Disaggregation: A New Architecture for Cloud Databases

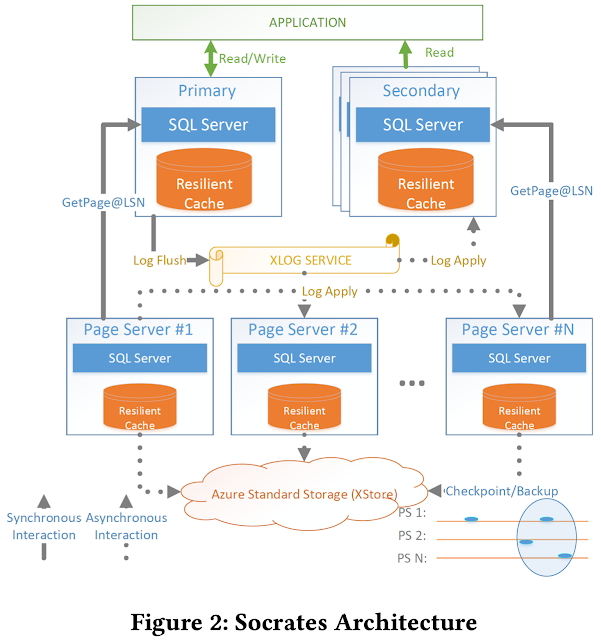
This short VLDB'25 paper surveys disaggregation for cloud databases. It has several insightful points, and I found it worth summarizing. The key advantage of the cloud over on-prem is elastic scalability: users can scale resources up and down and pay only for what they use. Traditional database architectures, like shared-nothing, do not fully exploit this. Thus, cloud-native databases increasingly adopt disaggregated designs. Disaggregation is primarily motivated by the asymmetry between compute and storage: Compute is far more expensive than storage in the cloud. Compute demand fluctuates quickly; storage grows slowly. Compute can be stateless and easier to scale, while storage is inherently stateful. Decoupling them lets compute scale elastically while storage remains relatively stable and cheap. Review of Disaggregation in the Clouds Early cloud-native systems like Snowflake and Amazon Aurora separate compute and storage into independent clusters. Modern systems push dis...