Aria: A Fast and Practical Deterministic OLTP Database
This paper is from VLDB2020. Aria is an OLTP database that does epoch-based commits similar to the Silo paper we discussed last week. Unlike Silo, which was a single-node database, Aria is a distributed and deterministic database. Aria's biggest contribution is that it improves on Calvin by being able to run transactions without prior knowledge of read and write sets. Another nice thing in Aria is its deterministic re-ordering mechanism to commit transactions in an order that reduces the number of conflicts. Evaluation results on YCSB and TPC-C show that Aria outperforms other protocols by a large margin on a single node and up to a factor of two on a cluster of eight nodes.
Aria versus Calvin
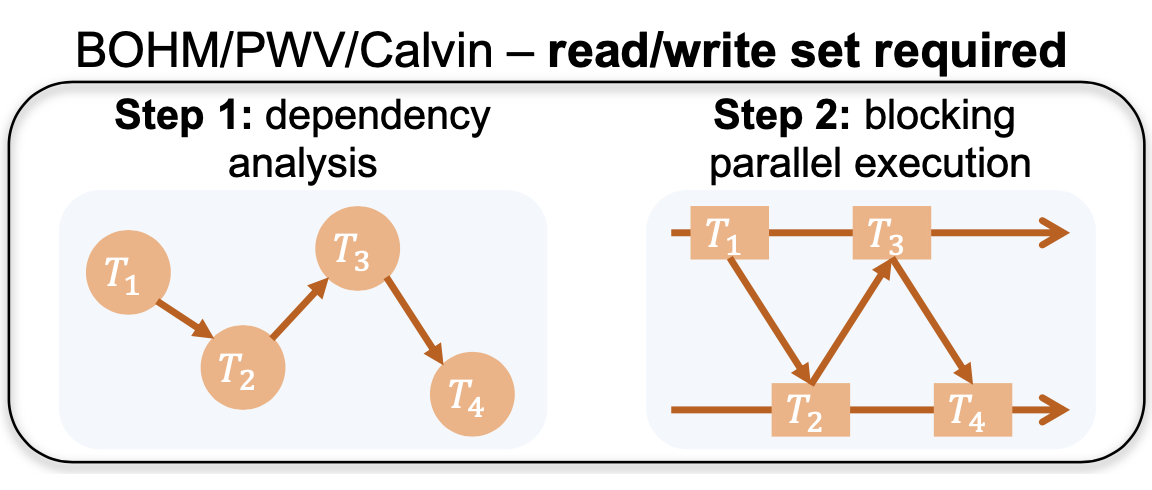
Recall that Calvin uses locks (here is a summary of the Calvin paper). The key idea in Calvin is that read/write locks for a transaction are acquired according to the ordering of input transactions and the transaction is assigned to a worker thread for execution once all needed locks are granted. In other words, Calvin (and other existing deterministic databases) perform dependency analysis before transaction execution, and this requires that the read/write set of a transaction be known a priori.

In Aria, a previous batch of transactions must finish executing before a new batch can begin, since a barrier exists across batches. So it is important to avoid a long running transaction to stall the entire batch.
This is too high level a picture, so let's talk about the execution phase and commit phase of each batch in detail next.
Execution phase
Each transaction in a batch first passes through a sequencing layer and is assigned a unique transaction ID (TID). The TID indicates a total ordering among transactions. By default this indicates the commit order of transactions, but we will describe the deterministic reordering technique, which may commit transactions in a different order when it is safe to do so in order to improve throughput.
During the execution phase, each transaction reads from the current snapshot of the database, executes its logic, and writes the result to a local write set. (The batch of transactions all reading from the same snapshot implies that Read-After-Write conflicts should be avoided.) Since the changes made by transactions are kept locally and are not directly committed to the database, the snapshot read by each transaction in the execution phase is always the same. Once a transaction finishes execution, it goes through its local write set and makes write reservations for each entry in its write set.
The write reservations table is used so that Write-After-Write conflicts are avoided as well. This works as follows. A write reservation on a previously reserved value can be made only when the reserving transaction has a smaller TID than the previous reserver. If a reservation from a larger TID already exists, the old reservation will be voided and a new reservation with the smaller TID will be made. If a transaction cannot make a reservation, the transaction must abort.
Commit phase
In order to achieve serializability, the commit phase checks its transaction whether it has a Read-After-Write (RAW) or Write-After-Write(WAW) conflict with an earlier transaction.
Aria doesn't care about Write-After-Read WAR dependencies because it is safe for a transaction to update some record that has been read by some other transaction because the reads come from a snapshot state as part of batching epochs. (In the reordering transactions section below, we will discuss how we can use this for our advantage.)
Rule 1. A transaction commits if it has no WAW-dependencies or RAW-dependencies on any earlier transaction.

Deterministic reordering
To improve throughput, the deterministic reordering algorithm reduces aborts by transforming RAW-dependencies to WAR-dependencies to leverage the fact that Aria does not require aborts for WAR-dependencies.
Consider the following three transactions: T1: y=x, T2: z=y, and T3: Print (y+z)
Following Rule 1, only transaction T1 can commit, since both transaction T2 and T3 have RAW-dependencies. However, if we reorder them as T3, T2, T1, we can commit all three transactions in a serializable fashion.
Rule 2 shows when it is safe to do this reordering.
Rule 2. A transaction commits if two conditions are met: (1) it has no WAW-dependencies on any earlier transaction, and (2) it does not have both WAR-dependencies and RAW-dependencies on earlier transactions with smaller TIDs.

Fallback strategy
Transactions that have WAW-dependencies are always aborted in Aria and will be re-executed in the next batch. For a high-conflict workload, this will reduce throughput significantly. But Aria adopts a fallback strategy when a workload suffers from a high abort rate due to WAW-dependencies. The fallback phase runs at the end of the commit phase and re-runs aborted transactions following the dependencies between conflicting transactions.
Note that each transaction knows its complete read/write set when the commit phase finishes. The read/write set of each transaction can be used to analyze the dependencies between conflicting transactions. Therefore, many conflicting transactions do not need to be rescheduled in the next batch. Instead, Aria can employ the same mechanism as in existing deterministic databases to re-run those conflicting transactions. In particular, Aria uses an approach similar to Calvin. In the fallback phase, some worker threads work as lock managers to grant read/write locks to each transaction following the TID order. A transaction is assigned to one of the available worker threads, and executes against the current database (i.e., with changes made by transactions with smaller TIDs) once it obtains all locks. After the transaction commits, it releases all locks. As long as the read/write set of the transaction does not change (as Calvin dictates) the transaction can still commit deterministically in this fallback phase. Otherwise, it will be scheduled and executed in the next batch in a deterministic fashion.
Implementation
Transactions are run as stored procedures implemented in C++. The system targets one-shot and short-lived transactions and does not support multi-round and interactive transactions. Aria does not provide a SQL interface, but it could be added.
Each table has a primary key and some number of attributes. Tables are currently implemented as a primary hash table and zero or more secondary hash tables as indexes, meaning that range queries are not supported. This could be easily adapted to tree structures (remember Silo and MassTree).
The paper does not mention it, but I found a GitHub repo for this paper at https://github.com/luyi0619/aria
Evaluation
Evaluations are done using YCSB and TPC-C workloads. They ran experiments on a cluster of m5.4xlarge nodes running on Amazon EC2. Each node has 16 2.50 GHz virtual CPUs and 64 GB RAM running 64-bit Ubuntu 18.04 with Linux kernel 4.15.0 and GCC 7.3.0. The nodes are connected with a 10 GigE network.
Single node evaluation results are as follows.

Results from distributed transactions running on multiple nodes are shown next.

Conclusions
The paper had sloppy writing in a couple sections. The nondeterministic versus deterministic databases comparison in Section 2.1 committed big gaffes by conflating atomic commitment across partitions (which uses 2PC) with replication within a partition (which mostly uses logs). Section 2.2 says this: "In nondeterministic databases, 2PC is used to ensure that the participants in a distributed transaction reach a single commit/abort decision. In contrast, the failure of one participating node does not affect the commit/abort decision in deterministic databases." That is not true. Deterministic databases also get blocked if they can't access the data they need due to failure. And a single failure requires recovery for that epoch, and blocks progress until recovery is finished. I read the fault-tolerance section to see if these were discussed, but that section was disappointing and didn't provide any resolution to this. It boiled down to just one sentence saying that fault-tolerance comes from re-running aborted transactions. There is no description of recovery procedure at all. The paper also lacks an architecture diagram for Aria to show how the parts fits in place.
These being said, overall I like the paper. The paper shows that deterministic databases are greater than just Calvin. The definition of deterministic databases is admissive, and Aria with OCC also qualifies here. I like the approach of working from snapshot in epochs. Yes, this increases latency, but you get very good throughput, efficiency, scalability characteristics as a result. The RAW to WAR transformation trick (which comes with this epoch based model) was very interesting to me as well.





Comments