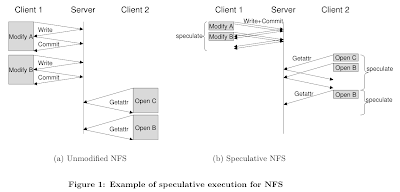
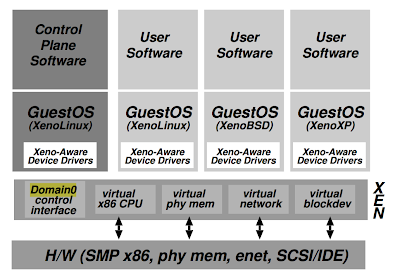
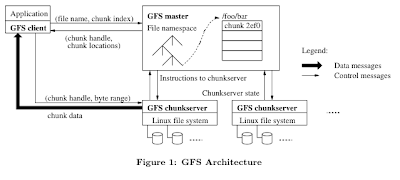
Paxos taught
In my previous posts I have alluded a couple of times to how I teach Paxos. Here I will explain how I go about teaching Paxos. These are the slides I use in class. (In my slides I reuse a lot of material from the lecture slides of Jeff Chase (Duke) . He shared his slides with me under the Creative Commons license, where I get to remix/change the contents with proper credit to him.) Paxos is a protocol for solving distributed consensus. The problem is easy to state. Consensus requires the following three properties. The first two are safety properties, the last one is a liveness property. Agreement: No two process can commit different decisions. Validity (Non-triviality): If all initial values are same, nodes must commit that value. Termination: Nodes commit eventually. I first start with a discussion of impossibility results in consensus. A major impossibility result is the coordinated attack (aka two generals) paradox . The result states that there is no determi...