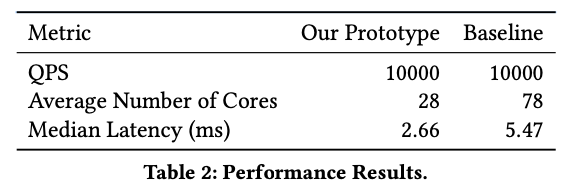
Vive la Difference: Practical Diff Testing of Stateful Applications

This Google paper (to appear in VLDB'25) is about not blowing up your production system. That is harder than it sounds, especially with stateful applications with memories. When rolling out new versions of stateful applications, the "shared, persistent, mutable" data means bugs can easily propagate across versions. Modern rollout tricks (canaries, blue/green deployments) don't save you from this. Subtle cross-version issues often slip through pre-production testing and surface in production, sometimes days or weeks later. These bugs can be severe, and the paper categorizes them as data corruption, data incompatibility, and false data assumptions. The paper mentions real-world incidents from Google and open-source projects to emphasize these bugs' long detection and resolution times, and the production outages and revenue loss they cause. So, we need tooling that directly tests v1/v2 interactions on realistic data before a rollout. The paper delivers a prototype o...