Checking statistical properties of protocols using TLA+
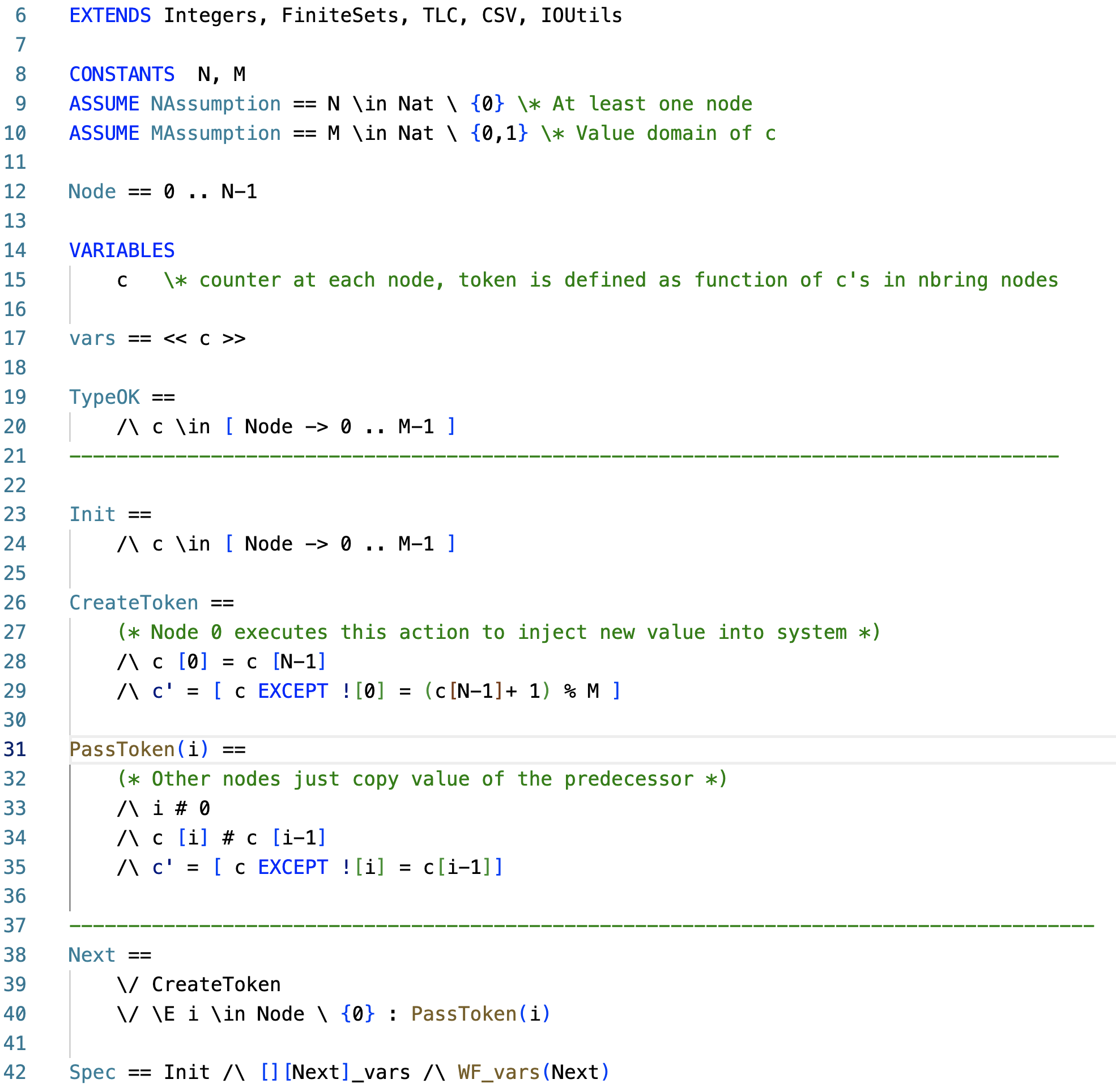
In my previous post, I mentioned how excited I was about Jack Vanlightly and Markus Kuppe's talk at TLA+ Conference. They showed a new mode (called "generate") added to the TLA+ checker to enable obtaining statistical properties from the models. Here is how this works in a nutshell. Your TLA+ model/protocol produces a tree of runs, and, in the generate mode the TLA+ checker chooses these runs in a uniform manner. You also specify some state constraints, and when these are satisfied the TLA+ checker executes/evaluates your state constraint formula: you add the statistics logging as the side effect of this formula, and record information about the current run to a CSV file. This way, you can collect statistical hyper properties (abort rates, completion rounds, etc.) about the runs, in addition to checking it for correctness invariants. Later you can use Excel or Rscript to visualize the statistics collected and analyze the model behavior. Checking statistics is very usef...








