Take Out the TraChe: Maximizing (Tra)nsactional Ca(che) Hit Rate
This paper appeared in OSDI 2023 in July, and is authored by Audrey Cheng, David Chu, Terrance Li, Jason Chan, Natacha Crooks, Joseph M. Hellerstein, and Ion Stoica, UC Berkeley; Xiangyao Yu, University of Wisconsin--Madison.
The paper seems to break the acronym rule. It defines one acronym, TraChe, in the title, but uses another one, Detox, for the rest of the paper. I guess I agree, referring to your system as Trache is not very appealing.
I kid, because I love the authors. Looks like I cover almost any paper Audrey Cheng writes these days. Speaking of Audrey, she had written a brief summary of this paper here: https://audreyccheng.com/blog/transaction-caching. Hmm, she didn't use the word "TraChe" in her post even once. I wonder which one of the advisors on the paper coined the typo TraChe, and pushed it to the title.
Ok, enough with the trache talk.
The Problem
You have been doing caching wrong for your transactional workloads!
That is the main message of this paper, which it lays out nicely in the first paragraph.
On a production workload from Meta, we find that up to 90% of objects cached by least recently used (LRU) and least frequently used (LFU), two popular caching algorithms, do not have any impact on latency despite high object hit rates (see Figure 2a). Existing policies fail to capture the all-or-nothing property of transactions: all objects requested in parallel must be present in cache, or there will be little performance improvement because latency is dictated by the slowest access.

If you like to understand why traditional single-object based caching approaches fail to work for transactional workloads, consider this simple example in Figure 1. GetLinkedAccounts returns secondary bank accounts a2 and a3 linked with a primary account a1. This transaction must first read a1 before accessing both secondary accounts a2 and a3 in parallel. Thus, a1, a2 and a3 are all on the longest path of the transaction. If we cache a1, we can reduce the end-to-end latency of the transaction. However, if we additionally cache a2, the overall latency does not improve because we still need to access a3 from disk.
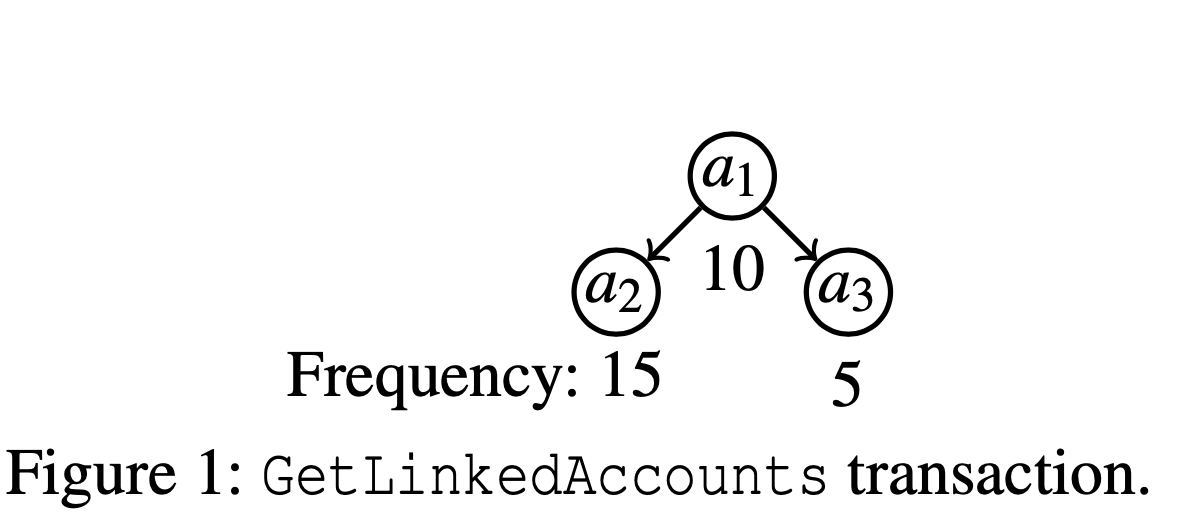
Consider a situation in which, over all transactions, a2 is more frequently accessed than a1 and a3. LFU and LRU would choose to evict a1 and a3 over a2, resulting in no latency improvement for this transaction. In this case, a “hot” (frequently accessed) key a2 is requested in parallel alongside a “cold” (rarely accessed) key a3. If all accesses of a2 are sent in parallel with requests to different cold keys, there is no benefit to caching a2 unless all these cold keys are cached.
So stop with the busy work that doesn't improve the bottomline for your transactional workloads.
The Solution
In contrast to the single-object caching algorithms that focus on maximizing object hit rate to decrease load to the data store, DeToX prioritizes a new metric: "transactional hit rate". A transactional hit occurs when the length of non-cached, sequential accesses in a transaction is reduced by one.
Intuitively, the transactional hit rate represents how often the groups of keys accessed in parallel by transactions are available in cache. To optimize transactional hit rate, DeTox focuses its caching policy around scoring groups of keys together. To this end, DeToX scores groups of keys within transactions and averages group scores to compute individual key scores.

Here is the formula for scoring a group in a single transaction.
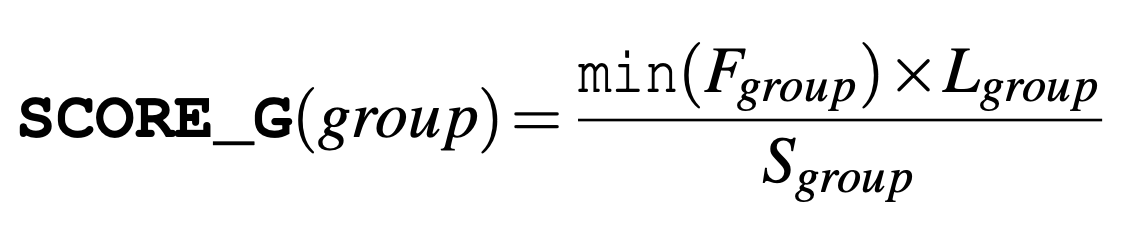
L_group is the transactional hits of the group, and captures the critical length reduction when caching this group. And S_group is the sum sizes of the keys in the group and enters the formula as an inverse factor.

of time (due to their high frequencies) and to make room for newly
popular objects from being stored.
Note that this approach also ends up scoring the individual objects in these groups to denote which objects to store in the cache. This is by design. This way they achieve compatibility with existing caching systems, such as Memcached and Redis, so that the DeTox approach can be easily deployed part of these systems.
The runtime solution
Grouping requires access to transaction dependency graphs, which are typically extracted via static analysis from application code. This information may not always be available. But worry not, there is a shortcut approximation protocol to dynamically infer groups by considering requests sent in parallel by a transaction to be a group.

Evaluation
The DeTox code, as well as evaluation code, is accessible from: https://github.com/audreyccheng/detox
DeTox provides significant performance improvements on an experimental setup using Redis as the cache over a database of either Postgres or TiKV. To keep the runtime costs low, they use the following strategy, which is also used in Redis. When an eviction is needed, they score 10 random samples and choose one to evict among these candidates.

Overall, DeTox achieves up to 1.3x increase in transaction hit rate and 3.4x improvement in cache efficiency over these benchmarks. This translates into up to 30% improvements in throughput and latency for Redis-Postgres setup.
Conclusions
You are doing caching wrong for transactions, and this paper shows how to improve things. (By the way, this observation and solution also applies to prefetching for your transactional workloads.)
The Chicago Paper Writing guide argues this is how you should be writing academic papers.
By all accounts this is a really well written paper. Well, except for that lousy acronym. Seriously Audrey, who came up with "TraChe"? You don't have to take the fall for one of your advisors. Give us the name. People want to know.
Update: from Audrey.



Comments