Retroscope: Retrospective Monitoring of Distributed Systems (part 2)
This post, part 2, focuses on monitoring distributed systems using Retroscope. This is a joint post with Aleksey Charapko. If you are unfamiliar with hybrid logical clocks and distributed snapshots, give part 1 a read first.
Monitoring and debugging distributed applications is a grueling task. When you need to debug a distributed application, you will often be required to carefully examine the logs from different components of the application and try to figure out how these components interact with each other. Our monitoring solution, Retroscope, can help you with aligning/sorting these logs and searching/focusing on the interesting parts. In particular, Retroscope captures a progression of globally consistent distributed states of a system and allows you to examine these states and search for global predicates.
Let’s say you are working on debugging ZooKeeper, a popular coordination service. Using Retroscope you can easily add instrumentation to the ZooKeeper nodes to log and stream events to the Retroscope Storage and Compute module. After that, you can use RQL, Retroscope's simple SQL-like query language, to process your queries on those logs to detect the predicates/conditions that hold on the globally consistent cuts sorted in Retroscope's compute module.
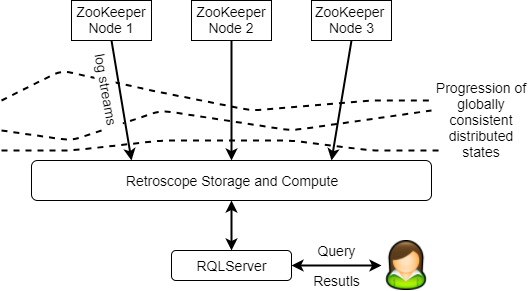
Let's say you want to examine the staleness of the data in the ZooKeeper cluster (since ZooKeeper allows local reads from a single node, a client can read a stale value that has already been updated). By adding instrumentation to track the versions of znodes (the objects that keep data) at each ZooKeeper node, you can monitor how a particular znode changes across the entire cluster in a progression of globally consistent cuts with a very short query: "SELECT vr1 FROM setd;", where setd is the name of the log keeping track of changes and vr1 is version of a znode r1.
The above example still requires you to sift through all the changes in znode r1 across a progression of cuts to see whether there are stale values of r1 in some of the cuts. Instead, you can modify the query to have it return only globally consistent cuts that contain stale versions of the znode: "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". RQL treats different versions of the variable vr1 that exist on various nodes as a set, allowing you to write the queries exploring such sets. With this expression, Retroscope computes the difference between znode r1’s versions across any two nodes for all possible combinations of nodes, and if the difference is 2 or more, Retroscope emits the cut. This query will give you a precise knowledge about global states in which znode differs by at least 2 versions between nodes in the system.
Let's say you got curious about the cause for the staleness in some of the ZooKeeper nodes. By including more information to be returned in each cut, you can test various hypotheses about the causes of staleness. For instance, if you suspect that some ZooKeeper nodes to be disproportionally loaded by clients, you can test it with a query that returns a number of active client connections: "SELECT vr1, client_connections FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". And you can further refine your query to filter staleness cases to when imbalance in client connections is high: "SELECT vr1, client_connections FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2) AND EXISTS c1, c2 IN client_connections: (c1 – c2 > 50)".
To keep the overhead as low as possible for the system being monitored, we augment the target system nodes with only a lightweight RetroLog server module to extract/forward logs to a separate Retroscope storage/compute cluster for monitoring. RetroLogs employ Apache Ignite’s streaming capabilities to deliver the logs to the Retroscope storage/compute cluster. RetroLogs also provide Hybrid Logical Clock (HLC) capabilities to the target system being monitored. HLC is an essential component of Retroscope, as it allows the system to identify consistent cuts. The logging part is similar to how regular logging tools work, except the values being logged are not simply messages, but key-value pairs with the key being the variable being monitored and the value being, well, the current value of the variable.
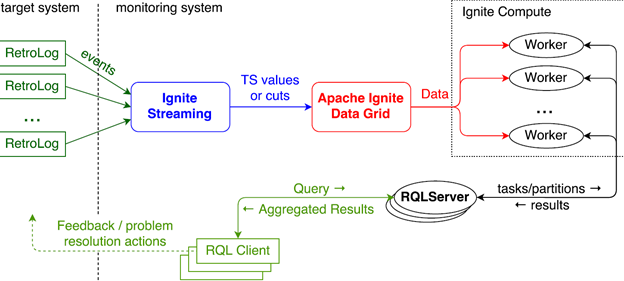
The architecture figure above shows the insides of the Retroscope storage/compute cluster implemented using Apache Ignite. As the RetroLog server stream logs to Ignite cluster for aggregation and storage, the Ignite streaming breaks messages into blocks based on their HLC time. For instance, all messages between timestamps 10 and 20 will be in the same block. The Ignite Data Grid then stores the blocks until they are needed for computing the past consistent cuts.
The RQLServer acts as the query parser and task scheduler for our monitoring tool. It breaks down the duration of state-changes over which a query needs to be evaluated into non-overlapping time-shards and assigns these time-shards to worker nodes for evaluation. As workers process through their assignments, they emit the results back to the RQLServer which then presents the complete output to you.

Let's now zoom in to the Retroscope workers. These workers are designed to search for predicates through a sequence of global distributed states. The search always starts at some known state and progresses forward one state-change at a time. (Each time-shard has its starting state computed before being assigned to the workers. This process is done only once, as time-shards are reused between different queries. When workers perform the search, they always start at the time-shard's starting state and progress forward one state-change at a time.) As the worker advances forward and applies changes, it arrives to new consistent cuts and evaluates the query predicate to decide if the cut must be emitted to the user or not. The figure illustrates running "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)" query on a ZooKeeper cluster of 3 nodes. Each time a variable's value is changed, it is being recorded into a Retroscope log. As the systems starts to search for the global states satisfying the query condition, it first looks at state c0. At this cut the difference between versions on Node 3 and Node 1 is 2, meaning that the worker emits the cut back. The system then moves forward and eventually reaches cut c5 at which the staleness is only 1 version, so c5 is skipped. The search ends when all consistent cuts are evaluated this way. In the example, you will see cuts c0, c1, c2, c3, c4 and c6 being emitted, while cut c5 have small staleness and does not satisfy the condition of the query.
We started by looking at a normal running ZooKeeper cluster on AWS and ran a test workload of 10,000 updates to either a single znode or 10 znodes. All the updates were done by a single synchronous client to make sure that the ZooKeeper cluster is not saturated under a heavy load. After the updates are over, we ran a simple retrospective RQL query to retrieve consistent states at which values have been changing in znode r1: "SELECT vr1 FROM setd;", where setd is the name of the log keeping track of changes and vr1 is version of znode r1. This query produces lots of cuts that must be examined manually, however a quick glance over it shows that a staleness of 1 version is common. This is a normal behavior, as Retroscope was capturing staleness of 1 version right after the value has been committed, and the commit messages may still be in flight to the follower nodes.
To search whether there exists any cases where staleness is 2 versions or greater, we then evaluated the following query: "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". With this query we learned that by targeting a single znode, we were able to observe a staleness of 2 or more versions on about 0.40% of consistent cuts examined. Surprisingly, we also observed a spike of 9 versions in staleness at one cut, however the stale node was then able to quickly catch up. (Probably that spike was due to garbage collection.) We observed that spreading the load across 10 znodes reduced the staleness observed for a single znode.

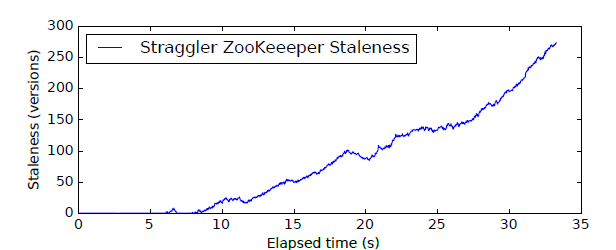
We performed the same staleness experiment on the cluster with one straggler ZooKeeper node that was artificially made to introduce a slight delay of 2ms in the processing of incoming messages. With the straggler, ZooKeeper staleness hit extremes: the slow node was able to keep up with the rest of the cluster only for the first 7 seconds of the test run but then fell further and further behind.
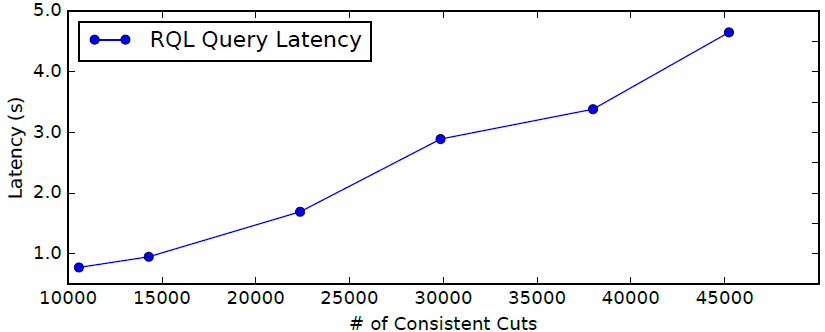
We measured the query processing performance on a single AWS EC2 t2.micro worker node with 1 vCPU and 1 GB of RAM. With such limited resources, a Retroscope worker was still able to process up to 14,000 consistent cuts per second in our ZooKeeper experiments.
We also tested the performance of Retroscope using a synthetic workload. Our test cluster consisted of 2 quad-core machines with 16 GB or RAM connected over WiFi. Each machine was hosting the Ignite node and a synthetic workload generator that streamed events to both Ignite nodes. This cluster was able to intake ~16,500 events per second. The query performance running on the cluster was above 300,000 consistent cuts per second, for a moderately complex query involving a set operation Set operations and a comparison.
Related Links
Here are my other posts on "monitoring" systems:
http://muratbuffalo.blogspot.com/search?q=monitoring
Monitoring and debugging distributed applications is a grueling task. When you need to debug a distributed application, you will often be required to carefully examine the logs from different components of the application and try to figure out how these components interact with each other. Our monitoring solution, Retroscope, can help you with aligning/sorting these logs and searching/focusing on the interesting parts. In particular, Retroscope captures a progression of globally consistent distributed states of a system and allows you to examine these states and search for global predicates.
Let’s say you are working on debugging ZooKeeper, a popular coordination service. Using Retroscope you can easily add instrumentation to the ZooKeeper nodes to log and stream events to the Retroscope Storage and Compute module. After that, you can use RQL, Retroscope's simple SQL-like query language, to process your queries on those logs to detect the predicates/conditions that hold on the globally consistent cuts sorted in Retroscope's compute module.
Let's say you want to examine the staleness of the data in the ZooKeeper cluster (since ZooKeeper allows local reads from a single node, a client can read a stale value that has already been updated). By adding instrumentation to track the versions of znodes (the objects that keep data) at each ZooKeeper node, you can monitor how a particular znode changes across the entire cluster in a progression of globally consistent cuts with a very short query: "SELECT vr1 FROM setd;", where setd is the name of the log keeping track of changes and vr1 is version of a znode r1.
The above example still requires you to sift through all the changes in znode r1 across a progression of cuts to see whether there are stale values of r1 in some of the cuts. Instead, you can modify the query to have it return only globally consistent cuts that contain stale versions of the znode: "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". RQL treats different versions of the variable vr1 that exist on various nodes as a set, allowing you to write the queries exploring such sets. With this expression, Retroscope computes the difference between znode r1’s versions across any two nodes for all possible combinations of nodes, and if the difference is 2 or more, Retroscope emits the cut. This query will give you a precise knowledge about global states in which znode differs by at least 2 versions between nodes in the system.
Let's say you got curious about the cause for the staleness in some of the ZooKeeper nodes. By including more information to be returned in each cut, you can test various hypotheses about the causes of staleness. For instance, if you suspect that some ZooKeeper nodes to be disproportionally loaded by clients, you can test it with a query that returns a number of active client connections: "SELECT vr1, client_connections FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". And you can further refine your query to filter staleness cases to when imbalance in client connections is high: "SELECT vr1, client_connections FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2) AND EXISTS c1, c2 IN client_connections: (c1 – c2 > 50)".
Architecture
OK, let's look at how Retroscope works under the hood.To keep the overhead as low as possible for the system being monitored, we augment the target system nodes with only a lightweight RetroLog server module to extract/forward logs to a separate Retroscope storage/compute cluster for monitoring. RetroLogs employ Apache Ignite’s streaming capabilities to deliver the logs to the Retroscope storage/compute cluster. RetroLogs also provide Hybrid Logical Clock (HLC) capabilities to the target system being monitored. HLC is an essential component of Retroscope, as it allows the system to identify consistent cuts. The logging part is similar to how regular logging tools work, except the values being logged are not simply messages, but key-value pairs with the key being the variable being monitored and the value being, well, the current value of the variable.
The architecture figure above shows the insides of the Retroscope storage/compute cluster implemented using Apache Ignite. As the RetroLog server stream logs to Ignite cluster for aggregation and storage, the Ignite streaming breaks messages into blocks based on their HLC time. For instance, all messages between timestamps 10 and 20 will be in the same block. The Ignite Data Grid then stores the blocks until they are needed for computing the past consistent cuts.
The RQLServer acts as the query parser and task scheduler for our monitoring tool. It breaks down the duration of state-changes over which a query needs to be evaluated into non-overlapping time-shards and assigns these time-shards to worker nodes for evaluation. As workers process through their assignments, they emit the results back to the RQLServer which then presents the complete output to you.

Let's now zoom in to the Retroscope workers. These workers are designed to search for predicates through a sequence of global distributed states. The search always starts at some known state and progresses forward one state-change at a time. (Each time-shard has its starting state computed before being assigned to the workers. This process is done only once, as time-shards are reused between different queries. When workers perform the search, they always start at the time-shard's starting state and progress forward one state-change at a time.) As the worker advances forward and applies changes, it arrives to new consistent cuts and evaluates the query predicate to decide if the cut must be emitted to the user or not. The figure illustrates running "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)" query on a ZooKeeper cluster of 3 nodes. Each time a variable's value is changed, it is being recorded into a Retroscope log. As the systems starts to search for the global states satisfying the query condition, it first looks at state c0. At this cut the difference between versions on Node 3 and Node 1 is 2, meaning that the worker emits the cut back. The system then moves forward and eventually reaches cut c5 at which the staleness is only 1 version, so c5 is skipped. The search ends when all consistent cuts are evaluated this way. In the example, you will see cuts c0, c1, c2, c3, c4 and c6 being emitted, while cut c5 have small staleness and does not satisfy the condition of the query.
Preliminary Evaluation
We performed a preliminary evaluation of Retroscope monitoring on ZooKeeper to study the znode staleness from the server perspective. To the best of our knowledge, no prior studies have been conducted to see how stale ZooKeeper values can be from the server stance.We started by looking at a normal running ZooKeeper cluster on AWS and ran a test workload of 10,000 updates to either a single znode or 10 znodes. All the updates were done by a single synchronous client to make sure that the ZooKeeper cluster is not saturated under a heavy load. After the updates are over, we ran a simple retrospective RQL query to retrieve consistent states at which values have been changing in znode r1: "SELECT vr1 FROM setd;", where setd is the name of the log keeping track of changes and vr1 is version of znode r1. This query produces lots of cuts that must be examined manually, however a quick glance over it shows that a staleness of 1 version is common. This is a normal behavior, as Retroscope was capturing staleness of 1 version right after the value has been committed, and the commit messages may still be in flight to the follower nodes.
To search whether there exists any cases where staleness is 2 versions or greater, we then evaluated the following query: "SELECT vr1 FROM setd WHEN EXISTS v1, v2 IN vr1 : (v1 – v2 >= 2)". With this query we learned that by targeting a single znode, we were able to observe a staleness of 2 or more versions on about 0.40% of consistent cuts examined. Surprisingly, we also observed a spike of 9 versions in staleness at one cut, however the stale node was then able to quickly catch up. (Probably that spike was due to garbage collection.) We observed that spreading the load across 10 znodes reduced the staleness observed for a single znode.
We performed the same staleness experiment on the cluster with one straggler ZooKeeper node that was artificially made to introduce a slight delay of 2ms in the processing of incoming messages. With the straggler, ZooKeeper staleness hit extremes: the slow node was able to keep up with the rest of the cluster only for the first 7 seconds of the test run but then fell further and further behind.
We measured the query processing performance on a single AWS EC2 t2.micro worker node with 1 vCPU and 1 GB of RAM. With such limited resources, a Retroscope worker was still able to process up to 14,000 consistent cuts per second in our ZooKeeper experiments.
We also tested the performance of Retroscope using a synthetic workload. Our test cluster consisted of 2 quad-core machines with 16 GB or RAM connected over WiFi. Each machine was hosting the Ignite node and a synthetic workload generator that streamed events to both Ignite nodes. This cluster was able to intake ~16,500 events per second. The query performance running on the cluster was above 300,000 consistent cuts per second, for a moderately complex query involving a set operation Set operations and a comparison.
Future Plan
We are working on enhancing the capabilities of Retroscope to provide richer and more universal querying language for variety of monitoring and debugging situations. Our plans include adding more complex searching capabilities with conditions that can span across multiple consistent cuts. We are also expanding the logging and processing capabilities to allow keeping track of arrays and sets instead of just single-value variables.Related Links
Here are my other posts on "monitoring" systems:
http://muratbuffalo.blogspot.com/search?q=monitoring





Comments