Consensus in the wild
The consensus problem has been studied in the theory of distributed systems literature extensively. Consensus is a fundamental problem in distributed systems. It states that n nodes agree on the same decision eventually. Consistency part of the specification says that no two nodes decide differently. Termination states that all nodes eventually decide. And NonTriviality says that the decision cannot be static (you need to decide a value among inputs/proposals to the system, you can't keep deciding 0 discarding the inputs/proposals). This is not a hard problem if you have reliable and bounded-delay channels and processes, but becomes impossible in the absence of either. And with even temporary violation of reliability and timing/synchronicity assumptions, a consensus system can easily spawn multiple corner-cases where consistency or termination is violated. E.g., 2-phase commit is blocking (this violates termination), and 3-phase commit is unproven and has many corner cases involving the old leader waking up in the middle of execution of the new leader (this violates consistency).
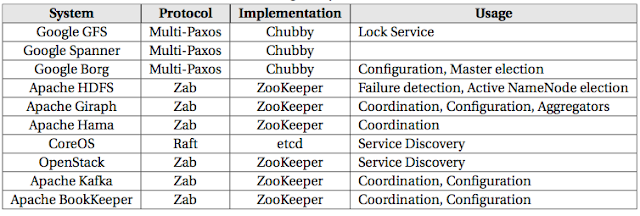
Paxos appeared in 1985 and provided a fault-tolerant solution to consensus. Paxos dealt with asynchrony, process crash/recovery, and message loss in a uniform and elegant algorithmic way. When web-scale services and datacenter computing took off in early 2000s, fault-tolerant consensus became a practical concern. Google started to run into corner cases of consensus that introduced downtime. Luckily Google had people who had academic background in distributed systems (like Tushar Chandra) and they knew what to do. Paxos algorithm got adopted at Google in the Chubby lock service, and used in Google File System and for replicating master node in Map Reduce systems. Then Paxos, the algorithm only distributed systems researchers knew about, got popular in the wild. Several other companies adopted Paxos, and several opensource implementations appeared.
(Had we not have a well-enginereed robust algorithm for consensus in the form of Paxos, what would happen? It would probably be a mess with many groups coming up with their own implementation of a consensus protocol which would be buggy in some small but significant manner.)
My student Ailidani and I are working on a survey of consensus systems in the wild. We compare different flavors of the Paxos consensus protocol with their associated advantages and drawbacks. We also survey how consensus protocols got adopted in the industry and for which jobs. Finally, we discuss where Paxos is used in an overkill manner, where a consensus algorithm could be avoided, or could be tucked out of the main/critical pathway (consensus is expensive afterall.).
The classical multi-Paxos protocol is nicely reviewed and presented in Robbert Van Rennesse's "Paxos Made Moderately Complex" paper.
Zab is used in ZooKeeper, the popular "coordination kernel". ZooKeeper is used by Hadoop (replicating master at HDFS, Map Reduce), and in the industry for keeping/replicating configurations (Netflix, etc.)
Raft provides a flavor of Paxos very similar to Zab. It comes with a focus on understandability and simplicity and has seen several opensource implementations.
The leader election in Paxos can be concurrent with the ongoing consensus requests/operations, and multiple leaders may even get requests proposed and accepted. (Mencius/e-Paxos systematize this and use it for improving throughput.) In contrast, in Zab, a new leader cannot start proposing a new value before it passes a barrier function which ensures that the leader has the longest commit history and every previously proposed value are commited at each acceptor. This way, Zab divides time into three sequential phases.
Another major difference between Zab and Paxos is that Zab protocol also includes client interaction, which introduced an additional order guarantee, per-client FIFO order. All requests from a given client are executed in the order that they were sent by the client. Such guarantee does not hold with Paxos.
Apache Giraph made this mistake in aggregators. (This was mentioned in the Facebook's recent Giraph paper.) In Giraph, workers would write partial aggregated values to znodes (Zookeeper's data storage) and the master would aggregate these and write the final result back to its znode for the workers to access. This wasn't scalable due to Zookeeper write throughput limitations and caused a big problem for Facebook which needed to support very large sized aggregators.
In the same vein, using Paxos for queueing or messaging service is a bad idea. When the number of messages increase, performance doesn't scale.
What is the right way of approaching this then? Use chain replication! Chain replication uses Paxos for fault-tolerant storage of metadata:"the configuration of replicas in the chain" and lets replication/storage of data occur in the chain, without involving Paxos. This way, Paxos doesn't get triggered with every piece of data entering the system. Rather it gets triggered rarely, only if a replica fails and a new configuration needs to be agreed.
Apache Kafka and Bookkeeper work based on this principle and are the correct ways to address the above two scenarios.
2) Paxos implies serializability but serializability does not imply Paxos. Paxos provides a total order on operations/requests replicated over k replicas and can be an overkill for achieving serializability for two reasons. First Paxos's true goal is fault-tolerant replication and serialization only its side effect. If you just need serializability and don't need fault-tolerant replication of each operation/request, then Paxos slows your performance. Secondly, Paxos gives you total order but serializability does not require a total order. A partial order that is serializable is good enough and gives you more options.
Paxos appeared in 1985 and provided a fault-tolerant solution to consensus. Paxos dealt with asynchrony, process crash/recovery, and message loss in a uniform and elegant algorithmic way. When web-scale services and datacenter computing took off in early 2000s, fault-tolerant consensus became a practical concern. Google started to run into corner cases of consensus that introduced downtime. Luckily Google had people who had academic background in distributed systems (like Tushar Chandra) and they knew what to do. Paxos algorithm got adopted at Google in the Chubby lock service, and used in Google File System and for replicating master node in Map Reduce systems. Then Paxos, the algorithm only distributed systems researchers knew about, got popular in the wild. Several other companies adopted Paxos, and several opensource implementations appeared.
(Had we not have a well-enginereed robust algorithm for consensus in the form of Paxos, what would happen? It would probably be a mess with many groups coming up with their own implementation of a consensus protocol which would be buggy in some small but significant manner.)
My student Ailidani and I are working on a survey of consensus systems in the wild. We compare different flavors of the Paxos consensus protocol with their associated advantages and drawbacks. We also survey how consensus protocols got adopted in the industry and for which jobs. Finally, we discuss where Paxos is used in an overkill manner, where a consensus algorithm could be avoided, or could be tucked out of the main/critical pathway (consensus is expensive afterall.).
Paxos flavors
There are three main/popular flavors: classical multi-Paxos, ZooKeeper Zab protocol, and Raft protocol.The classical multi-Paxos protocol is nicely reviewed and presented in Robbert Van Rennesse's "Paxos Made Moderately Complex" paper.
Zab is used in ZooKeeper, the popular "coordination kernel". ZooKeeper is used by Hadoop (replicating master at HDFS, Map Reduce), and in the industry for keeping/replicating configurations (Netflix, etc.)
Raft provides a flavor of Paxos very similar to Zab. It comes with a focus on understandability and simplicity and has seen several opensource implementations.

Differences between Paxos and Zab
Zab provides consensus by atomic broadcast protocol. Zab implements a primary process as the distinguished leader, which is the only proposer in the system. The log entries flow only from this leader to the acceptors.The leader election in Paxos can be concurrent with the ongoing consensus requests/operations, and multiple leaders may even get requests proposed and accepted. (Mencius/e-Paxos systematize this and use it for improving throughput.) In contrast, in Zab, a new leader cannot start proposing a new value before it passes a barrier function which ensures that the leader has the longest commit history and every previously proposed value are commited at each acceptor. This way, Zab divides time into three sequential phases.
Another major difference between Zab and Paxos is that Zab protocol also includes client interaction, which introduced an additional order guarantee, per-client FIFO order. All requests from a given client are executed in the order that they were sent by the client. Such guarantee does not hold with Paxos.
Differences between Zab and Raft
There isn't much difference between Zab and Raft. ZooKeeper keeps a filesystem like API and hierarchical znodes, whereas Raft does not specify the state machine. On the whole, if you compare Zab (the protocol underlying ZooKeeper) and Raft there aren't any major differences in each component, but only minor implementation differences.Abusing Paxos consensus
1) Paxos is meant to be used as fault-tolerant storage of *metadata*, not data. Abusing Paxos for replicated storage of data will kill the performance.Apache Giraph made this mistake in aggregators. (This was mentioned in the Facebook's recent Giraph paper.) In Giraph, workers would write partial aggregated values to znodes (Zookeeper's data storage) and the master would aggregate these and write the final result back to its znode for the workers to access. This wasn't scalable due to Zookeeper write throughput limitations and caused a big problem for Facebook which needed to support very large sized aggregators.
In the same vein, using Paxos for queueing or messaging service is a bad idea. When the number of messages increase, performance doesn't scale.
What is the right way of approaching this then? Use chain replication! Chain replication uses Paxos for fault-tolerant storage of metadata:"the configuration of replicas in the chain" and lets replication/storage of data occur in the chain, without involving Paxos. This way, Paxos doesn't get triggered with every piece of data entering the system. Rather it gets triggered rarely, only if a replica fails and a new configuration needs to be agreed.
Apache Kafka and Bookkeeper work based on this principle and are the correct ways to address the above two scenarios.
2) Paxos implies serializability but serializability does not imply Paxos. Paxos provides a total order on operations/requests replicated over k replicas and can be an overkill for achieving serializability for two reasons. First Paxos's true goal is fault-tolerant replication and serialization only its side effect. If you just need serializability and don't need fault-tolerant replication of each operation/request, then Paxos slows your performance. Secondly, Paxos gives you total order but serializability does not require a total order. A partial order that is serializable is good enough and gives you more options.





Comments
I bring this up in response to your mention of these consensus systems being better used for metadata than data. I mentioned to this person that etcd is usually more of a key-value storage for things like environment variables, but I wasn't entirely sure their mentor was wrong on their proposition.
Separately, does Zookeeper, like Kafka, use consensus for metadata only or is this decision up to the services/people relying on Zookeeper?
I'm particularly interested in finding some consensus system that favors multi-datacenter. etcd and Consul are the closest I've come to that, I think, but I'm eager to hear if you know of anything better.
Thanks!
-Joshua