TiDB: A Raft-based HTAP Database
This paper is from VLDB 2020. TiDB is an opensource Hybrid Transactional and Analytical Processing (HTAP) database, developed by PingCap. The TiDB server, written in Go, is the query/transaction processing component; it is stateless, in the sense that it does not store data and it is for computing only. The underlying key-value store, TiKV, is written in Rust, and it uses RocksDB as the storage engine. They add a columnar store called TiFlash, which gets most of the coverage in this paper.
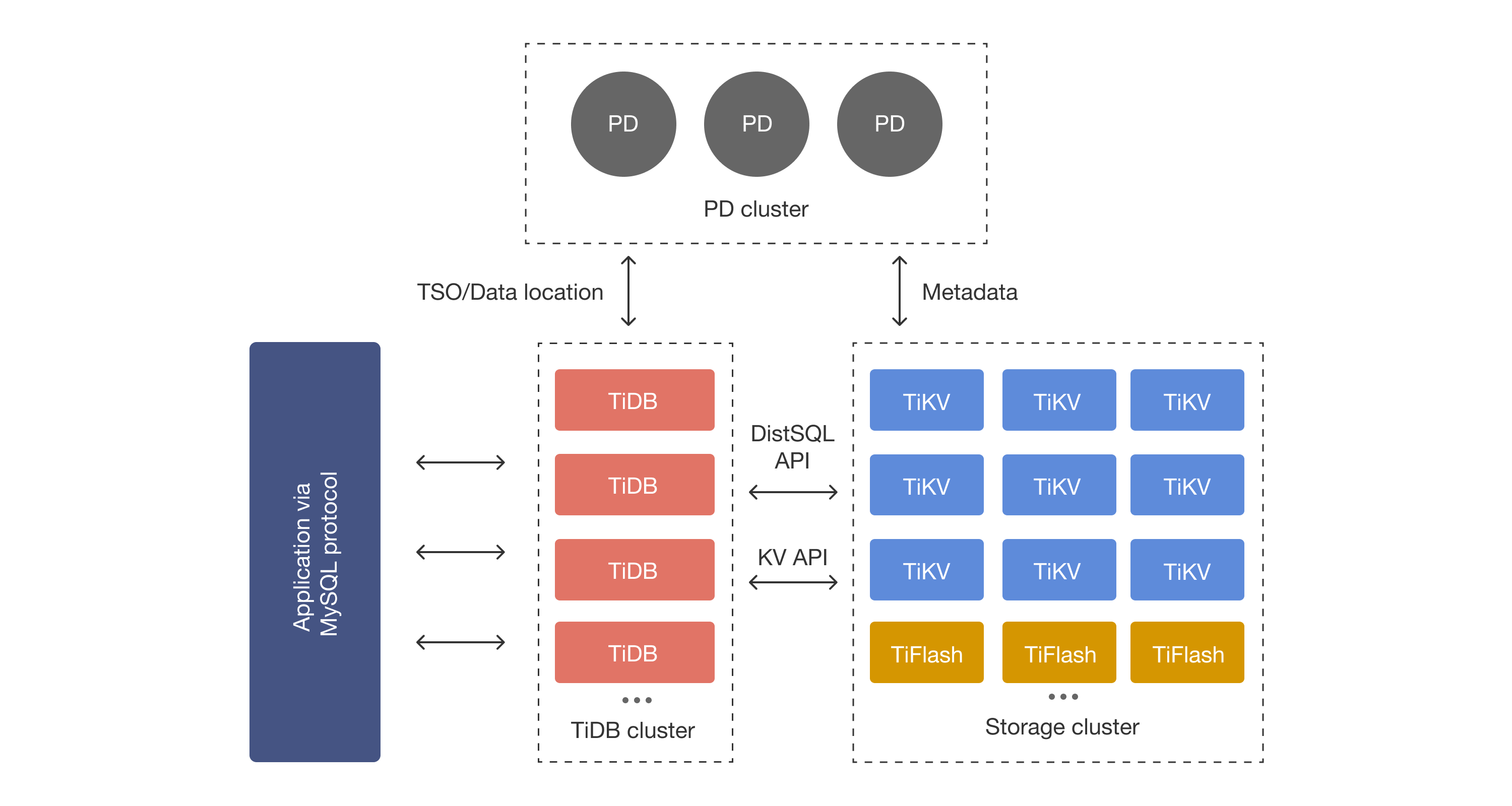
If you know about CockroachDB/CRDB (here is a refresher), below is my attempt to provide quick context to orient you to understand what TiDB is about. Yeah, the formulas are somewhat silly, but bear with me.
TiDB = CRDB - PostGres + MySQL
TiDB is MySQL compatible and features horizontal scalability, strong consistency, and high availability.
The word compatible does some heavy-lifting here. The TiDB architecture does not look anything like that of MySQL. TiDB is driver compatible with MySQL. It misses many features of MySQL, including support for stored procedures. But it does provide hassle-free automatic partitioning/scaling, which MySQL did not have.
TiDB = CRDB - GeoDistribution
Like CRDB, TiDB uses Raft replicasets to maintain the SMR replication of the database in 96Mb (by default) range shards. The paper calls ranges as regions, which is a terribly confusing word to use, as the concept has nothing to do with geographical regions. As far as I can see TiDB is single-region. TimeStampOracle (TSO) is centralized and it needs to be modified to allow multi-region. Same deal with the Placement Driver (PD).
TiDB = CRDB - Serializability + SnapshotIsolation
TiDB provides ACID transactions with snapshot-isolation (SI), in other words with repeatable read (RR) semantics. It also allows for read committed (RC) configuration for transactions. (Here is a refresher on SI.) The implementation is based on multi-version concurrency control (MVCC), and avoids read locking and protects against write-write conflicts. Their transactional protocol is very similar to CRDB: it selects one key as the primary key and uses it to stand for the status of a transaction, and employs two-phase-commit (2PC) to conduct transactions. The only difference I can see is that TiDB also has an OCC version of the key locking, in addition to the pessimistic locking CRDB uses. (See figure below.) The OCC locking version gives better throughput at low-conflict workloads.

TiDB = CRDB + Columnar
TiDB's claim to innovation is adding, in addition to, its OLTP row-based storage, a columnar storage via Raft learner to provide OLAP without effecting the performance of OLTP transactions. Evaluations aim to show how their OLTP system is performance-isolated from the OLAP queries they execute on the columnar part of the database. The store format of columnar data in TiFlash is similar to Parquet and stores row groups into columnar chunks. They use B+-tree for merging Raft updates to TiFlash columnar store, rather than using LSM. They say this is better for reading is concerned, and the write amplification (16 versus 4.7) is acceptable for them. The paper does not elaborate more on this unfortunately.

For the HTAP discussion (HTAP = OLTP + OLAP), the paper makes an up front assertion in the abstract without evidence or argument to back this up in the rest of the paper: "Hybrid Transactional and Analytical Processing (HTAP) databases require processing transactional and analytical queries in isolation to remove the interference between them. To achieve this, it is necessary to maintain different replicas of data specified for the two types of queries." It would be interesting to research this question.


The evaluation is done on big machines, but there are only six of them. TiDB is minimizing the distributed part of the distributed-SQL. "We perform comprehensive experiments on a cluster of six servers; each has 188 GB memory and two Intel Xeon CPU E5-2630 v4 processors, i.e., two NUMA nodes. Each processor has 10 physical cores (20 threads) and a 25 MB shared L3 cache. The servers run Centos version 7.6.1810 and are connected by a 10 Gbps Ethernet network."
On the OLTP front, they say TiDB achieves slightly better performance than CRDB, and this is "due to optimization of transaction processing and the Raft algorithm." This is again unjustified by experiments. How do we know that difference doesn't come from using SI instead of SER isolation?

I found the writing and organization of the paper lacking somewhat, but this doesn't interfere with comprehension. I also found several things odd in presentation stylistically. There isn't a good separation of what is newly introduced with TiDB, and what has already been there before. An example is the Raft learner discussion in Section 2.





Comments