Building fault-tolerant applications on AWS
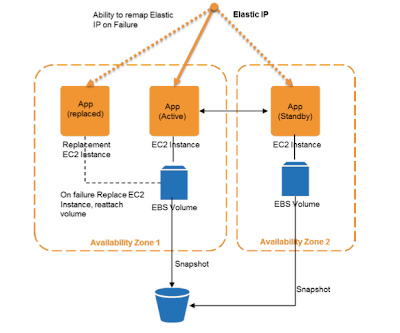
Below is my summary of the Amazon Web Services (AWS) whitepaper released on Oct 2011 by Jeff Barr, Attila Narin, and Jinesh Varia. AWS aims to simplify the task of building and maintaining fault-tolerant distributed systems/services for its customers. For this, AWS prescribes the customers to embrace the following philosophy when they are building their applications on AWS. 1. Make computing nodes disposable/easily replaceable AWS (as with any cloud provider actually) employs a level of indirection over the physical computer, called virtual machine (VM), to make computing nodes easily replaceable. You then need a template to define your service instance over a VM, and this is called Amazon Machine Image (AMI). The first step towards building fault-tolerant applications on AWS is to create your own AMIs. Starting your application then is simply a matter of launching VM instances on Amazon Elastic Compute Cloud (EC2) using your AMI. Once you have created an AMI, replacing a faili...




