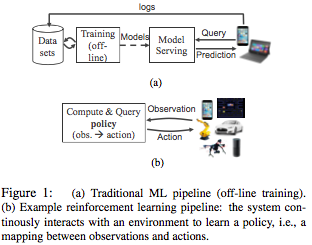
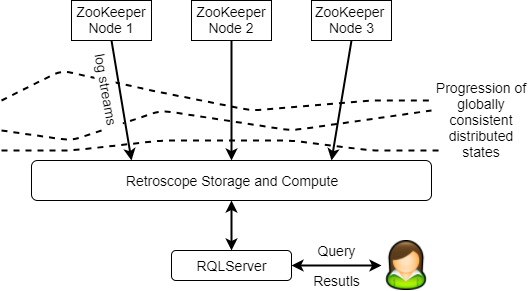
DDIA: Chapter 11 - Stream Processing

Daily batch processes introduce significant latency, since input changes reflected in the output only after a day. For fast paced business, this is too slow. To reduce delays, stream processing occurs more frequently (e.g., every second) or continuously, where events are handled as they happen. In stream processing, a record is typically called an event—a small, immutable object containing details of an occurrence, often with a timestamp. Polling for new events becomes costly when striving for low-latency continuous processing. Frequent polling increases overhead as most requests return no new data. Instead, systems should notify consumers when new events are available. Messaging systems handle this by pushing events from producers to consumers. Direct messaging systems require application code to handle message loss and assume producers and consumers are always online, limiting fault tolerance. Message brokers (or message queues) improve reliability by acting as intermediaries. P...