Setting up a new Mac laptop
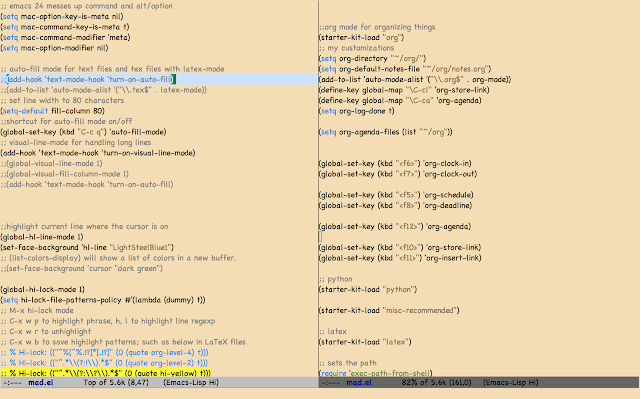
I install brew, and then install cask (using brew). Then I install mactex and emacs using cask. I install Dropbox, so my research directories get to sync. These days Opera is my browser of choice. I use f.lux and caffeine to get my monitor to behave. I can't live without some keyboard customizations. I open keyboard preferences, and get function keybindings to work without requiring the pressing of fn key. While there I map the CAPSLOCK to Control key. I use alt-left/right to traverse between desktops. My Emacs customization takes some time. I use the modularized emacs24-starter kit at http://eschulte.github.io/emacs24-starter-kit/ . It is great, it has good defaults, but it would be much better if it has better documentation and instructions. Since I install emacs using cask rather than from binary, I get to enjoy good package-manager support using ELPA. To see the available packages type M-x package-show-package-list. I install auctex, exec-path-from-shell, ipython,...