Don’t Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS
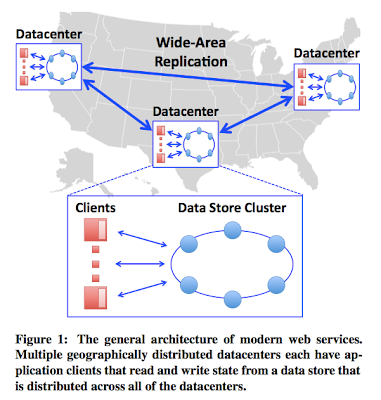
Wyatt Lloyd, Michael J. Freedman, Michael Kaminsky, David G. Andersen Proc. 23rd ACM Symposium on Operating Systems Principles (SOSP ’11) Cascais, Portugal, October 2011. Geo-replicated, distributed data stores are all the rage now. These stores provide wide area network (WAN) replication of all data across geographic regions in all the datacenters. Geo-replication is very useful for global-scale web-applications, especially social networking applications. In social networking, your updates to your account (tweets, posts, etc) are replicated across several regions because you may have followers there, and they should get low-latency access to your updates. The paper refers to properties desired of such a geo-replication service with the acronym ALPS (Availability, low Latency, Partition-tolerance, and high Scalability). Of course, in addition to ALPS, we need to add some consistency requirement to the geo-replication service, because othe...





