Polyjuice: High-Performance Transactions via Learned Concurrency Control (OSDI'21)
This paper appeared in OSDI 2021. I really like this paper. It is informative, it taught me new things about concurrency control techniques. It is novel, it shows a practical application of simple machine learning to an important systems problem, concurrency control. It shows significant benefits for a limited but reasonable setup. It has good evaluation coverage and explanation. It is a good followup paper to the benchmarking papers we have been looking at recently.
So let's go on learning about how Polyjuice was brewed.
Problem and motivation
There is no supreme concurrency control (CC) algorithm for all conditions. Different CC algorithms return the best outcome under different conditions. Consider two extreme CC algorithms. Two phase locking (2PL) waits-for every dependent transactions to finish. Optimistic concurrency control (OCC) don't track or wait for any dependent transaction but validate at the end. We find that OCC is better with less contention, because it avoids unnecessary overhead, and 2PL is better under high contention, because it avoids wasted work due to late aborts.
There are so many published CC algorithms that fall somewhere between 2PL and OCC in terms of how they treat dependent transactions. For example, IC3, CALLAS RP, and DRP make the transaction wait until dependent transactions finish execution upto a certain point, determined by applying a static analysis of the transaction workload. To warrant publication, each CC paper most likely showed an evaluation where it beats others. So I wonder if this conjecture holds: For each CC algorithm X, there exists a workload that X is better than other CC algorithms.
Under these circumstances, the natural thing to do is to use a hybrid CC algorithm that would mix&match different OCC policies to do better for a given workload. There have been federated CC approaches like Tebaldi and Cormcc, that manually partition data and use a specific CC within each partition. But that is still somewhat coarse-grained. There had been finer-grained approaches, like IC3, CALLAS RP, and DRP, that decompose each transaction and pipeline the execution of these pieces guided by static analysis of the transaction workload.
Going one step further, can we use a CC can that shape-shift to use any policy that would help maximize throughput by learning from the access patterns in this workload? That is what this paper investigates. The framework has a clever name, Polyjuice. In the Harry Potter universe, Polyjuice is a potion that allows the drinker to assume the form of someone else.
Instead of choosing among a small number of known algorithms, Polyjuice searches the "policy space" of fine-grained actions by using evolutionary-based reinforcement learning and offline training to maximize throughput. Under different configurations of TPC-C and TPC-E, Polyjuice can achieve throughput numbers higher than the best of existing algorithms by 15% to 56%.
Polyjuice is designed for a single node multicore setup. It assumes, all transaction types are known beforehand, and available to run as stored procedures (see the policy table section below). It does not support MVCC, due to its implementation being on top of the Silo framework. Polyjuice code is available at https://github.com/derFischer/Polyjuice
OK, let's now dive into the secret sauce.
CC algorithm space

Table 1 decomposes existing elemental cc algorithms to a set of parameters. The Polyjuice design, which we cover in the next section, uses these as the policy parameters to tweak.
There are three major categories.
- Read Control policies: waiting for dependencies and which version (committed or uncommitted) to read.
- Write Control policies: waiting for dependencies and whether or not to make this write visible to the future reads of other transactions.
- Policies for validation of transactions
- When to validate: A transaction may validate its accesses at any time during execution, instead of only at commit time. Early validation can abort a transaction quicker to reduce wasted work.
- Validation method: commit timestamp based or dependency graph-based
Silo
I want to open a side-bar for Silo here: "S. Tu, W. Zheng, E. Kohler, B. Liskov, and S. Madden. Speedy transactions in multicore in-memory databases. SOSP, 2013." Although Silo is not given in Table 1, Polyjuice builds heavily on Silo. Polyjuice uses Silo's validation/commit algorithm, and derives its correctness from this algorithm. Since Polyjuice uses Silo's validation/commit check, any transaction that Polyjuice commits is a transaction that Silo would commit. Since Silo safe, Polyjuice should also be safe as well. Polyjuice then focuses on improving performance, having offloaded correctness to Silo's validation procedure. Silo's key contribution has been this commit/validation protocol based on OCC that provides serializability while avoiding all shared-memory writes for records that were only read.
Polyjuice is implemented in C++ using the codebase of Silo by just replacing Silo's concurrency control mechanism with Polyjuice’s policy-based algorithm. Polyjuice also relies on Silo's snapshot based execution to serve read-only transactions. I guess Silo is an OCC based algorithm.
Polyjuice design

For each data object, Polyjuice stores the latest committed data as well as a per-object access list. The access list contains all uncommitted writes that have been made visible, as well as read accesses. Polyjuice uses a pool of workers that run concurrently: each worker executes a transaction according to the learned policy table lookup for the CC fine-grained actions/policies to follow.
The learned policy table has been trained offline. We next look at the format of this learned policy table.
Policy table

In the policy table, each column is a look up of a policy action to apply. I.e., there are as many columns as there are action dimensions.
Each row is a state in the possible set of states the system can be in. I.e., there are as many rows in the policy table as there are different states. This state space consists of cartesian product of the type of transaction (remember we know all transaction types in advance, as they are stored-procedures in our system) and the access-id the transaction is executing (the static code location in the transaction that invokes the read/write access).
The column/action space consists of four types of columns/actions: wait action, read-version, write-visibility, early validation. The last three columns are booleans, where as the wait-action columns contain an integer for a multi-valued action (e.g. how to wait for dependent transactions).
The OSDI21 presentation explains the policy table and the lookup really nicely. It is worth checking it to see how this description gets realized visually with examples.
The limitation of this policy table is the assumption that each transaction type is known in advanced and as available as stored procedures. But I think this approach would also work when allowing some other improvised online transactions from the users. This would of course reduce the performance and throughput benefits of the approach, but the correctness would still be there due to Silo-style validation check. So there is some flexibility to generalize this way, I think.
Training
The policy table is learned by offline training on the workload using reinforcement learning with an evolutionary approach. The learning starts by the creation of an initial population of policies. Then we test the throughput of each policy, select 8 policies to go to next round. We then mutate each of these 8 policies in 4 different ways to get a total of 5 variations (including the original) per policy. The mutation is done by flipping bools, varying the integer value from interval, etc. This testing and mutation is repeated for many iterations. At each iteration, 8*5=40 policies are considered/tested, pruned to 8 best policies, which are mutated to get again 40 policies to test in the next iteration. (Polyjuice actually does not use a crossover approach to produce offspring between the best policies, as that was found to not work well.)
This training is best effort, and is not guaranteed to be optimal, because it can get stuck in a local optimal. But in practice, this was found to work well. Polyjuice can learn a 309K TPS policy in 100 iterations. The training runs on a single machine for now; each iteration takes 80 seconds, so 100 iterations take a little more than two hours.
Evaluation
For low-contention workload (like when you use too many warehouses in TPC-C), the I/O becomes the bottleneck, and improving the CC doesn't translate to the throughput increases. Therefore the focus of the evaluation is on contention-medium or contention-heavy workload conducted on a on a 56-core Intel machine with 2 NUMA nodes. Each NUMA node has 28 cores (Xeon Gold 6238R 2.20GHz) and 188GB memory.

With 1-warehouse (high contention), Polyjuice shows 45% improvement. With 8-warehouses (medium contention), Polyjuice shows 19% improvement. But under low contention (using larger number of warehouses) Silo and Cormcc beats polyjuice. For 48 warehouses, in which each worker corresponds to its local warehouse, Polyjuice is slightly slower (8%) than Silo, even though Polyjuice learns the same policy as Silo. This is because Polyjuice needs to maintain additional meta- data in each tuple, which affects the cache locality. So, you can argue that the observation in the beginning still holds: there is no one supreme algorithm for all workloads, although Polyjuice comes close to that goal.

Figure 6 shows that adding "early validation" into the action space improves performance most significantly for high and medium contention cases, as this leads to detecting conflicts earlier and reducing the retry cost.
The paper also shows evaluations for TPC-E to show how Polyjuice can still manage the increased action space resulting from a more complicated benchmark with more transactions. Finally, there is an evaluation based on the trace of a real-world e-commerce website (downloaded from Kaggle), to show how Polyjuice fares with changes in workloads in different days. For the trace analyzed, Polyjuice needed to retrain 15 times to cover a period of 196 days.
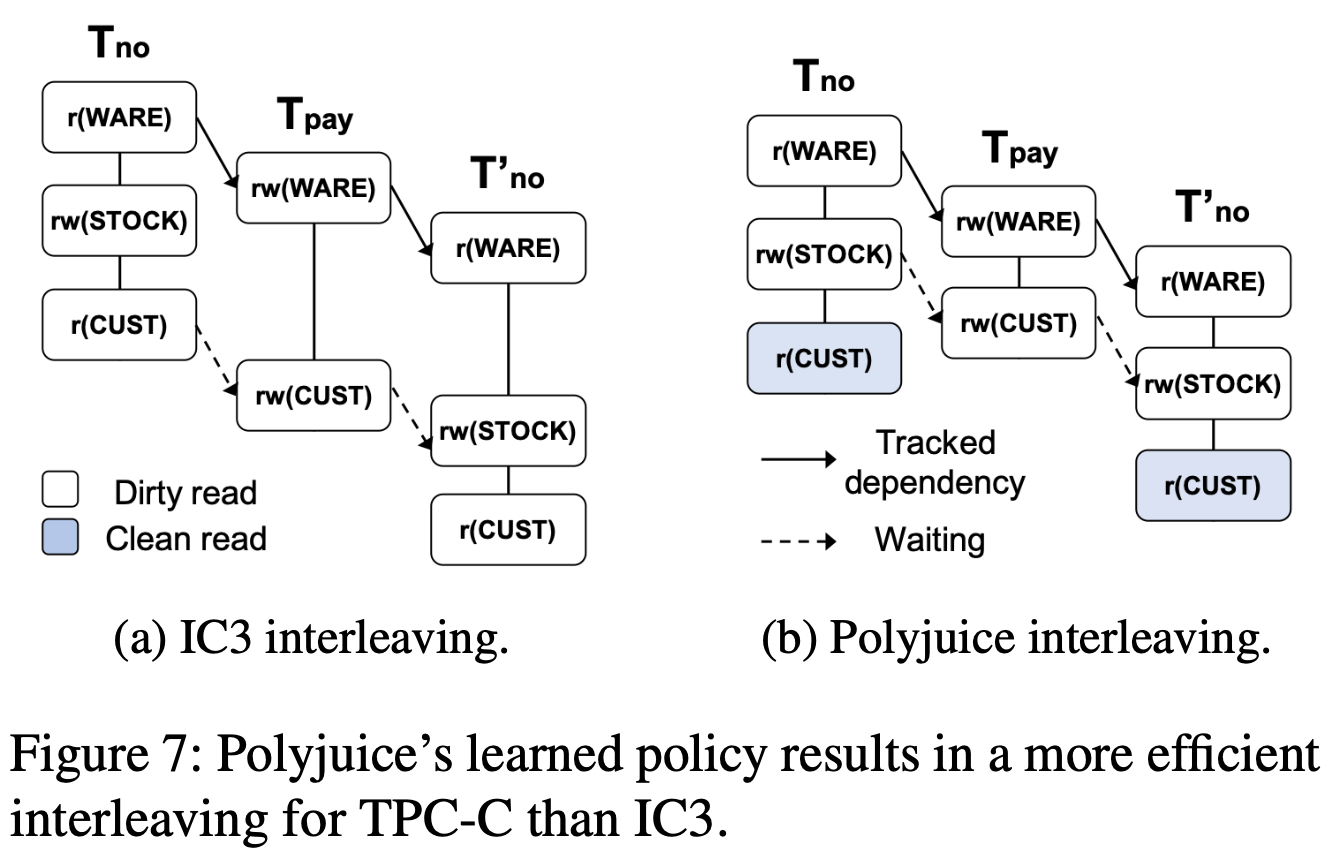
Conclusion
So what do we have after all being said and done? If you know your workload, then you don't need Polyjuice, use whatever CC algorithm works best for your workload. But workloads are seldom known and stable. They often change. If the workloads change too quickly/significantly or there is no pattern to any workload (it is almost random), then Polyjuice is of no help again. Otherwise, Polyjuice can improve throughput under high-contention and medium-contention by inferring and using the right fine-graned CC policy that the training identified.
To recap again, I really like this paper. Polyjuice shows the importance of runtime information for inferring the most suitable systems-policy action (in this case the CC action) and the richness of what we can infer this way. This is practical work, not just of research/theoretical interest. Tim Kraska's learned index work opened this line of investigation, and building systems that automatically adjust to workloads and data remains very important especially for large-scale cloud services.





Comments