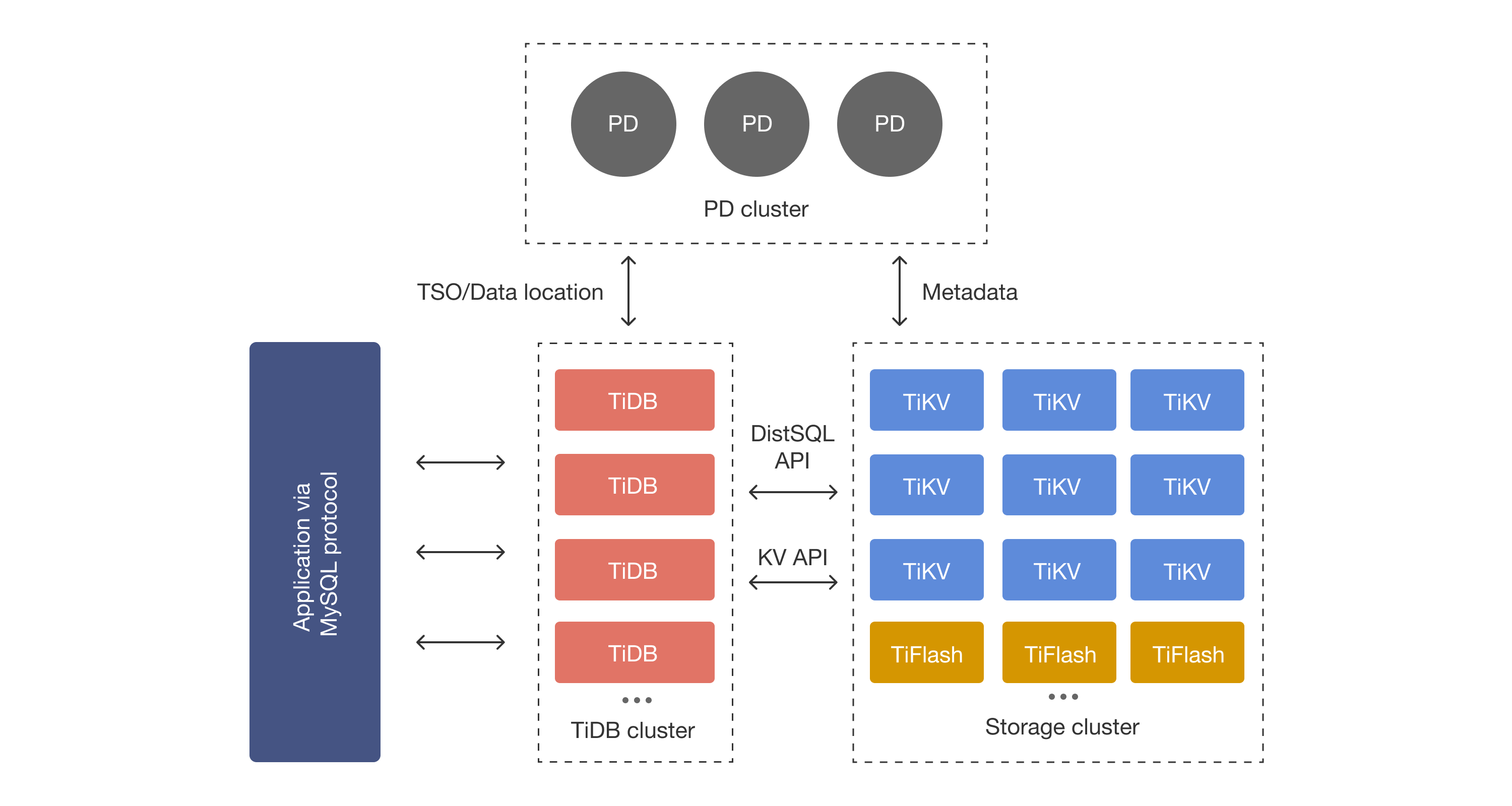
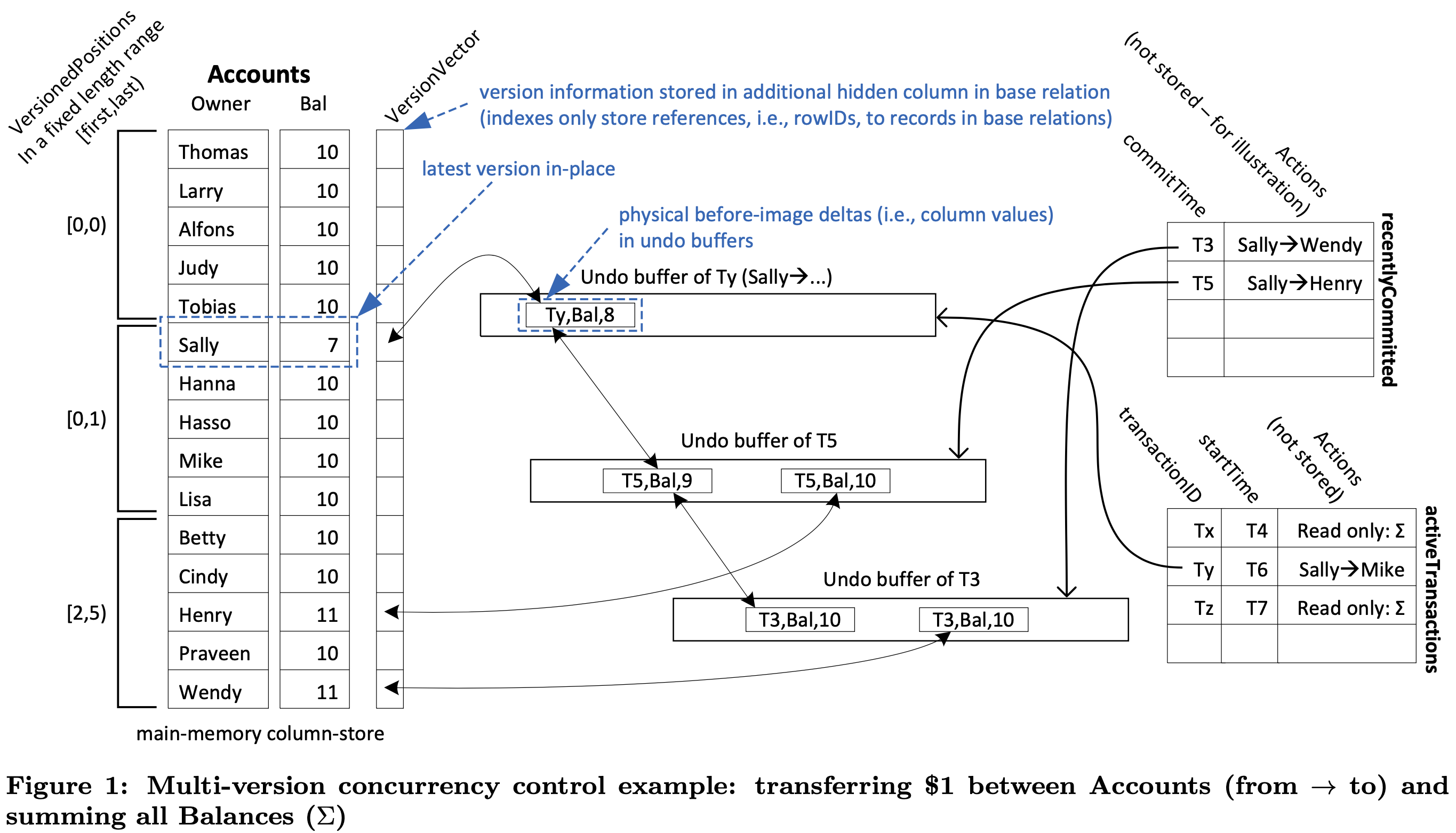
Analysing Snapshot Isolation

This paper (PODC'2016) presents a clean and declarative treatment of Snapshot Isolation (SI) using dependency graphs. It builds on the foundation laid by prior work, including the SSI paper we reviewed recently , which had already identified that SI permits cycles with two adjacent anti-dependency (RW) edges, the so-called inConflict and outConflict edges. While the SSI work focused on algorithmic results and implementation, this paper focuses more on the theory (this is PODC after all) of defining a declarative dependency-graph-based model for SI. It strips away implementation details such as commit timestamps and lock management, and provides a purely symbolic framework. It also proves a soundness result (Theorem 10), and leverages the model for two practical static analyses: transaction chopping and robustness under isolation-level weakening. Soundness result and dependency graph model Let's begin with Theorem 10, which establishes both the soundness and completeness of the...