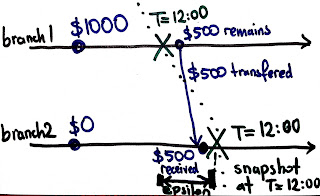
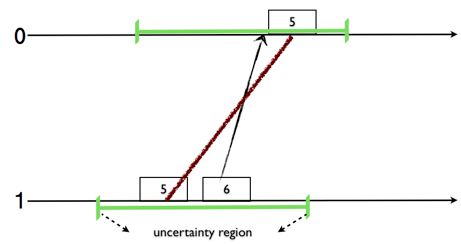
Logical clocks and Vector clocks modeling in TLA+/PlusCal

In a distributed system, there is no shared state, counter, or any other kind of global clock. So we can not implicitly associate an event with its time, because one node may have a different clock than another. Time synchronization is not easy to achieve, and failures complicate things. It turns out we care about time because of its utility in ordering of the events. Using this observation, in 1978, Leslie Lamport offered a time-free definition for "happens before": Event A happens before event B (denoted as A hb B) if and only if A can causally affect B. In the context of distributed systems, A hb B iff 1. A and B are on the same node and A is earlier in computation than B 2. A is the send of a message and B is the receive event for that message 3. There is some third event C, which A hb C, and C hb B. This also suggest the definition for "concurrent" relation. Events A and B are concurrent iff $\neg( A ~hb~ B) \land \neg( B ~hb~ A)$ To capture the hb ...