Socrates: The New SQL Server in the Cloud (Sigmod 2019)
This paper (Sigmod 2019) presents Socrates, the database-as-a-service (DBaaS) architecture of the Azure SQL DB Hyperscale.
Deploying a DBaaS in the cloud requires an architecture that is cost-effective yet performant. An idea that works well is to decompose/disaggregate the functionality of a database into two as compute services (e.g., transaction processing) and storage services (e.g., checkpointing and recovery). The first commercial system that adopted this idea is Amazon Aurora.
The Socrates design adopts the separation of compute from storage as it has been proven useful. In addition, Socrates separates database log from storage and treats the log as a first-class citizen. Separating the log and storage tiers disentangles durability (implemented by the log) and availability (implemented by the storage tier). This separation yields significant benefits:
- in contrast to availability, durability does not require copies in fast storage,
- in contrast to durability, availability does not require a fixed number of replicas.
HADR, the predecessor
Before Socrates, SQL DB was based on an architecture called HADR, a classic example of a log- replicated state machine. There is a Primary node which processes all update transactions and ships the update logs to all Secondary nodes. Secondary nodes may process read-only transactions. If the Primary fails, one of the Secondaries becomes the new Primary. The Primary periodically backups data to Azure’s Standard Storage Service (called XStore): log is backed up every five minutes, a delta of the whole database once a day, and a full backup every week. With HADR, SQL DB needs four nodes (one Primary and three Secondaries) to guarantee high availability and durability: If all four nodes fail, there is data loss because the log is backed up only every five minutes.
HADR had high performance because every compute node has a full, local copy of the database. On the negative side, the size of a database cannot grow beyond the storage capacity of a single machine. O(size-of-data) operations also create issues. For instance, the cost of seeding a new node is linear with the size of the database. Backup/restore, scale-up and down are further examples of operations whose cost grows linearly with the size of the database. This is why the size of HADR databases are limited to 4TB.
Socrates Architecture Overview
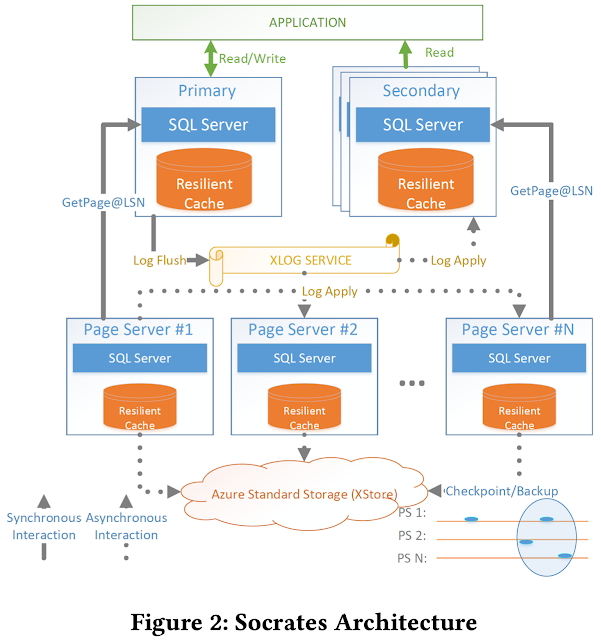
Figure 2 shows the Socrates architecture. The architecture has four tiers.
Tier1 is Compute. There is one Primary Compute node which handles all read/write transactions. There can be any number of Secondaries which handle read-only transactions or serve as failover targets. The Compute nodes implement query optimization, concurrency control, and security. All Compute nodes cache data pages in main memory and on SSD in a resilient buffer pool extension (RBPEX).
(Aside: Resilient Buffer Pool Extension. In 2012, SQL Server released a feature called buffer pool extension (BPE) which spills the content of the in-memory database buffer pool to a local SSD file. Socrates extended this concept and made the buffer pool resilient; i.e., recoverable after a failure. This RBPEX concept serves as the caching mechanism for pages both in the compute and the storage tiers. RBPEX is built as a table in Hekaton, MS's in-memory storage engine. Having a recoverable cache like RBPEX significantly reduces the mean-time-to-recovery until a node reaches peak performance with warm buffers: If the failure is short, it is much cheaper to read and apply the log records of the few updated pages than to refetch all cached pages from a remote server.)
The second tier is the XLOG service. This tier implements the “separation of log” principle. The XLOG service achieves low commit latencies and good scalability at the storage tier. Since the Primary processes all updates, only the Primary writes to the log. This single writer approach guarantees low latency and high throughput when writing to the log. All other nodes (e.g., Secondaries) consume the log in an asynchronous way to keep their copies of data up to date.
(Aside: Low Log Latency, Separation of Log. Socrates makes the log durable and fault-tolerant by replicating the log: A transaction can commit as soon as its log records have been made durable. Socrates exploits the asymmetry of log access: Recently created log records are in high demand whereas old log records are only needed in exceptional cases, e.g., to abort and undo a long-running transaction. Therefore, Socrates keeps recent log records in main memory and distributes them in a scalable way potentially to hundreds of machines whereas old log records are destaged and made available only upon demand.)
The third tier is the storage tier. It is implemented by Page Servers. Each Page Server has a copy of a partition of the database. Page Servers play two important roles: First, they serve pages to Compute nodes. Every Compute node can request pages from a Page Server, following a shared-disk architecture. As of 2019, the team was working on implementing bulk operations such as bulk loading, index creation, DB reorgs, deep page repair, and table scans in Page Servers to further offload Compute nodes. In their second role, Page Servers checkpoint data pages and create backups in XStore (the fourth tier). Like Compute nodes, Page Servers keep all their data in main memory or locally attached SSDs for fast access.
(Aside: From Shared-nothing to Shared-disk. Disaggrated storage approach is similar to shared-disk idea, as any node can access all data. This has significant benefits, it can help for jitter, availability, and fault-tolerance, as discussed in the Decoupled Transactions paper, and FoundationDB. In this design, all database compute nodes which execute transactions and queries have access to the same remote storage service. The combination of a shared version store and accelerated recovery makes it possible for new compute nodes to spin up quickly and to push the boundaries of read scale-out in Socrates well beyond what is possible in HADR. The configured partition size for a Page Server is 128GB. So, a Socrates database with hundreds of TB will result in a deployment with thousands of Page Servers.)
The fourth tier is the Azure Storage Service (called XStore), the existing storage service provided by Azure independently of Socrates and SQL DB. XStore is a highly scalable, durable, and cheap storage service based on hard disks. Data access is remote and there are throughput and latency limits.
To recap, Compute nodes and Page Servers are stateless. They can fail at any time without data loss. The “truth” of the database is stored in XStore and XLOG. XStore is highly reliable and has been used by virtually all Azure customers for many years without data loss. Socrates leverages this robustness. XLOG is a new service built specifically for Socrates. It has high performance requirements, must be scalable, affordable, and must never lose any data.
XLOG Service

The Primary writes log blocks synchronously and directly to the LZ for lowest possible commit latency. The LZ is meant to be fast (possibly expensive) but small. The LZ is organized as a circular buffer.
The Primary also writes all log blocks to a special XLOG process which disseminates the log blocks to Page Servers and Secondaries. These writes are asynchronous and possibly unreliable (in fire-and-forget style) using a lossy protocol. One way to think about this scheme is that Socrates writes synchronously and reliably into the LZ for durability and asynchronously to the XLOG process for availability.
This unsynchronized approach of writing two places can lead to inconsistencies and data loss in the presence of failures. To avoid these situations, XLOG only disseminates hardened log blocks. Hardened blocks are blocks which have already been made durable (with write quorum) in the LZ. To this end, the Primary writes all log blocks first into the “pending area” of the XLOG process. Furthermore, the Primary informs XLOG of all hardened log block.
To disseminate and archive log blocks, the XLOG process implements a storage hierarchy. Once a block is moved into the LogBroker, an internal XLOG process called destaging moves the log to a fixed size local SSD cache for fast access and to XStore for long term retention. Again, XStore is cheap, abundant, durable, yet slow. If not specified otherwise, SQL DB keeps log records for 30 days for point-in-time recovery and disaster recovery with fuzzy backups.
Consumers (Secondaries, Page Servers) pull log blocks from the XLOG service. This way, the architecture is more scalable as the LogBroker need not keep track of log consumers, possibly hundreds of Page Servers.
Primary Compute Node and GetPage@LSN
The Socrates Primary makes use of the RBPEX cache. The primary does not keep a full copy of the database. It merely caches a hot portion of the database that fits into its main memory buffers and SSD (RBPEX).
This requires a mechanism for the Primary to retrieve pages which are not cached in the local node. We call this mechanism GetPage@LSN. The GetPage@LSN mechanism is a remote procedure call with the following signature: getPage(pageId, LSN). Here, pageId identifies uniquely the page that the Primary needs to read, and LSN identifies a page log sequence number with a value at least as high as the last PageLSN of the page. The Page Server returns a version of the page that has applied all updates up to this LSN or higher. This simple protocol is all that is needed to make sure that the Page Server does not return a stale version of a Page to the Primary.
The Socrates Secondary processes read-only transactions (using Snapshot Isolation).
Page Servers
A Page Server is responsible for (i) maintaining a partition of the database by applying log to it, (ii) responding to Get-Page@LSN requests from Compute nodes and (iii) performing distributed checkpoints and taking backups.
Serving GetPage@LSN requests is also straightforward. To this end, Page Servers also use RBPEX, the SSD-extended, recoverable cache. The mechanisms to use RBPEX are the same for Page Servers as for Compute nodes, but the policy is different. Compute nodes cache the hottest pages for best performance; their caches are sparse. In contrast, Page Servers cache less hot pages, those pages that are not hot enough to make it in the Compute node’s cache. That is why SQL DB Hyperscale currently implements Page Servers using a covering cache; i.e., all pages of the partition are stored in the Page Server’s RBPEX.
Furthermore, Socrates organizes a Page Server’s RBPEX in a stride-preserving layout such that a single I/O request from a compute node that covers a multi-page range translates into a single I/O request at the Page Server. Since the Page Server’s cache is dense, the Pager Server does not suffer from read amplification while the sparse RBPEX caches at Compute nodes do. This characteristic is important for the performance of scan operations that commonly read up to 128 pages.
Another important characteristic of the Page Server cache is that it provides insulation from transient XStore failures. On an XStore outage, the Page Server continues operating in a mode where pages that were written in RBPEX but not in XStore are remembered and checkpointing is resumed (and XStore is caught up) when XStore is back online.
XStore for Durability and Backup/Restore
The truth of the database is stored in XStore. XStore is cheap (based on hard disks), durable (virtually no data loss due to a high degree of replication across availability zones), and provides efficient backup and restore by using a log-structured design (taking a backup merely requires keeping a pointer into the log). But XStore is slow. XStore plays in Socrates the same role as hard disks and tape in a traditional database system. The main-memory and SSD caches (RBPEX) of Compute nodes and Page Servers play in Socrates the same role as main memory in a traditional system.
For checkpointing, a Page Server regularly ships modified pages to XStore. Backups are implemented using XStore’s snapshot feature which allows to create a backup in constant time by simply recording a timestamp. When a user requests a Point-In-Time-Restore operation (PITR), the restore workflow identifies (i) the complete set of snapshots that have been taken just before the time of the PITR, and (ii) the log range required to bring this set of snapshots from their time to the requested time. These snapshots are then copied to new blobs and a restore operation starts in which each blob is attached to a new Page Server instance, a new XLOG process is bootstrapped on the copied log blobs and the log applied to bring the database all the way to the PITR requested time.
Performance Experiments And Results
The experiments used the CDB benchmark which is Microsoft’s Cloud Database Benchmark (also known as the DTU benchmark). CDB defines a set of transaction types covering a wide range of operations from simple point lookups to complex bulk updates.
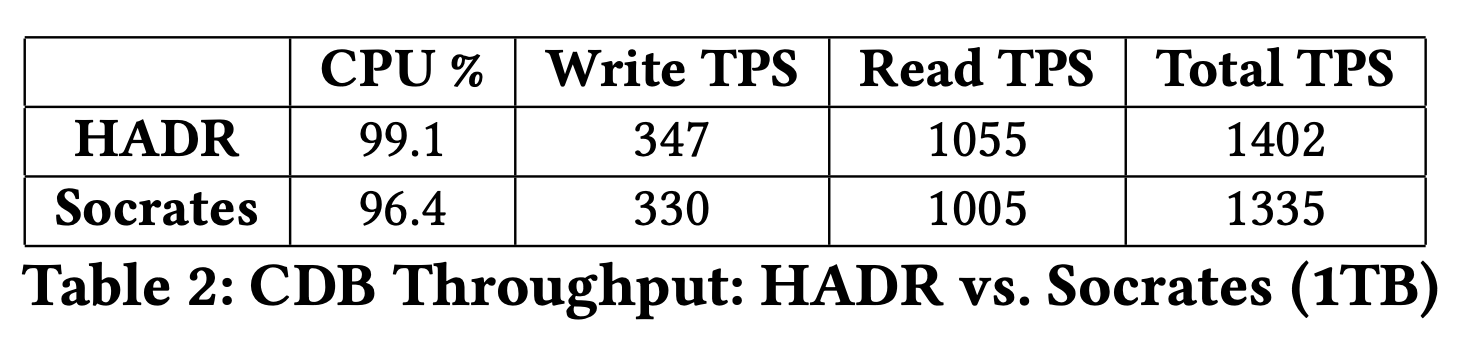
Socrates throughput comes about 5% lower than the throughput of HADR. This result is not unexpected for a service in preview, especially considering that HADR has been tuned over the years for this benchmark. It is interesting to understand how Socrates loses this 5%. HADR achieves 99.1% CPU utilization which is almost perfect. Socrates has a lower CPU utilization as it needs to wait longer for remote I/Os. This lower CPU utilization explains half of the deficit. From performance profiles, it seems that the other 2.5% performance gap come from a higher CPU cost of writing the log to a remote service (XLOG).
For the following experiments in the Test cluster, they used VMs with 64 cores, 432 GB of main memory, and 32 disks.

Table 3 shows the cache hit rate of Socrates for a 1TB CDB database and an RBPEX with 56GB of main memory buffers, and 168 GB of SSD storage space. For this experiment, the default workloa mix of CDB is used, which randomly touches pages scattered across the entire database. Thus, this workload is a bad case for caching. Nevertheless, we achieve a 50% hit rate for a cache that is only 15% of the size of the database.
They also ran Socrates on a 30TB TPC-E database using the TPC-E benchmark. For this experiment, they increased the buffer pool of the Socrates Primary (88 GB of main memory and 320 GB of SSD). Table 4 shows that even though the cache is only about 1% of the size of the database, Socrates had a 32% hit rate.

Why is Socrates better in this experiment? HADR needs to drive log and database backup from the Compute nodes in parallel with the user workload. Log production is restricted to the level at which the log backup egress can be safely handled by the Azure Storage tier (XStore) underneath. In contrast, Socrates can leverage XStore’s snapshot feature for backup which results in a much higher log production rate upstream at the Socrates Primary.




Comments