Going Beyond an Incident Report with TLA+

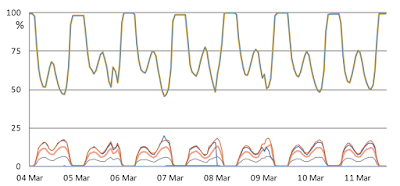
This is a short article at usenix-login about the use of TLA+ to explain root cause for an Azure incident. It seems like this is part of a longer arxiv paper on the use of TLA+ for exploring/explaining data consistency in Cosmos DB. Markus Kuppe is an author here. Markus is heading the TLA+ model checker, TLC, development for more than a decade. If you've used the TLA+ model checker, you used Markus's work. If you are an intermediate/advanced user, it is very likely that you interacted with Markus, and got help from him at some point. The incident The Microsoft Azure incident is a 28-day outage. It looks like the incident got undetected/unreported for 26 days, because it was a partial outage. " A majority of requests did not fail -- rather, a specific type of request was disproportionately affected, such that global error rates did not reveal the outage despite a specific group of users being impacted. " For each request serviced by the work dispatcher, it would (1)...