Hybrid Logical Clocks
Here I will write about our recent work on Hybrid Logical Clocks, which provides a feasible alternative to Google's TrueTime.
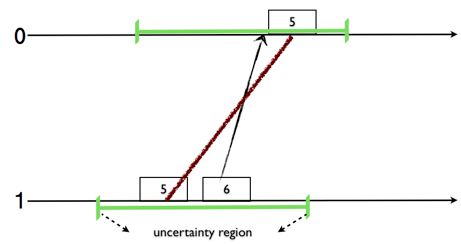
Physical Time (PT) leverages on physical clocks at nodes that are synchronized using the Network Time Protocol (NTP). PT also has several drawbacks. Firstly, in a geographically distributed system obtaining precise clock synchronization is very hard; there will unavoidably be uncertainty intervals. Secondly, PT has several kinks such as leap seconds and non-monotonic updates. And, when the uncertainty intervals are overlapping, PT cannot order events and you end up with inconsistent snapshots as the one shown below.
TrueTime (TT) was introduced by Spanner, Google's globally-distributed multiversion database, to timestamp transactions at global scale. TT leverages on tightly-synchronized physical clocks, but TT also has drawbacks. As in PT, when the uncertainty intervals are overlapping TT cannot order events, and it has to explicitly wait-out these ε intervals. To alleviate the problems of large ε, TT employs GPS/atomic clocks to achieve tight-synchronization (ε=6ms), however the cost of adding the required support infrastructure can be prohibitive and ε=6ms is still a non-negligible time.
Formally, the HLC is problem is to assign each event e a timestamp, l.e, such that
1) e hb f => l.e < l.f,
2) Space requirement for l.e is O(1) integers,
3) l.e is close to pt.e, that is, l.e - pt.e is bounded.
Next I will show you a naive algorithm for HLC which is unbounded. Then I will present our HLC algorithm and show that it is bounded.
 The naive algorithm is very simple and very similar to Lamport's LC algorithm. However, it cannot keep l-pt bounded: l can move ahead of pt in an unbounded manner for certain cases.
The naive algorithm is very simple and very similar to Lamport's LC algorithm. However, it cannot keep l-pt bounded: l can move ahead of pt in an unbounded manner for certain cases.
 In this example run, we can see that l-pt diverges unboundedly if we continue the messaging loop among processes 1, 2, and 3.
In this example run, we can see that l-pt diverges unboundedly if we continue the messaging loop among processes 1, 2, and 3.

Here is the improved algorithm. This algorithm bounds l-pt and c for any case, including the example run presented above. Below is that run annotated with HLC values.
 Notice that in the HLC algorithm, l-pt is trivially bounded by ε. And, more importantly c gets reset regularly. This is because, either l is incremented via receiving a larger l from another node and c gets reset, or l remains the same and pt catches up to l to increase it and c gets reset.
Notice that in the HLC algorithm, l-pt is trivially bounded by ε. And, more importantly c gets reset regularly. This is because, either l is incremented via receiving a larger l from another node and c gets reset, or l remains the same and pt catches up to l to increase it and c gets reset.
Under the most basic/minimal constraint that physical clock of a node is incremented by at least one between any two events on that node, we prove c < N*(ε +1). Recall that the naive algorithm cannot be bounded with this minimal assumption as the counterexample showed.
Under a more lenient environment, if we can assume that the time for message transmission is long enough for the physical clock of every node to be incremented by at least d, we prove c < ε/d+1. Note that under that assumption the naive algorithm also becomes bound-able.
Now let's see how we can get a consistent cut using HLC. The consistency of the cut is implied by ¬(∃ p,q :: l.snap.p < l.snap.q ), which is equivalent to (∀ p,q :: l.snap.p = l.snap.q). That is, to get a consistent cut, all we need to do is to take events with the same l and c value at all nodes. In the figure, we show a consistent cut for l=10 and c=0.

In order to contain the spread of corruptions due to bad HLC values, we have a rule to ignore out of bounds messages. In order to make HLC resilient to common NTP synchronization errors, we assign sufficiently large space to l-pt drift so that most NTP kinks can be masked smoothly.
HLC provides the following benefits: HLC is substitutable for PT (NTP clocks) in any application. HLC is resilient and monotonic and can tolerate NTP kinks. HLC can be used to return a consistent snapshot at any given T. HLC is useful as a timestamping mechanism in multiversion distributed databases, such as Spanner. In fact, HLC is being used in CockroachDB, an opensource clone of Spanner, and is implemented in this module in particular.
Read our paper for the details.
A brief history of time (in distributed systems)
Logical Clocks (LC) was proposed in 1978 by Lamport for ordering events in an asynchronous distributed system. LC has several drawbacks for modern systems. Firstly, LC is divorced from physical time (PT), as a result we cannot query events in relation to real-time. Secondly, to capture happened-before relations, LC assumes that there are no backchannels and all communication occurs within the system.Physical Time (PT) leverages on physical clocks at nodes that are synchronized using the Network Time Protocol (NTP). PT also has several drawbacks. Firstly, in a geographically distributed system obtaining precise clock synchronization is very hard; there will unavoidably be uncertainty intervals. Secondly, PT has several kinks such as leap seconds and non-monotonic updates. And, when the uncertainty intervals are overlapping, PT cannot order events and you end up with inconsistent snapshots as the one shown below.
TrueTime (TT) was introduced by Spanner, Google's globally-distributed multiversion database, to timestamp transactions at global scale. TT leverages on tightly-synchronized physical clocks, but TT also has drawbacks. As in PT, when the uncertainty intervals are overlapping TT cannot order events, and it has to explicitly wait-out these ε intervals. To alleviate the problems of large ε, TT employs GPS/atomic clocks to achieve tight-synchronization (ε=6ms), however the cost of adding the required support infrastructure can be prohibitive and ε=6ms is still a non-negligible time.
Hybrid Logical Clocks
In our recent work (in collaboration with Sandeep Kulkarni at Michigan State University), we introduce Hybrid Logical Clocks (HLC). HLC captures the causality relationship like LC, and enables easy identification of consistent snapshots in distributed systems. Dually, HLC can be used in lieu of PT clocks since it maintains its logical clock to be always close to the PT clock.Formally, the HLC is problem is to assign each event e a timestamp, l.e, such that
1) e hb f => l.e < l.f,
2) Space requirement for l.e is O(1) integers,
3) l.e is close to pt.e, that is, l.e - pt.e is bounded.
Next I will show you a naive algorithm for HLC which is unbounded. Then I will present our HLC algorithm and show that it is bounded.
Naive algorithm
HLC algorithm
Here is the improved algorithm. This algorithm bounds l-pt and c for any case, including the example run presented above. Below is that run annotated with HLC values.
Under the most basic/minimal constraint that physical clock of a node is incremented by at least one between any two events on that node, we prove c < N*(ε +1). Recall that the naive algorithm cannot be bounded with this minimal assumption as the counterexample showed.
Under a more lenient environment, if we can assume that the time for message transmission is long enough for the physical clock of every node to be incremented by at least d, we prove c < ε/d+1. Note that under that assumption the naive algorithm also becomes bound-able.
Now let's see how we can get a consistent cut using HLC. The consistency of the cut is implied by ¬(∃ p,q :: l.snap.p < l.snap.q ), which is equivalent to (∀ p,q :: l.snap.p = l.snap.q). That is, to get a consistent cut, all we need to do is to take events with the same l and c value at all nodes. In the figure, we show a consistent cut for l=10 and c=0.
Fault tolerance
Stabilization of HLC rests on the superposition property of HLC on NTP clocks. Once the NTP/physical clock stabilizes, HLC can be corrected based on the maximum permitted value of l-pt and the maximum value of c. If bounds are violated, we take the physical clock as the authority, and reset l and c values to pt and 0 respectively.In order to contain the spread of corruptions due to bad HLC values, we have a rule to ignore out of bounds messages. In order to make HLC resilient to common NTP synchronization errors, we assign sufficiently large space to l-pt drift so that most NTP kinks can be masked smoothly.
Concluding remarks
We can have a compact representation of HLC timestamps using l and c. NTP uses 64-bit timestamps which consist of a 32-bit part for seconds and a 32-bit part for fractional second. We restrict l to track only the most significant 48 bits of pt. Rounding up pt values to 48 bits l values still gives us microsecond granularity tracking of pt. 16 bits remain for c and allows it room to grow up to 65536. (In our experiments c mostly stayed in single digits.)HLC provides the following benefits: HLC is substitutable for PT (NTP clocks) in any application. HLC is resilient and monotonic and can tolerate NTP kinks. HLC can be used to return a consistent snapshot at any given T. HLC is useful as a timestamping mechanism in multiversion distributed databases, such as Spanner. In fact, HLC is being used in CockroachDB, an opensource clone of Spanner, and is implemented in this module in particular.
Read our paper for the details.





Comments
And the cockroaches are making millions out of it! heh
> ... in a geographically distributed system obtaining precise clock synchronization is very hard ...
It's not just very hard, it's theoretically impossible, according to special relativity, to perfectly synchronize any two clocks. There will always be some intervals of uncertainty.
If it was possible, then it would be also possible to measure speed of light in one direction. But in reality we can only measure the time it takes for the light to go there _and_ back. See Poincaré–Einstein synchronization.
And general relativity makes things only harder.