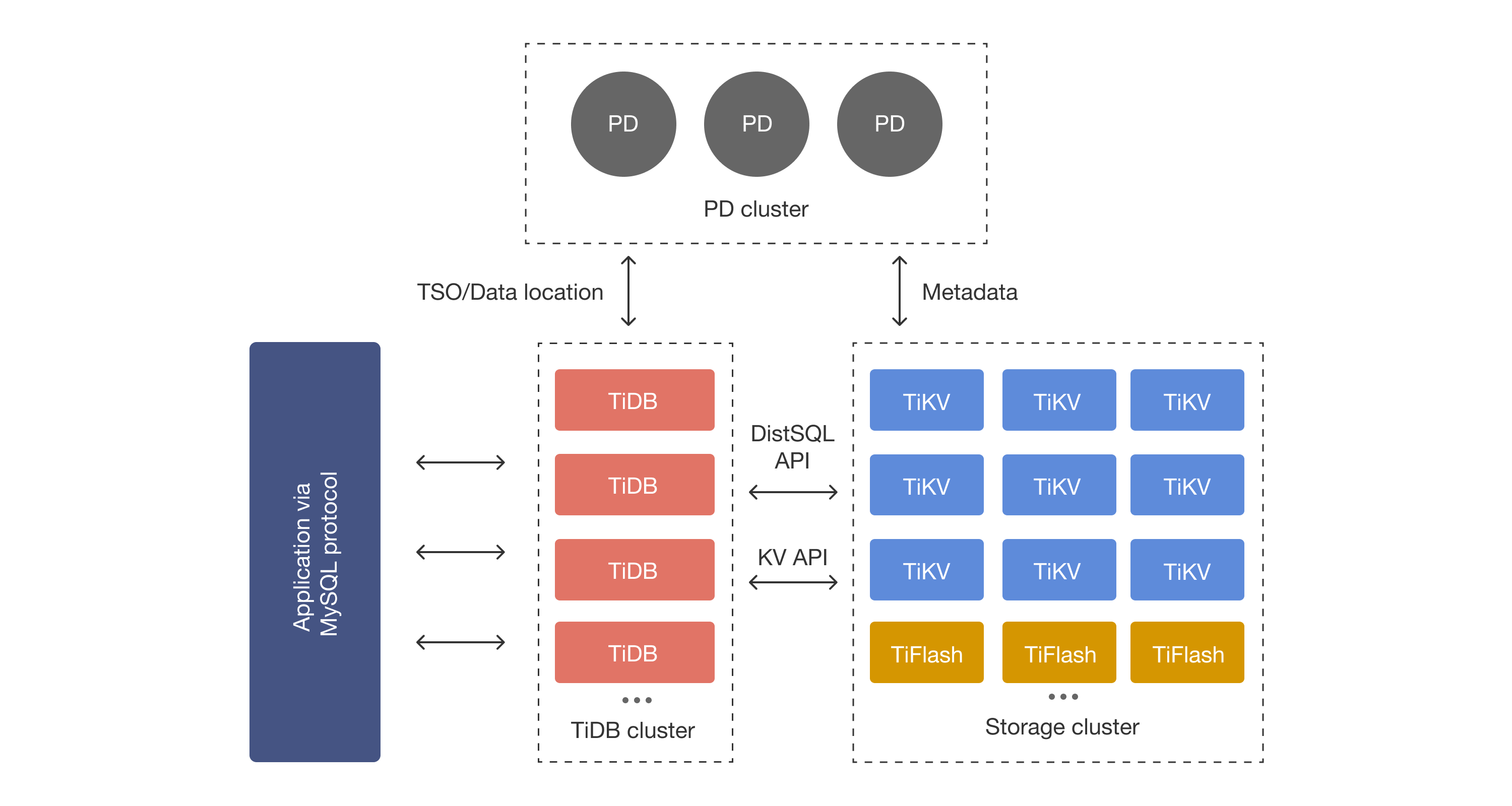
Morty: Scaling Concurrency Control with Re-Execution

This EuroSys '23 paper reads like an SOSP best paper. Maybe it helped that EuroSys 2023 was in Rome. Academic conferences are more enjoyable when the venue doubles as a vacation. The Problem Morty tackles a fundamental question: how can we improve concurrency under serializable isolation (SER), especially without giving up on interactive transactions? Unlike deterministic databases (e.g., Calvin ) that require transactions to declare read and write sets upfront, Morty supports transactions that issue dynamic reads and writes based on earlier results. Transactional systems, particularly in geo-replicated settings, struggle under contention. High WAN latency stretches transaction durations, increasing the window for conflicts. The traditional answer is blind exponential backoff, but that leads to low CPU utilization. TAPIR and Spanner replicas often idle below 17% under contention as Morty's evaluation experiments show. Morty's approach to tackle the problem is to start from...