Modular Composition of Coordination Services
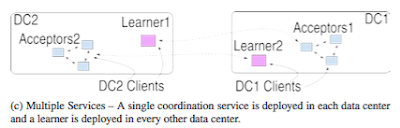
This paper appeared in Usenix ATC'16 last week. The paper considers the problem of scaling ZooKeeper to WAN deployments. ( Check this earlier post for a brief review of ZooKeeper. ) The paper suggests a client-side only modification to ZooKeeper, and calls the resultant system ZooNet. ZooNet consists of a federation of ZooKeeper cluster at each datacenter/region. ZooNet assumes the workload is highly-partitionable, so the data is partitioned among the ZooKeeper clusters, each accompanied by learners in the remote datacenter/regions. Each ZooKeeper cluster processes only updates for its own data partition and if applications in different regions need to access unrelated items they can also do so independently and in parallel at their own site. However, the problem with such a deployment is that it does not preserve ZooKeeper's sequential execution semantics. Consider the example in Figure 1. (It is not clear to me why the so-called "loosely-coupled" application








