Transaction models (Chapter 4. Transaction processing book)
Atomicity does not mean that something is executed as one instruction at the hardware level with some magic in the circuitry preventing it from being interrupted. Atomicity merely conveys the impression that this is the case, for it has only two outcomes: the specified result or nothing at all, which means in particular that it is free of side effects. Ensuring atomicity becomes trickier as faults and failures are involved.
Consider the disk write operation, which comes in four quality levels:
- Single disk write: when something goes wrong the outcome of the action is neither all nor nothing, but something in between.
- Read-after write: This implementation of the disk write first issues a single disk write, then rereads the block from disk and compares the result with the original block. If the two are not identical, the sequence of writing and rereading is repeated until the block is successfully written. This has problems due to no abort path, no termination guarantee, and no partial execution guarantee.
- Duplexed write: In this implementation each block has a version number, which is increased upon each invocation of the operation. Each block is written to two places, A and B, on disk. First, a single disk write is done to A; after this operation is successfully completed, a single disk write is done to B. Of course, when using this scheme, one also has to modify the disk read. The block is first read from position A; if this operation is successful, it is assumed to be the most recent, valid version of the block. If reading from A fails, then B is read.
- Logged write: The old contents of the block are first read and then written to a different place (on a different storage device), using the single disk write operation. Then the block is modified, and eventually a single disk write is performed to the old location. To protect against unreported transient errors, the read-after-write technique could be used. If writing the modified block was successful, the copy of the old value can be discarded.
Maybe due to their cost, these atomicity quality handling, they were not implemented. The book says: "Many UNIX programmers have come to accept as a fact of life the necessity of running FSCHK after restart and inquiring about their files at the lost-and-found. Yet it need not be a fact of life; it is just a result of not making things atomic that had better not be interrupted by, for example, a crash."
I guess things improved only after journaled/log-based filesystems got deployed.
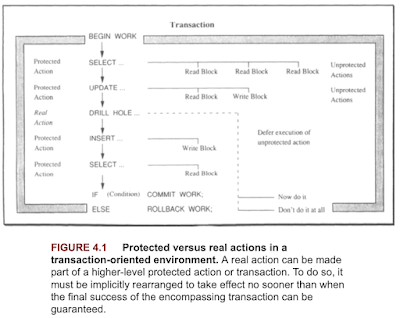
The book looks specifically at how to organize complex applications into units of work that can be viewed as atomic actions. The book provided some guidelines in 4.2.2, with the categorization of unprotected actions, protected actions, and real world actions.
- Unprotected actions. These actions lack all of the ACID properties except for consistency. Unprotected actions are not atomic, and their effects cannot be depended upon. Almost anything can fail.
- Protected actions. These are actions that do not externalize their results before they are completely done. Their updates are commitment controlled, they can roll back if anything goes wrong before the normal end. They have ACID properties.
- Real actions. These actions affect the real, physical world in a way that is hard or impossible to reverse.
The book gives some guidelines.
Unprotected actions must either be controlled by the application environment, or they must be embedded in some higher-level protected action. If this cannot be done, no part of the application, including the users, must depend on their outcome.
Protected actions are the building blocks for reliable, distributed applications. Most of this text deals with them. Protected actions are easier to deal with than Real actions. They can always be implemented in such a way that repeated execution (during recovery) yields the same result; they can be made idempotent.
Real actions need special treatment. The system must be able to recognize them as such, and it must make sure that they are executed only if all enclosing protected actions have reached a state in which they will not decide to roll back. In other words, they suggested using real world actions only after the transaction is checked/committed. When doing something that is very hard or impossible to revoke, try to make sure that all the prerequisites of the critical action are fulfilled.
The book then talks about flat transactions, and defines the ACID components. For isolation, the book emphasizes the client observable behavior. A great paper that revisits isolation from observable behavior is the "Seeing is Believing: A Client-Centric Specification of Database Isolation" paper.
Isolation simply means that a program running under transaction protection must behave exactly as it would in single-user mode. That does not mean transactions cannot share data objects. Like the other definitions, the definition of isolation is based on observable behavior from the outside, rather than on what is going on inside.

As an example of flat transactions, the book gives the classic credit/debit example. Strong smartcontract energy emanates from this SQL program!

The book then considers generalizations of flat transactions, arguing that exaples like trip planning and bulk updates are not adequately supported by flat transactions. The book acknowledges that these generalizations, like chained transactions, nested transactions, generalized transactions, are more of the topic of theory, rather than practice. It says: Flat transactions and the techniques to make them work account for more than 90% of this book. No matter which extensions prove to be most important and useful in the future, flat transactions will be at the core of all the mechanisms required to make these more powerful models work.
It says that this generalization discussion serves a twofold purpose: to aid in understanding flat transactions and their ramifications through explanation of extended transaction models, and to clarify why any generalized transaction model has to be built from primitives that are low-level, flat, system transactions.
This is where we go through the notion of spheres of control, which sounds like the realm of self-improvement books.
The key concept for this was proposed in the early 1970s and actually triggered the subsequent development of the transaction paradigm: the notion of spheres of control. Interestingly, Bjork and Davies started their work by looking at how large human organizations structure their work, how they contain errors, how they recover, and what the basic mechanisms are. At the core of the notion of spheres of control is the observation that controlling computations in a distributed multiuser environment primarily means:
- Containing the effects of arbitrary operations as long as there might be a necessity to revoke them, and
- Monitoring the dependencies of operations on each other in order to be able to trace the execution history in case faulty data are found at some point.
Any system that wants to employ the idea of spheres of control must be structured into a hierarchy of abstract data types. Whatever happens inside an abstract data type (ADT) is not externalized as long as there is a chance that the result might have to be revoked for internal reasons.

This is actually great guideline for writing transactional applications. The book also prescribes about preparing compensating actions for earlier externalized effects. In general, I think it is very beneficial to show more application/pattern recipes for organizing applications into units of work that can be viewed as atomic actions.
The book differentiates between structural and dynamic dependencies. It wasn't clear to me if this differentiation becomes consequential later on. But structural dependencies may become useful for query/transaction planning, and dynamic dependencies for concurrency control.
- Structural dependencies. These reflect the hierarchical organization of the system into abstract data types of increasing complexity.
- Dynamic dependencies. As explained previously, this type of dependency arises from the use of shared data.
The book introduces a graphical notation. I guess it makes for some pretty diagrams. But I would have preferred formal or pseudocode notation.


To settle this problem for the moment, we adopt the following view. If a transaction in the chain aborts during normal processing, then the chain is broken, and the application has to determine how to fix that. However, if a chain breaks because of a system crash, the last transaction, after having been rolled back, should be restarted. This interpretation is shown graphically in Figure 4.11.

Nested Transactions: Nested transactions are a generalization of savepoints. Whereas savepoints allow organizing a transaction into a sequence of actions that can be rolled back individually, nested transactions form a hierarchy of pieces of work.

Distributed Transactions: A distributed transaction is typically a flat transaction that runs in a distributed environment and therefore has to visit several nodes in the network, depending on where the data is. The conceptual difference between a distributed transaction and a nested transaction can be put as follows: The structure of nested transactions is determined by the functional decomposition of the application, that is, by what the application views as spheres of control. The structure of a distributed transaction depends on the distribution of data in a network. In other words, even for a flat transaction, from the application's point of view a distributed transaction may have to be executed if the data involved are scattered across a number of nodes. Distributed subtransactions normally cannot roll back independently, either; their decision to abort also affects the entire transaction. This all means that the coupling between subtransactions and their parents is much stronger in our model.

The book also talks about sagas. The concept is in two respects an extension of the notion of chained transactions:
- It defines a chain of transactions as a unit of control; this is what the term saga refers to.
- It uses the compensation idea from multi-level transactions to make the entire chain atomic.
For all the transactions executed before, there must be a semantic compensation, because the updates have already been committed.
Finally, the spheres of control framework's generality helps think out of the box as well.
Not only Gray has described simulations and chaos engineering, but also event sourcing, in a short off-the-cuff remark. Wondering how many valuable things from that book have gotten overlooked over the years. pic.twitter.com/YCNsp2vppX
— Alex P (@ifesdjeen) February 26, 2024





Comments