Learning Machine Learning: A beginner's journey
I have been learning about machine learning and deep learning (ML/DL) for the last year. I think ML/DL is here to stay. I don't think this is a fad or bubble! Here is why:
Certainly there is also a lot of hype about ML/DL. ML/DL proved viable for specific sets of applications, and it is a hyperbole to claim that the general AI has arrived. We are far from it. But that is a good thing, because we will have a lot of juicy problems to work on.
So I am doubling down on ML/DL.
Here are my first impressions learning about ML/DL. ML/DL uses a very different toolkit and approach than the distributed systems field I grew up in. I was initially surprised and taken aback by the very experimental and trial and error nature of ML/DL. ML/DL is dealing with noisy/fuzzy/messy real world data and naturally the field produced statistical and probabilistic tools. Validation is only via showing performance on the test set. The data set is the king. Debugging is a mess, and learning is very opaque. On the other hand, I really like the dynamism in the ML/DL area. There are a lot of resources and platforms and a lot of very interesting applications.
My interest in ML/DL is in its interactions with distributed systems. I am not interested in writing image/text/speech processing applications. I learned about ML/DL to think about two questions:
On a side note, if you like to learn a bit about Ng's thinking process and his approach to life, creativity, and failure, I recommend this interview. It is a very good read.
I really liked the first 3 weeks of Ng's course: Introduction and Linear Regression, Linear Regression with multiple features, and Logistic Regression and regularization. But as the course went to logistic regression with nonlinear decision boundaries, I started to get overwhelmed with the amount of information and complication. And as the course progressed to neural networks, I started to get lost. For example, I could not form a good mental model and picture of forward and backward propagation in neural networks. So those parts didn't stick with me. (I was also not following the programming assignments well.)
I think the problem was that Ng was explaining the neural networks concepts in a general/generic way. That sounded too abstract to me. It might have worked better if he had settled on a small concrete use case and explained the concepts that way.
Recently, I started auditing a deep learning course on Udacity with a Google Engineer, Vincent Vanhoucke. This course offered a simpler introduction to deep learning. The course started with multinomial logistic classification. Since I knew about logistic regression, I could follow this easily. I liked the softmax function, one-hot encoding, and cross entropy ideas as they are all very practical and concrete concepts. The course presented these with the use case of MNIST letter classification for the first 10 letters.
Then using the same MNIST example, the course introduced rectified linear units (ReLu) as a simple way of introducing nonlinearity and showed how to chain multinomial logistic classification with ReLus to construct a deep network that solves the letter classification task much better. This time, I was able to follow the forward and backward propagation ideas much better. Instead of explaining deep networks in a general abstract way, this course explained it in a ReLu-specific way and reusing the letter classification example built with logistical regression. (In Ng's class ReLu came on week 7, when introducing support vector machines).
As a quick way to overview Vincent's course contents, you may watch this YouTube video from another Google engineer. (Watch at 1.5x speed.) The talk uses the same MNIST example and similar approach. But it doesn't go into explanation of forward/backward propagation and deriving the ReLus, instead it focuses more on giving you introduction to TensorFlow skills as well as introducing the basic neural network concepts. Within 1 hour, the talk gets you learning about convolutional networks. The presentation is nice and easy to follow.
Reflecting back, it is interesting how much YouTube helped me to learn about ML/DL. I normally like reading papers better than listening/watching videos, or maybe that is because I am more accustomed to learning that way. But for learning about ML/DL, these YouTube videos have been very helpful. It looks like lecturing is making a come back.
Here is a bonus video of Andrew Ng talking about nuts and bolts of applying deep learning. Ng is a great teacher, so it is easy to follow the concepts presented and learn a lot from this talk.
In the coming days I hope to write brief summaries of the introductory ML/DL concepts I learned from these courses. In my first couple posts on this, I plan to follow the first 3 weeks of Ng's class. There are very good course notes of that course here, and I will summarize even more briefly to mention the big ideas. Then I will switch to Vanhoucke's course to introduce the ideas in multinomial logistical regression and the generalization to neural networks and deep learning from there. I will use the #mlbegin tag for the series. Let's see how that goes.
UPDATE (1/11/17): I wrote them up. Here are the introductory ML/DL concepts I learned from those courses:
- ML/DL has results. It is hard to argue against success.
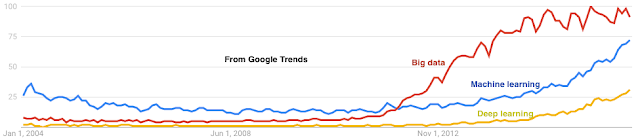
- ML/DL has been on the rise organically since 1985 (with the backpropagation algorithms) and went through another phase of acceleration after 2005 (with the wide availability of big data and distributed data processing platforms). The rise of ML/DL is following a rising curve pattern, not the pattern for a hyped ephemeral bubble. Since it grew gradually over many years, I am betting it will be around for at least the same amount of time.
- ML/DL has been co-developed with applications. It has developed very much on the practice side with trial and error, and its theory is still lagging a bit behind and is unable explain many things. According to Nassim Taleb's heuristics ML/DL is antifragile.
- ML/DL has the market behind it. Big money provides big incentive and has been attracting a lot of smart people. This many smart people cannot be wrong.

Certainly there is also a lot of hype about ML/DL. ML/DL proved viable for specific sets of applications, and it is a hyperbole to claim that the general AI has arrived. We are far from it. But that is a good thing, because we will have a lot of juicy problems to work on.
So I am doubling down on ML/DL.
Here are my first impressions learning about ML/DL. ML/DL uses a very different toolkit and approach than the distributed systems field I grew up in. I was initially surprised and taken aback by the very experimental and trial and error nature of ML/DL. ML/DL is dealing with noisy/fuzzy/messy real world data and naturally the field produced statistical and probabilistic tools. Validation is only via showing performance on the test set. The data set is the king. Debugging is a mess, and learning is very opaque. On the other hand, I really like the dynamism in the ML/DL area. There are a lot of resources and platforms and a lot of very interesting applications.
My interest in ML/DL is in its interactions with distributed systems. I am not interested in writing image/text/speech processing applications. I learned about ML/DL to think about two questions:
- How can we build better distributed systems/architectures to improve the performance of ML/DL systems/applications?
- How can we use ML/DL to build better distributed systems?
How I went about learning ML/DL
In January, I started following Andrew Ng's machine learning course at Coursera. (Alternatively, here is Ng's course material for CS 229 at Stanford.) After the kids went to sleep, I spent an hour each night following Ng's class videos. Andrew Ng has a nice and simple way of explaining ML concepts. He is a very good teacher.On a side note, if you like to learn a bit about Ng's thinking process and his approach to life, creativity, and failure, I recommend this interview. It is a very good read.
I really liked the first 3 weeks of Ng's course: Introduction and Linear Regression, Linear Regression with multiple features, and Logistic Regression and regularization. But as the course went to logistic regression with nonlinear decision boundaries, I started to get overwhelmed with the amount of information and complication. And as the course progressed to neural networks, I started to get lost. For example, I could not form a good mental model and picture of forward and backward propagation in neural networks. So those parts didn't stick with me. (I was also not following the programming assignments well.)
I think the problem was that Ng was explaining the neural networks concepts in a general/generic way. That sounded too abstract to me. It might have worked better if he had settled on a small concrete use case and explained the concepts that way.
Recently, I started auditing a deep learning course on Udacity with a Google Engineer, Vincent Vanhoucke. This course offered a simpler introduction to deep learning. The course started with multinomial logistic classification. Since I knew about logistic regression, I could follow this easily. I liked the softmax function, one-hot encoding, and cross entropy ideas as they are all very practical and concrete concepts. The course presented these with the use case of MNIST letter classification for the first 10 letters.
Then using the same MNIST example, the course introduced rectified linear units (ReLu) as a simple way of introducing nonlinearity and showed how to chain multinomial logistic classification with ReLus to construct a deep network that solves the letter classification task much better. This time, I was able to follow the forward and backward propagation ideas much better. Instead of explaining deep networks in a general abstract way, this course explained it in a ReLu-specific way and reusing the letter classification example built with logistical regression. (In Ng's class ReLu came on week 7, when introducing support vector machines).
As a quick way to overview Vincent's course contents, you may watch this YouTube video from another Google engineer. (Watch at 1.5x speed.) The talk uses the same MNIST example and similar approach. But it doesn't go into explanation of forward/backward propagation and deriving the ReLus, instead it focuses more on giving you introduction to TensorFlow skills as well as introducing the basic neural network concepts. Within 1 hour, the talk gets you learning about convolutional networks. The presentation is nice and easy to follow.
Reflecting back, it is interesting how much YouTube helped me to learn about ML/DL. I normally like reading papers better than listening/watching videos, or maybe that is because I am more accustomed to learning that way. But for learning about ML/DL, these YouTube videos have been very helpful. It looks like lecturing is making a come back.
Here is a bonus video of Andrew Ng talking about nuts and bolts of applying deep learning. Ng is a great teacher, so it is easy to follow the concepts presented and learn a lot from this talk.
In the coming days I hope to write brief summaries of the introductory ML/DL concepts I learned from these courses. In my first couple posts on this, I plan to follow the first 3 weeks of Ng's class. There are very good course notes of that course here, and I will summarize even more briefly to mention the big ideas. Then I will switch to Vanhoucke's course to introduce the ideas in multinomial logistical regression and the generalization to neural networks and deep learning from there. I will use the #mlbegin tag for the series. Let's see how that goes.
UPDATE (1/11/17): I wrote them up. Here are the introductory ML/DL concepts I learned from those courses:





Comments
http://cs231n.stanford.edu/
It gets into deep learning for vision. Most of the recent deep learning papers are quite accessible, and you'll have no trouble following them if you're comfortable with high school calculus.
Very nice post. I'm also interested in Machine Learning. Thanks for recommending the course for learning. I'll try to take it.
does anyone have any other reco's?
Exceptionally decent post. I'm additionally intrigued by Machine Learning. A debt of gratitude is in order for suggesting the course to learn. I'll endeavor to take it.