Fault tolerance (Transaction processing book)
This is Chapter 3 from the Transaction Processing Book Gray/Reuter 1992.
Why does the fault-tolerance discussion come so early in the book? We haven't even started talking about transactional programming styles, concurrency theory, concurrency control. The reason is that the book uses dealing with failures as a motivation for adopting transaction primitives and a transactional programming style. I will highlight this argument now, and outline how the book builds to that crescendo in about 50 pages.
The chapter starts with an astounding observation. I'm continuously astounded by the clarity of thinking in this book: "The presence of design faults is the ultimate limit to system availability; we have techniques that mask other kinds of faults."
In the coming sections, the book introduces the concepts of faults, failures, availability, reliability, and discusses hardware fault-tolerance through redundancy. It celebrates wins in hardware reliability through several examples, including experience from Tandem computer systems Gray worked on: "This is just one example of how technology and design have improved the maintenance picture. Since 1985, the size of Tandem’s customer engineering staff has held almost constant and shifted its focus from maintenance to installation, even while the installed base tripled. This is an industry trend; other vendors report similar experience. Hardware maintenance is being simplified or eliminated."
As I mentioned in my previous post, I am impressed by the quantitative approach the book takes. It cites several surveys and studies to back up its claims. One question that occurs to me after Section 3.3 is to check whether we see the extrapolation of this trend for new hardware introduced since, and with modern hardware? It seems like we are doing a great job with hardware reliability through isolating/discarding malfunctioning parts and carrying out operations using redundant copies. Well, of course, there are hardware-gray-failures and fail-silent hardware faults that are hard to detect, but we seem to be managing OK overall.
A more interesting question to ask is: "Why are we unable to have the same kind of reliability/maintenance gains for software as easily?" The book acknowledges this is a hard question, again referring to many surveys and case-studies. It sums these up as follows: "Perfect software of substantial complexity is impossible until someone breeds a species of super-programmers. Few people believe design bugs can be eliminated. Good specifications, good design methodology, good tools, good management, and good designers are all essential to quality software. These are the fault-prevention approaches, and they do have a big pay-off. However, after implementing all these improvements, there will still be a residue of problems."
Building on these, towards the end of the chapter, the book makes its case for transactions:
"In the limit, all faults are software faults --software is responsible for masking all the other faults. The best idea is to write perfect programs, but that seems infeasible. The next-best idea is to tolerate imperfect programs. The combination of failfast, transactions, and system pairs or process pairs seems to tolerate many transient software faults."
This is the technical argument.
"Transactions, and their ACID properties, have four nice features:
- Isolation. Each program is isolated from the concurrent activity of others and, consequently, from the failure of others.
- Granularity. The effects of individual transactions can be discarded by rolling back a transaction, providing a fine granularity of failure.
- Consistency. Rollback restores all state invariants, cleaning up any inconsistent data structures.
- Durability. No committed work is lost.
These features mean that transactions allow the system to crash and restart gracefully; the only thing lost is the time required to crash and restart. Transactions also limit the scope of failure by perhaps only undoing one transaction rather than restarting the whole system. But the core issue for distributed computing is that the whole system cannot be restarted; only pieces of it can be restarted, since a single part generally doesn’t control all the other parts of the network. A restart in a distributed system, then, needs an incremental technique (like transaction undo) to clean up any distributed state. Even if a transaction contains a Bohrbug, the correct distributed system state will be reconstructed by the transaction undo, and only that transaction will fail."
First of all, kudos to Gray/Reuter for thinking big, and aiming to addressing distributed systems challenges that would start going big only in 2000s and becoming ever more prominent since then. This is a solid argument in the book, especially from 1990s point-of-view.
With 30+ years of hindsight, we notice couple problems with this argument.
- There are fundamental information horizon limits to distributed transactions (at minimum due to speed of light), and scalability limits (due to contended keys).
- Fail-fast Is Failing... Fast!
What we came to learn with experience is that "it is futile to "paper over the distinction between local and remote objects... such a masking will be impossible" as Jim Waldo famously stated in A Note on Distributed Computing.
So rather than trying to hide these through transactions in the middleware, we need to design end-to-end systems-level and application-level fault-tolerance approaches that respect distributed systems limitations.
Questions / Comments
1. I really liked how Jim Gray tied the software-fault-tolerance to the transactions concept, and presented the all-or-nothing guarantee of transactions as a remedy/enabler for software fault-tolerance (from the 1990 point-of-view). I think crash-only software was also a very good idea. It wasn't extended to distributed systems, but provides a good base for fault-tolerance at the node level. Maybe transactional thinking can be relaxed towards crash-only software thinking and the ideas could be combined.
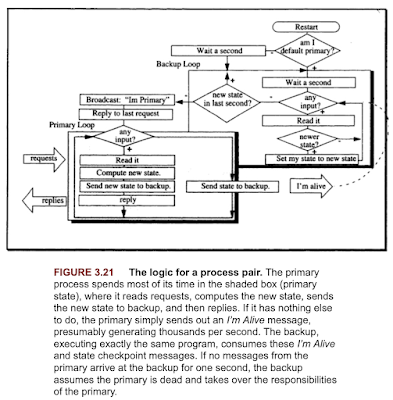
2. The book over-indexes on process-pair approaches with a primary and secondary. "The concept of process pair (covered in Subsection 3.7.3) specifies that one process should instantly (in milliseconds) take over for the other in case the primary process fails. In the current discussion, we take the more Olympian view of system pairs, that is two identical systems in two different places. The second system has all the data of the first and is receiving all the updates from the first. Figure 3.2 has an example of such a system pair. If one system fails, the other can take over almost instantly (within a second). If the primary crashes, a client who sent a request to the primary will get a response from the backup a second later. Customers who own such system pairs crash a node once a month just as a test to make sure that everything is working—and it usually is."
This is expected because distributed consensus and Paxos approaches did not get well-known in 1990. These process-pair approaches are prone to split brain scenarios: where the secondary thinks primary is crashed, and takes over, but the primary is oblivious to this serving requests. There needs to be either leader election build via Paxos (which would require 3 node deployments at minimum), or to use Paxos as the configuration-metadata box to adjudicate over who is the primary and secondary.
3. "To mask the unreliability of the ATMs, the bank puts two at each customer site. If one ATM fails, the client can step to the adjacent one to perform the task. This is a good example of analyzing the overall system availability and applying redundancy where it is most appropriate."
What about today? Are there redundant computers in ATMs today? I think today this is mostly restart based fault-tolerance, no?
4. The old-master, new-master technique in Section 3.1.2 reminded me of the left-right primitive in the Noria paper. Not the same thing, but I think it has similar ideas. And this kind of old-master new-master approach can even be used to provide some kind of tolerance to a poison-pill operation.
5. "Error recovery can take two forms. The first form of error recovery, backward error recovery, returns to a previous correct state. Checkpoint/restart is an example of backward error recovery. The second form, forward error recovery, constructs a new correct state. Redundancy in time, such as resending a damaged message or rereading a disk page, is an example of forward error recovery."
Today we don't hear backward error recovery versus forward error recovery distinction frequently. It sounds like backward recovery is more apt suitable larger recovery/correction. And it seems to me that over time recovery got more finer granular, and forward error recovery become the dominant model. There may have been some convergence and blurring the lines between the two over time.
6. "As Figure 3.7 shows, software is a major source of outages. The software base (number of lines of code) grew by a factor of three during the study period, but the software MTTF held almost constant. This reflects a substantial improvement in software quality. But if these trends continue, the software will continue to grow at the same rate that the quality improves, and software MTTF will not improve."

Do we have a quantitative answer to whether this trend shaped up? Jim Gray had published the paper: "Why Do Computers Stop and What Can Be Done About It?" This 2016 study seems to be a follow up to revisit some of these questions. I think Jim's prediction was correct. For today's systems, software is still the single point of failure for availability/reliability of systems. It also seems like the outages rate continued to shrink significantly.
7. "Production software has ≈3 design faults per 1,000 lines of code. Most of these bugs are soft; they can be masked by retry or restart. The ratio of soft to hard faults varies, but 100:1 is usual." Does anybody know of a recent study that evaluated this and updated these numbers?
8. In Section 3.6.1, the book describes N-version programming: "Write the program n times, test each program carefully, and then operate all n programs in parallel, taking a majority vote for each answer. The resulting design diversity should mask many failures." N-version programming indeed flopped as the book predicted. It was infeasible to have multiple teams develop diverse versions of the software. But with the rise of AI and LLMs, can this be feasible?
9. Is this a seedling of the later RESTful design idea? "There is a particularly simple form of process pair called a persistent process pair. Persistent process pairs have a property that is variously called context free, stateless, or connectionless. Persistent processes are almost always in their initial state. They perform server functions, then reply to the client and return to their initial state. The primary of the persistent process pair does not checkpoint or send I’m Alive messages, but just acts like an ordinary server process. If the primary process fails in any way, the backup takes over in the initial state."
10. Is this a seedling of disaggregated architecture and service-oriented-architecture ideas? "A persistent process server should maintain its state in some form of transactional storage: a transaction-protected database. When the primary process fails, the transaction mechanism should abort the primary’s transaction, and the backup should start with a consistent state."
11. This discussion in Section 3.9 seems relevant for metastable failures. It may be possible to boil metastability failures to state-dis-synchrony problem in the subparts of a system: cache, database, queue, client, etc. "Being out of touch with reality!", this is what Gray calls as system delusion.
"The point of these two stories is that a transaction system is part of a larger closed-loop system that includes people, procedures, training, organization, and physical inventory, as well as the computing system. Transaction processing systems have a stable region; so long as the discrepancy between the real world and the system is smaller than some threshold, discrepancies get corrected quickly enough to compensate for the occurrence of new errors. However, if anything happens (as in the case of the improperly trained clerk) to push the system out of its stable zone, the system does not restore itself to a stable state; instead, its delusion is further amplified, because no one trusts the system and, consequently, no one has an incentive to fix it. If this delusion process proceeds unchecked, the system will fail, even though the computerized part of it is up and operating."
12. "System delusion doesn’t happen often, but when it does there is no easy or automatic restart. Thus, to the customer, fault tolerance in the transaction system is part of a larger fault-tolerance issue: How can one design the entire system, including the parts outside the computer, so that the whole system is fault tolerant?"
I think self-stabilization theory provides a good answer to this question. The theory needs to be extended with control-theory and maybe queueing theory to take care of workload related problems as well.
13. "Most large software systems have data structure repair programs that traverse data structures, looking for inconsistencies. Called auditors by AT&T and salvagers by others, these programs heuristically repair any inconsistencies they find. The code repairs the state by forming a hypothesis about what data is good and what data is damaged beyond repair. In effect, these programs try to mask latent faults left behind by some Heisenbug. Yet, their techniques are reported to improve system mean times to failure by an order of magnitude (for example, see the discussion of functional recovery routines."
This reminds me of the anti-entropy processes used by distributed storage systems.
14. "The presence of design faults is the ultimate limit to system availability; we have techniques that mask other kinds of faults."
I understand the logic behind this, but are we sure there are no fundamental impossibility laws that prohibit perfect availability even when we have perfect design? CAP, FLP, attacking generals impossibility results come to mind. Even without partitions, we seem to have emergent failures and metastability laws. So there may even be another impossibility result there as well involving a tradeoff between scale/throughput and availability of a system. It is possible to build highly available systems but they work within well-known workload and environment environments, so they are not suitable for general computing applications.






Comments