Selected blog posts from 2016
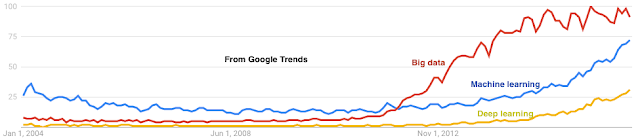
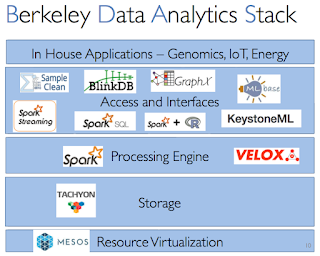
This is my 42nd post for the year. As is the custom in a year-end post, I mention some highlights among my 41 posts in 2016. Machine Learning Learning Machine Learning: A beginner's journey. I wrote this to quickly recap about what I found confusing and useful while I learned about machine learning. I had no idea this would blow up. This received the most pageviews: 45,000 and counting. TensorFlow: A system for large-scale machine learning. Facebook papers Realtime Data Processing at Facebook. Measuring and Understanding Consistency at Facebook. Holistic Configuration Management at Facebook. Fault-tolerance Why Does the Cloud Stop Computing? Lessons from Hundreds of Service Outages. TaxDC: A Taxonomy of nondeterministic concurrency bugs in datacenter distributed systems. Distributed Coordination Modular Composition of Coordination Services. Make sure you read the comment at the end, where one of the author...