxosMegastore uses Paxos (with the MultiPaxos extension) in a pretty standard way to replicate a write-ahead log over a group of symmetric peers. Megastore runs an independent instance of the Paxos algorithm for each log position. The leader for each log position is a distinguished replica chosen alongside the preceding log position's consensus value. (This is the MultiPaxos optimization I discussed above.) The leader arbitrates which value may use proposal number zero. The first writer to submit a value to the leader wins the right to ask all replicas to accept that value as proposal number zero. All other writers must fall back on two-phase Paxos. Since a writer must communicate with the leader before submitting the value to other replicas, the system minimizes writer-leader latency. The policy for selecting the next write's leader is designed around the observation that most applications submit writes from the same region repeatedly. This leads to a simple but effective heuristic: use the closest replica.
However, in addition to the straightforward MultiPaxos optimization above, Megastore also introduces a surprising new extension to allow local reads at any up-to-date replica. This came as a big surprise to me because the best anyone could do before was to allow local-reads-at-the-leader. What was it that we were missing? I didn't get how this was possible the first time I read the paper; I only got it in my second look at the paper.
Coordinator, the rabbit pulled out of the hatMegastore uses a service called the Coordinator, with servers in each replica's datacenter. A coordinator server tracks a set of entity groups (i.e., partitions mentioned in the first paragraph) for which its replica has observed all Paxos writes. For entity groups in that set, the replica is deemed to have sufficient state to serve local reads. If the coordinator claims that it is up to date, then the corresponding replica can serve a read for that entity group locally, else the other replicas (and a couple network roundtrips) need to be involved.
But how does the coordinator know whether it is up to date or not? The paper states that it is the responsibility of the write algorithm to keep coordinator state conservative. If a write fails on a replica's Bigtable, it cannot be considered committed until the group's key has been evicted from that replica's coordinator. What does this mean? This means that write operations are penalized to improve the performance of read operations. In MegastorePaxos, before a write is considered committed and ready to apply, all full replicas must have accepted or had their coordinator invalidated for that entity group. In contrast, in Paxos a write could be committed with only a majority of replicas accepting the write.
Performance problemsUsing synchronous replication over WAN of course takes its toll on the performance. This has been noticed and discussed here.
Of course, there is also the performance degradation due to waiting for an acknowledgement (or time out) from all replicas for a write operation. This also leads to a write availability problem. The paper tries to defend that this is not a big problem in practice as follows, but it is evident that partitions/failures result in write unavailability until they are recovered from.
"In the write algorithm above, each full replica must either accept or have its coordinator invalidated, so it might appear that any single replica failure (Bigtable and coordinator) will cause unavailability. In practice this is not a common problem. The coordinator is a simple process with no external dependencies and no persistent storage, so it tends to be much more stable than a Bigtable server. Nevertheless, network and host failures can still make the coordinator unavailable.
This algorithm risks a brief (tens of seconds) write outage when a datacenter containing live coordinators suddenly becomes unavailable--all writers must wait for the coordinator's Chubby locks to expire before writes can complete (much like waiting for a master failover to trigger). Unlike after a master failover, reads and writes can proceed smoothly while the coordinator's state is reconstructed. This brief and rare outage risk is more than justified by the steady state of fast local reads it allows."
In the abstract, the paper had claimed Megastore achieves both consistency and availability, and this was a red flag for me, as we all know that something has to give due to CAP theorem. And above we have seen that write availability suffers in the presence of a partition.
 Megastore tries to provide the convenience of using traditional RDBMS with the scalability of NOSQL: It is a scalable transactional indexed record manager (built on top of BigTable), providing full ACID semantics within partitions but lower consistency guarantees across partitions (aka, entity groups in Figure 1). To achieve these strict consistency requirements, Megastore employs a Paxos-based algorithm for synchronous replication across geographically distributed datacenters.
Megastore tries to provide the convenience of using traditional RDBMS with the scalability of NOSQL: It is a scalable transactional indexed record manager (built on top of BigTable), providing full ACID semantics within partitions but lower consistency guarantees across partitions (aka, entity groups in Figure 1). To achieve these strict consistency requirements, Megastore employs a Paxos-based algorithm for synchronous replication across geographically distributed datacenters. 
I have some problems with Megastore, but I save them to the end of the review to explain Megastore first.
Paxos
Megastore uses Paxos, a proven, optimal, fault-tolerant consensus algorithm with no requirement for a distinguished master. (Paxos is hard to cover in a blog post, as I mentioned earlier, so I will not attempt to.) The reason Paxos got much more popular than other consensus protocols (such as 2-phase and 3-phase commit) is that Paxos satisfies safety properties of consensus even under asynchrony and arbitrary message loss. This does not conflict with the coordinated attack and FLP impossibility results. Those impossibility results said that you can't achieve consensus (both safety and liveness at the same time), they did not say you have to sacrifice safety under message-losses or asynchrony conditions. So Paxos preserves safety under all conditions and achieves liveness when conditions improve outside the impossibility realm (less message losses, some timing assumptions start to hold).
Basic Paxos is a 2-phase protocol. In the prepare phase the leader replica tries to get the other nonleader replicas recognize it as the leader for that consensus instance. In the accept phase the leader tries to get the nonleader replicas accept the vote it proposes. So basic Paxos requires at least two round trips, and that is very inefficient for WAN usage. Fortunately, there has been several Paxos variants to optimize the performance. One optimization is MultiPaxos, which permits single-roundtrip writes by basically piggybacking the prepare phase of the upcoming consensus instance onto the accept phase of the current consensus instance.
Another optimization is for optimizing the cost of reads. In basic Paxos, a read operation also needs to go through the two phase protocol involving all the replicas (or at least a majority of them) to be serialized and served. The read optimization enables serving reads locally but only at the leader replica. When a nonleader replica gets a read request, it has to forward it to the leader to be served locally there. The read optimization was made possible by having the leader impose a lease on being a leader at other replicas (during which the replicas cannot accept another leader's prepare phase). Thanks to the lease the leader is guaranteed to be the leader until the lease expires, and is guaranteed to have the most up-to-date view of the system and can serve the read locally. The nice thing about the MultiPaxos and local-read-at-the-leader optimizations are that they did not modify any guarantees of Paxos; safety is preserved under all conditions, and progress is satisfied when the conditions are sufficient for making progress.
Megastore's use of PaxosMegastore uses Paxos (with the MultiPaxos extension) in a pretty standard way to replicate a write-ahead log over a group of symmetric peers. Megastore runs an independent instance of the Paxos algorithm for each log position. The leader for each log position is a distinguished replica chosen alongside the preceding log position's consensus value. (This is the MultiPaxos optimization I discussed above.) The leader arbitrates which value may use proposal number zero. The first writer to submit a value to the leader wins the right to ask all replicas to accept that value as proposal number zero. All other writers must fall back on two-phase Paxos. Since a writer must communicate with the leader before submitting the value to other replicas, the system minimizes writer-leader latency. The policy for selecting the next write's leader is designed around the observation that most applications submit writes from the same region repeatedly. This leads to a simple but effective heuristic: use the closest replica.
However, in addition to the straightforward MultiPaxos optimization above, Megastore also introduces a surprising new extension to allow local reads at any up-to-date replica. This came as a big surprise to me because the best anyone could do before was to allow local-reads-at-the-leader. What was it that we were missing? I didn't get how this was possible the first time I read the paper; I only got it in my second look at the paper.
Coordinator, the rabbit pulled out of the hatMegastore uses a service called the Coordinator, with servers in each replica's datacenter. A coordinator server tracks a set of entity groups (i.e., partitions mentioned in the first paragraph) for which its replica has observed all Paxos writes. For entity groups in that set, the replica is deemed to have sufficient state to serve local reads. If the coordinator claims that it is up to date, then the corresponding replica can serve a read for that entity group locally, else the other replicas (and a couple network roundtrips) need to be involved.

But how does the coordinator know whether it is up to date or not? The paper states that it is the responsibility of the write algorithm to keep coordinator state conservative. If a write fails on a replica's Bigtable, it cannot be considered committed until the group's key has been evicted from that replica's coordinator. What does this mean? This means that write operations are penalized to improve the performance of read operations. In MegastorePaxos, before a write is considered committed and ready to apply, all full replicas must have accepted or had their coordinator invalidated for that entity group. In contrast, in Paxos a write could be committed with only a majority of replicas accepting the write.
Performance problemsUsing synchronous replication over WAN of course takes its toll on the performance. This has been noticed and discussed here.
Of course, there is also the performance degradation due to waiting for an acknowledgement (or time out) from all replicas for a write operation. This also leads to a write availability problem. The paper tries to defend that this is not a big problem in practice as follows, but it is evident that partitions/failures result in write unavailability until they are recovered from.
"In the write algorithm above, each full replica must either accept or have its coordinator invalidated, so it might appear that any single replica failure (Bigtable and coordinator) will cause unavailability. In practice this is not a common problem. The coordinator is a simple process with no external dependencies and no persistent storage, so it tends to be much more stable than a Bigtable server. Nevertheless, network and host failures can still make the coordinator unavailable.
This algorithm risks a brief (tens of seconds) write outage when a datacenter containing live coordinators suddenly becomes unavailable--all writers must wait for the coordinator's Chubby locks to expire before writes can complete (much like waiting for a master failover to trigger). Unlike after a master failover, reads and writes can proceed smoothly while the coordinator's state is reconstructed. This brief and rare outage risk is more than justified by the steady state of fast local reads it allows."
In the abstract, the paper had claimed Megastore achieves both consistency and availability, and this was a red flag for me, as we all know that something has to give due to CAP theorem. And above we have seen that write availability suffers in the presence of a partition.
Exercise question
Additional linkshttp://muratbuffalo.blogspot.com/2010/10/mencius-building-efficient-replicated.html
http://perspectives.mvdirona.com/2011/01/09/GoogleMegastoreTheDataEngineBehindGAE.aspxhttp://perspectives.mvdirona.com/2008/07/10/GoogleMegastore.aspxhttp://glinden.blogspot.com/2011/02/comparing-google-megastore.htmlhttp://highscalability.com/blog/2011/1/11/google-megastore-3-billion-writes-and-20-billion-read-transa.html
Megastore has a limit of "a few writes per second per entity group" because higher write rates will cause even worse performance due to the conflicts and retries of the multiple leaders (aka dueling leaders). Is it possible to adopt the partitioning consensus sequence numbers technique in "Mencius: building efficient replicated state machines for Wide-Area-Networks (WANs)" to alleviate this problem?
Additional linkshttp://muratbuffalo.blogspot.com/2010/10/mencius-building-efficient-replicated.html
http://perspectives.mvdirona.com/2011/01/09/GoogleMegastoreTheDataEngineBehindGAE.aspxhttp://perspectives.mvdirona.com/2008/07/10/GoogleMegastore.aspxhttp://glinden.blogspot.com/2011/02/comparing-google-megastore.htmlhttp://highscalability.com/blog/2011/1/11/google-megastore-3-billion-writes-and-20-billion-read-transa.html




Comments