Emerging trends in big data software
Mike Franklin, a famous expert on data science, had visited our department at University at Buffalo in May to talk about emerging trends in big data software. I had taken some notes during his talk, and decided to summarize and share them here.
Mike recently joined University of Chicago as the chair of Computer Science Department, and before that he was the head of UC Berkeley's AMPLab (Algorithms, Machines and People Laboratory), where he was involved with the Spark and Mesos projects which had wide academic and industrial impact. Naturally, the talk included a lot of discussion about AMPLab projects, and in particular Spark.
Mike described AMPLab as a federation of faculty that collaborate around an interesting emerging trend. AMPLab has in total 90 faculty and students. Half of the funding comes from government, and the other half from industrial sponsors. The industrial sponsors also provide constant feedback about what the lab works on and how it matters for them. As an AMPLab student graduates, a system he/she worked on also graduates from the lab. Mike credits this model with wide academic and industrial impact.
While I don't have Mike's slides from his talk at Buffalo, I found his slides for a keynote he delivered in March on the same topic. Below I provide very brief highlights from Mike's talk. See his slides for more information.
Big data spurted a lot of new software framework development. Data processing technology has fundamentally changed to become massively scalable, start using flexible schema, and provide easier integration of search query and analysis with a variety of languages. All these changes drive further innovation in big data area.
The talk continues on summarizing some important trends in big data software.
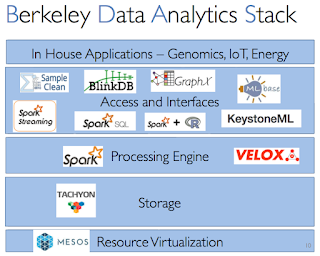
Mike explains AMPLab's unification strategy as generalizing the MapReduce model. This leads to
1. richer programming model (fewer systems to master)
2. better data sharing (less data movement)
Here Mike talked about RDDs (Resilient Distributed Datasets) for improving over the inefficiency of MapReduce redundantly loading and writing data at each iteration. An RDD is a read-only partitioned collection of records distributed across a set of machines. Spark allows users to cache frequently used RDDs in-memory to avoid the overhead of writing intermediate data to disk and achieving up to 10-100x faster performance than MapReduce.
Spark dataflow API provides coarse grained transformations on RDDs such as map groupby, join, sort, filter, sample. RDDs are able to get good fault-tolerance without using the disk, by logging the transformations used to build an RDD and reapplying transformations from earlier RDDs to reconstruct that RDD in case it got lost/damaged.
Mike's complaint about this architecture is that it leads to duplication of work: you need to write processing both for the batch layer and the real-time speed layer, and when you need to modify something you need to do it again both for the batch layer and the real-time speed layer. Instead Mike mentions the kappa architecture based on Spark (first advocated by Jay Kreps) which gets rid off a separate batching layer and uses Spark streaming as both the batching and the real-time speed layer. Spark streaming uses microbatch approach to provide low latency. It introduces additional "windowed" operations. Mike says that Spark streaming doesn't provide everything a fullblown streaming system does, but it does provide most of it most of the time.

Mike recently joined University of Chicago as the chair of Computer Science Department, and before that he was the head of UC Berkeley's AMPLab (Algorithms, Machines and People Laboratory), where he was involved with the Spark and Mesos projects which had wide academic and industrial impact. Naturally, the talk included a lot of discussion about AMPLab projects, and in particular Spark.
Mike described AMPLab as a federation of faculty that collaborate around an interesting emerging trend. AMPLab has in total 90 faculty and students. Half of the funding comes from government, and the other half from industrial sponsors. The industrial sponsors also provide constant feedback about what the lab works on and how it matters for them. As an AMPLab student graduates, a system he/she worked on also graduates from the lab. Mike credits this model with wide academic and industrial impact.
While I don't have Mike's slides from his talk at Buffalo, I found his slides for a keynote he delivered in March on the same topic. Below I provide very brief highlights from Mike's talk. See his slides for more information.
Motivation for big data
Big data is defined as datasets typically consisting of billions of trillions of records. Mike argues that big data is a big resource. For example, we knew that Tamoxifen is 80% effective for breast cancer, but thanks to big data, now we know that it is 100% at 70-80% of people and ineffective in the rest. Even 1% effective drugs could save lives; with enough of the right data we can determine precisely who the treatment will work for.Big data spurted a lot of new software framework development. Data processing technology has fundamentally changed to become massively scalable, start using flexible schema, and provide easier integration of search query and analysis with a variety of languages. All these changes drive further innovation in big data area.
The talk continues on summarizing some important trends in big data software.
Trend1: Integrated stacks vs silos
Stonebraker famously said "one size doesn't fit all in DBMS development any more". But, Mike says that in their experience, they found that it is possible to build a single system that solves a lot problems. Of course Mike is talking about their platform Berkeley Data Analytics Stack (BDAS). Mike cites their Spark user survey to support his claim that one size fits many: Among 1400 respondents, 88% use at least 2 components, 60% at least 3, 27% at least 4.
Mike explains AMPLab's unification strategy as generalizing the MapReduce model. This leads to
1. richer programming model (fewer systems to master)
2. better data sharing (less data movement)
Here Mike talked about RDDs (Resilient Distributed Datasets) for improving over the inefficiency of MapReduce redundantly loading and writing data at each iteration. An RDD is a read-only partitioned collection of records distributed across a set of machines. Spark allows users to cache frequently used RDDs in-memory to avoid the overhead of writing intermediate data to disk and achieving up to 10-100x faster performance than MapReduce.
Spark dataflow API provides coarse grained transformations on RDDs such as map groupby, join, sort, filter, sample. RDDs are able to get good fault-tolerance without using the disk, by logging the transformations used to build an RDD and reapplying transformations from earlier RDDs to reconstruct that RDD in case it got lost/damaged.
Trend2: "Real-time" redux
One approach for handling real-time is the lambda architecture, which proposes using real-time speed layer to accompany and complement the traditional batch processing+serving layer.Mike's complaint about this architecture is that it leads to duplication of work: you need to write processing both for the batch layer and the real-time speed layer, and when you need to modify something you need to do it again both for the batch layer and the real-time speed layer. Instead Mike mentions the kappa architecture based on Spark (first advocated by Jay Kreps) which gets rid off a separate batching layer and uses Spark streaming as both the batching and the real-time speed layer. Spark streaming uses microbatch approach to provide low latency. It introduces additional "windowed" operations. Mike says that Spark streaming doesn't provide everything a fullblown streaming system does, but it does provide most of it most of the time.






Comments