paper summary: One Trillion Edges, Graph Processing at Facebook-Scale
This paper was recently presented at VLDB15.
A. Ching, S. Edunov, M. Kabiljo, D. Logothetis, S. Muthukrishnan, "One Trillion Edges: Graph Processing at Facebook-Scale." Proceedings of the VLDB Endowment 8.12 (2015).
This paper is about graph processing. Graphs provide a general flexible abstraction to model relations between entities, and find a lot of demand in the field of big data analysis (e.g., social networks, web-page linking, coauthorship relations, etc.)
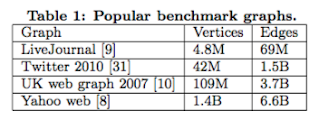 You think the graphs in Table 1 are big, but Frank's laptop begs to differ. These graphs also fail to impress Facebook. In Facebook, they work with graphs of trillion edges, 3 orders magnitude larger than these. How would Frank's laptop fare for this? @franks_laptop may step up to answer that question soon. This paper presents how Facebook deals with these huge graphs of one trillion edges.
You think the graphs in Table 1 are big, but Frank's laptop begs to differ. These graphs also fail to impress Facebook. In Facebook, they work with graphs of trillion edges, 3 orders magnitude larger than these. How would Frank's laptop fare for this? @franks_laptop may step up to answer that question soon. This paper presents how Facebook deals with these huge graphs of one trillion edges.
(The BSP model and Pregel, which Apache Giraph derived from, was covered in an earlier post of mine. You can read that first, if you are unfamiliar with these concepts. I have also summarized some of the Facebook data storage and processing systems before, if you like to read about them.)
However, chosing Apache Giraph was not the end of the story. Facebook was not happy with the state of Apache Giraph, and extended, polished, optimized it for their production use. (And of course Facebook contributed these back to the Apache Giraph project as open source.) This paper explains those extensions.
I was more interested in their extensions to the compute model, which I summarize below.
(That was in fact a bad use of the ZooKeeper framework, as outlined in this post there are better ways to do it. Incidentally, my student Ailidani and I are looking at Paxos use in production environments and we collect anectodes like this. Email us if you have some examples to share.)

In the sharded aggregator architecture implemented by Facebook (Figure 3), each aggregator is randomly assigned to one of the workers. The assigned worker is in charge of gathering the values of its aggregators from all workers and distributing the final values to the master and other workers. This balances aggregation across all workers rather than bottlenecking the master and aggregators are limited only by the total memory available on each worker. Note that this is not fault-tolerant; they lost the crash-tolerance of ZooKeeper.
Similarly, Facebook added master computation to do centralized computation prior to every superstep that can communicate with the workers via aggregators. This is generally a lightweight task (easily computable without requiring much data analysis) that has a global scope (applies as input to all workers in the next supercomputing step).
The production application workflow is as follows. The developer first develops and unit tests the application locally. Then tests the application on small number of servers on a test dataset (e.g., Facebook graph for one country). Then the application is run at scale on 200 workers. After tests, the application is ready for production use.


A. Ching, S. Edunov, M. Kabiljo, D. Logothetis, S. Muthukrishnan, "One Trillion Edges: Graph Processing at Facebook-Scale." Proceedings of the VLDB Endowment 8.12 (2015).
This paper is about graph processing. Graphs provide a general flexible abstraction to model relations between entities, and find a lot of demand in the field of big data analysis (e.g., social networks, web-page linking, coauthorship relations, etc.)

Apache Giraph and Facebook
In order to analyze social network data more efficiently, Facebook considered some graph processing platforms including Hive, GraphLab, Giraph in the summer of 2012. They ended up choosing Apache Giraph for several reasons: it is open source, it directly interfaces with Facebook's internal version of HDFS and Hive, it is written in Java, and its BSP model is simple and easy to reason about.(The BSP model and Pregel, which Apache Giraph derived from, was covered in an earlier post of mine. You can read that first, if you are unfamiliar with these concepts. I have also summarized some of the Facebook data storage and processing systems before, if you like to read about them.)
However, chosing Apache Giraph was not the end of the story. Facebook was not happy with the state of Apache Giraph, and extended, polished, optimized it for their production use. (And of course Facebook contributed these back to the Apache Giraph project as open source.) This paper explains those extensions.
Significant technical extensions to Giraph
Several of Facebook's extensions were done in order to generalize the platform. Facebook extended the original input model in Giraph, which required a rather rigid and limited layout (all data relative to a vertex, including outgoing edges, had to be read from the same record and were assumed to exist in the same data source) to enable flexible vertex/edge based input. Facebook added parallelization support that enabled adding more workers per machine, and introduced worker local multithreading to take advantage of additional CPU cores. Finally Facebook added memory optimizations to serialize the edges of every vertex into a byte array rather than instantiating them as native Java objects.I was more interested in their extensions to the compute model, which I summarize below.
Sharded aggregators
The aggregator framework in Giraph was implemented over ZooKeeper rather inefficiently. Workers would write partial aggregated values to znodes (Zookeeper data storage). The master would aggregate all of them, and write the final result back to its znode for workers to access it. This wasn't scalable due to znode size constraints (maximum 1 megabyte) and Zookeeper write limitations and caused a problem for Facebook which needed to support very large aggregators (e.g. gigabytes).(That was in fact a bad use of the ZooKeeper framework, as outlined in this post there are better ways to do it. Incidentally, my student Ailidani and I are looking at Paxos use in production environments and we collect anectodes like this. Email us if you have some examples to share.)

In the sharded aggregator architecture implemented by Facebook (Figure 3), each aggregator is randomly assigned to one of the workers. The assigned worker is in charge of gathering the values of its aggregators from all workers and distributing the final values to the master and other workers. This balances aggregation across all workers rather than bottlenecking the master and aggregators are limited only by the total memory available on each worker. Note that this is not fault-tolerant; they lost the crash-tolerance of ZooKeeper.
Worker and Master Phase Extensions
For the worker-side, the methods preSuperstep(), postSuperstep(), preApplication(), and postApplication() were added. As an example, the preSuperstep() method is executed on every worker prior to every superstep, and can be used in k-means clustering implementation to let every worker compute the final centroid locations just before the input vectors are processed.Similarly, Facebook added master computation to do centralized computation prior to every superstep that can communicate with the workers via aggregators. This is generally a lightweight task (easily computable without requiring much data analysis) that has a global scope (applies as input to all workers in the next supercomputing step).
Superstep Splitting
When operating on very large scale graphs, a superstep may generate a lot of data to share with other workers (e.g., in the friends-of-friends score calculation), that the output does not fit in memory. Giraph can use disk but this slows things signification. The superstep technique is for doing the same computation all in-memory for such applications. The idea is that in such a message heavy superstep, a worker can send a fragment of the messages to their destinations and do a partial computation that updates the state of the vertex value.Operational experience
Facebook uses Apache Giraph for production applications, for a variety of tasks including label propagation, variants of PageRank, and k-means clustering. The paper reports that most of Facebook's production applications run in less than an hour and use less than 200 machines. Due to the short execution duration and small number of machines, the chance of failure is relatively low and, when a failure occurs, it is handled by restarts.The production application workflow is as follows. The developer first develops and unit tests the application locally. Then tests the application on small number of servers on a test dataset (e.g., Facebook graph for one country). Then the application is run at scale on 200 workers. After tests, the application is ready for production use.
Evaluations
This is where Facebook shows off. They ran an iteration of unweighted PageRank on the 1.39B Facebook user dataset with over 1 trillion social connections. They were able to execute PageRank in less than 3 minutes per iteration with only 200 machines.

Conclusions
The paper gives the following as concluding remarks:First, our internal experiments show that graph partitioning can have a significant effect on network bound applications such as PageRank.These are of course related to what we mentioned recently about the trends in distributed systems research in cloud computing. (Part 1, Part 2)
Second, we have started to look at making our computations more asynchronous as a possible way to improve convergence speed.
Finally, we are leveraging Giraph as a parallel machine-learning platform.





Comments