The end of a myth: Distributed transactions can scale
This paper appeared in VLDB'17. The paper presents NAM-DB, a scalable distributed database system that uses RDMA (mostly 1-way RDMA) and a novel timestamp oracle to support snapshot isolation (SI) transactions. NAM stands for network-attached-memory architecture, which leverages RDMA to enable compute nodes talk directly to a pool of memory nodes.

Remote direct memory access (RDMA) allows bypassing the CPU when transferring data from one machine to another. This helps relieve a major factor in scalability of distributed transactions: the CPU overhead of the TCP/IP stack. With so many messages to process, CPU may spend most of the time serializing/deserializing network messages, leaving little room for the actual work. We had seen this phenomena first hand when we were researching the performance bottlenecks of Paxos protocols.
This paper reminds me of the "Is Scalable OLTP in the Cloud a Solved Problem? (CIDR 2023)" which we reviewed recently. The two papers share one author. I think this earlier NAM paper is more mature in terms of implementation details and evaluation. In contrast the CIDR'23 paper concentrated on explaining the benefits of using multi-writer shared memory architecture and reads more like a position paper, with some discussion of the ScaleStore idea. Both papers use RDMA as a key enabler for scalable distributed transactions, but they differ in how they leverage it. NAM-DB uses RDMA mainly for one-sided operations to access remote memory servers, while shared-writer with coherent cache uses RDMA mainly for two-sided operations to implement cache coherence protocols. Both papers aim to support snapshot isolation (SI) transactions, but they differ in how they handle concurrency control and version management: NAM-DB uses a compare-and-swap operation to lock and install new versions of records on memory servers, while shared-writer with coherent cache uses a cache invalidation protocol to ensure consistency of cached records on compute servers.
System design
RDMA-enabled networks transforms the system to a hybrid shared-memory and message-passing architecture: it is neither a distributed shared-memory system (as several address spaces exist and there is no cache-coherence protocol), nor is it a pure message-passing system since memory of a remote machine can be directly accessed via RDMA reads and writes.

The data is assumed to be randomly distributed to memory nodes in the shared memory pool. Any memory node is equi-distant to any compute node, and a compute node needs to reach multiple memory nodes for transaction execution. All transactions are by default distributed transactions. Where the data is located is not a primary point of optimization in the NAM architecture. This is the second design principle in NAM: Data Location Independence. I like this data location independence idea for its built-in tolerance to workload skew.
Locality is only a tuning parameter for optional/additional optimization, and may be achieved by running a specific compute server and memory server on the same physical machine.
Snapshot Isolation (SI) transaction execution


For executing a transaction, the compute server first fetches the read-timestamp rts using an RDMA read (step 1 in Figure 2, line 3 in Listing 1). The rts defines a valid snapshot for the transaction. Then, the compute server executes the transaction, which means that the required records are read remotely from the memory servers using RDMA read operations (e.g., the record with ckey = 3 in the example) and updates are applied locally to these records; i.e., the transaction builds its read- and write-set (step 2 in Figure 2, line 5 in Listing 1). Once the transaction has built its read- and write-set, the compute server starts the commit phase.
For committing, a compute server fetches a unique commit timestamp (cts) from the memory server (step 3 in Figure 2, line 7 in Listing 1). Then, the compute server verifies and locks all records in its write-set on the memory servers using one RDMA compare-and-swap operation (line 10-15 in Listing 1). The main idea is that each record stores a header that contains a version number and a lock bit in an 8-Byte memory region. For example, in Figure 2, (3, 0) stands for version 3 and lock-bit 0 (0 means not locked). The idea of the compare-and-swap operation is that the compute server compares the version in its read-set to the version installed on the memory-server for equality and checks that the lock-bit is set to 0. If the compare succeeds, the atomic operation swaps the lock bit to 1 (step 4 in Figure 2, line 13 in Listing 1).
If compare-and-swap succeeds for all records in the write-set, the compute server installs its write-set using RDMA writes (line 19-20 in Listing 1). These RDMA writes update the entire record including updating the header, installing the new version and setting the lock-bit back to 0. For example, (6, 0) is remotely written on the header in our example (step 5 in Figure 2). If the transactions fails, the locks are simply reset again using RDMA writes (line 24-28 in Listing 1).
Finally, the compute server appends the outcome of the transaction (commit or abort) as well as the commit timestamp cts to a list (ctsList) in the memory server (step 6 in Figure 2, line 32 in Listing 1).
Timestamp oracle
In the above protocol, a timestamp oracle is responsible for advancing the read timestamp by scanning the queue of completed transactions. It scans ctsList and tries to find the highest commit timestamp where every transaction before that timestamp is also committed.
The bottleneck-free implementation of this timestamp oracle is of interest as an example of how a global synchronization/contention register can be partitioned into a one-way-RDMA amenable data structure. This is the third design principle in NAM: Partitionable Data Structures.
The timestamp oracle protocol uses a timestamp vector (as in vector clocks) to store the latest commit timestamp for each compute server transaction execution thread.
- When a transaction starts, the compute server reads the entire timestamp vector from a memory server and uses it as its read timestamp.
- When a transaction commits, it creates a new commit timestamp by incrementing its own counter in the timestamp vector. It then verifies and locks all records in its write-set on the memory servers using RDMA compare-and-swap operations. If the verification succeeds, it installs its write-set using RDMA writes and updates its counter in the timestamp vector using RDMA write. If the verification fails, it aborts and releases the locks using RDMA writes.
The timestamp oracle is responsible for advancing the read timestamp by scanning the timestamp vector and finding the highest commit timestamp that is preceded by all committed transactions. This allows other transactions to read more recent snapshots of the database.
I think synchronized clocks would be a more practical solution to the timestamping problem. If you are using special hardware for RDMA, why not get hardware support (which is very feasible these days) for synchronized clocks as well. When using synchronized clocks, how would the read timestamp be advanced? Simple, by the current clock at the compute node at transaction's start, T-start. The transaction will then read anything that has committed before its transaction start, T-start, as a consistent snapshot.
Implementation
The table and index structures are designed to be partitionable and scalable. The table structure uses a hash-based partitioning scheme that maps each record to a fixed-size slot in a memory region. The index structure uses a B+tree that is partitioned by key ranges and stored in separate memory regions. Both structures use RDMA operations to access and update data on memory servers.
A database catalog is implemented such that transactions can find the storage location of tables and indexes. The catalog data is hash-partitioned and stored in memory servers. All accesses from compute servers are implemented using two-sided RDMA operations since query compilation does not result in a high load on memory servers when compared to the actual transaction execution. Since the catalog does not change too often, the catalog data is cached by compute servers.
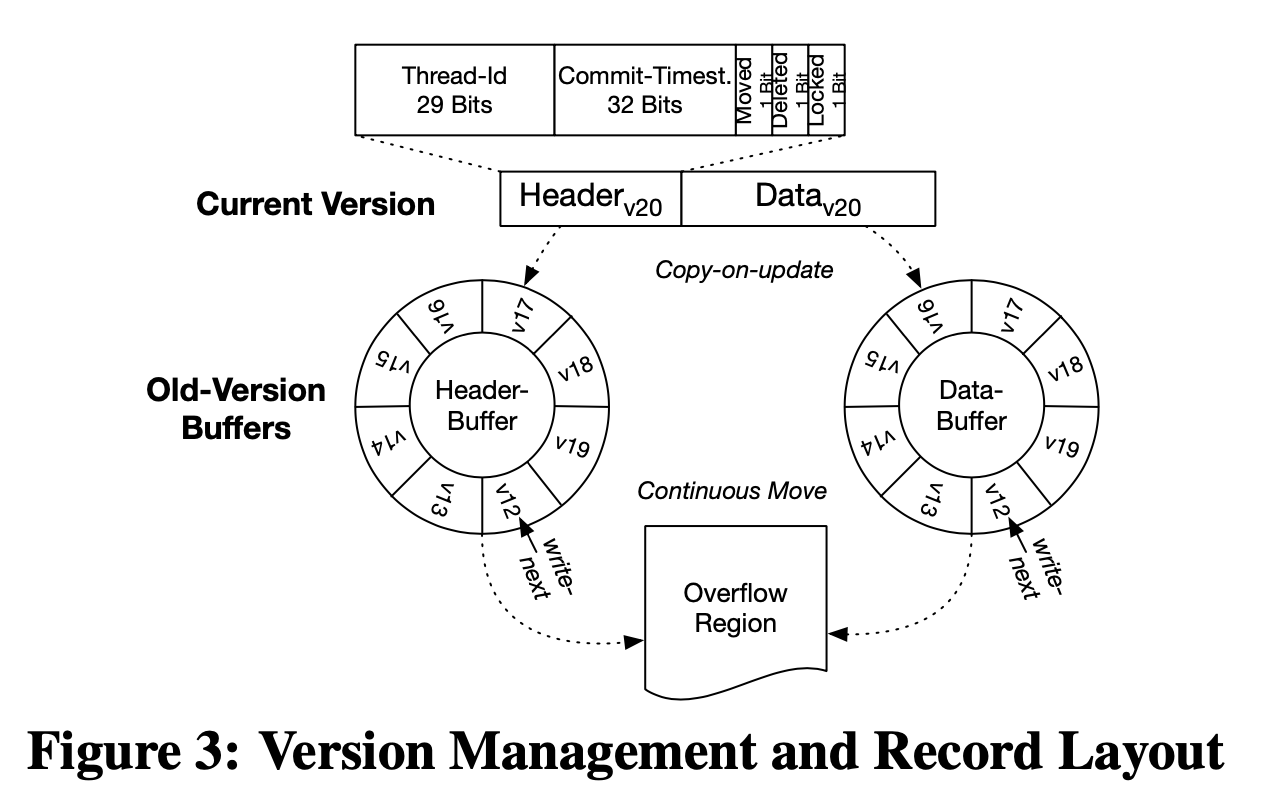
In order to tolerate memory server failures, each transaction execution thread of a compute server writes a private log journal to memory servers using RDMA writes. The log entries for all transaction statements are written to the database log before installing the write-set on the memory servers. Once a memory server fails, NAM-DB halts the complete system and recover all memory servers to a consistent state from the last persisted checkpoint. The recovery procedure is executed by one dedicated compute server that replays the merged log for all memory servers.
This global stall is problematic for production, but NAM is a research proof-of-concept system. Maybe using redundancy/quorums would be a way to solve this, but then that could be introducing challenges for consistency. Not straightforward.
Evaluation
The experimental setup involves using a cluster of 56 machines connected by an InfiniBand FDR network, and running the TPC-C benchmark with different configurations and workloads.


The scalability results show that NAM-DB achieves linear scale-out for throughput while keeping a low latency, and outperforms other RDMA-based systems such as FaRM. For the standard configuration of TPC-C benchmark, they show that NAM-DB scales linearly to over 3.6 million new-order transactions per second on 56 machines, and 6.5 million new-order transactions with locality optimizations, which is 2 million more transactions per second than what FARM achieves on 90 machines.
Discussion
1. Why is SI important for NAM? Why would this not work for serializable isolation? I am not complaining about the use of SI, it makes sense and it is the overwhelming use in real world. I think this question is interesting to get insights about distributed transactions design and implementation.
2. It beats me why we are not leveraging on new hardware more for distributed systems and databases. I don't think the issue is the cost of the hardware. Is RDMA mature (robust/reliable) enough to use in distributed transactions? What are the handicaps? What are the reasons for slow uptake on this?





Comments