Strict-serializability, but at what cost, for what purpose?
Strict-serializability guarantees that transactions appear to occur in an order consistent with the "real-time" ordering of those transactions: If transaction T1 commits before transaction T2 is invoked, then the commit timestamp of T1 precedes the commit timestamp of T2.
This is, in fact, the real-time constraint from linearizability, but applied across transactions not just per-key. A strict-serializability system satisfies both serializability (transactions appear to occur as if they are executed one at a time in isolation) and linearizability per key (after all single-key reads/writes are transactions over one item). Below figure is from https://jepsen.io/consistency.
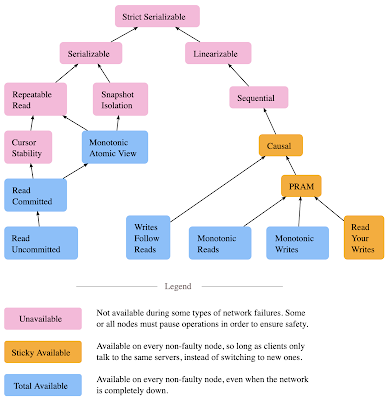
However, this is a one-way implication, the other direction does not hold. You can satisfy both serializability per transactions and linearizability per key, but fail to satisfy strict-serializability. (Below I give an example accompanied with a TLA+ specification to check it.) This is because, in strict-serializability, linearizability should apply across transactions, not just per key.
Linearizability alone can be cheap, because it is per key. It is often achieved by assigning a key to a single shard and serializing access to that shard via Paxos/Raft. In contrast, strict-serializability is expensive, because it needs to hold across any arbitrary key. Now you need to coordinate across all shards in the system to ensure that the assignment of timestamps does not violate the real-time ordering of those transactions. We will consider the cost of doing this under the "at what cost discussion" section.
This raises the question, "What application requires strict-consistency"? We should give customers strict-consistency, if they need it. But does the customer really need it, or do they want to cover all bases and be safe just in case? Reasoning about isolation and consistency is especially hard for distributed databases, so customers may just be opting out to go with the highest level offered. We will discuss this under the "for what purpose" section.
An execution that is serializable but not strict-serializable
Consider two keys, x and y. Initially, x=0 and y=0. Consider three transactions.
T1: r(y)r(x)
T2: w(x,1)
T3: w(y,1)
Suppose, this is their timestamped ordering:
T1 gets start-ts=1
T2 gets start-ts=1 and commit-ts=2
T3 gets start-ts=3 and commit-ts=4
T1 gets commit-ts=5
Assume T1 returns y=1 and x=0 when it commits. This is not acceptable under strict-serializable execution. If T1 saw the y=1 update from T3, it should have seen the x=1 update from T2, because T2 has a commit timestamp smaller than T3 and this real-time ordering should be respected.
On the other hand, it is possible to find a serializable execution for T1, T2, and T3, where T1 reads y=1 and x=0. Simple, pretend as if the order is:
1. T3 starts and commits
2. T1 starts and commits
3. T2 starts and commits
All serializability provides is the guarantee that transactions appear to occur as if they are executed one at a time in isolation. Serializability is not concerned with the real-time ordering timestamps of the transactions, so it is allowed to order T3 before T2, ignoring the timestamps assigned to their commits.
Who knows, maybe this is the real ordering, and timestamps had errors in them. y is assigned to a shard whose host has a clock that is ahead of "real-time" and so T3 is assigned (start-ts=3 and commit-ts=4) even though it happens first. T1 with clocks close to real-time executes on another host and gets (start-ts=1 and commit-ts=5) and reads T3's update. Finally T2 starts on another host, which has a clock that is behind "real time" and it gets assigned (start-ts=1 and commit-ts=2). This is plausible, because it is hard to tightly synchronize clocks across all hosts.
However, if the client had faith in the timestamps and expected results to follow the timestamp ordering, this behavior will look anomalous to the client. This anomaly is called the causal-reverse anomaly and this post has a detailed discussion of how that applies to CockroachDB in practice.
It is all about managing expectations
Maybe the right way to think about this is as follows. What is an anomaly? Anomaly means that your mental model does not match the isolation model provided by the database.
Even strict-serializability have anamolies. Yes! Some users think if they start T1 first, then start T2, the commit order should be T1 followed by T2, and are surprised when strict-serializability does not provide it. In this case, T1 and T2 are concurrent (T1's commit does not come before T2 starts), so strict-serializability does not apply here. This case does not even fall under the jurisdiction of "external consistency", which guarantees T1 comes before T2, if T1 commits before T2 starts to commit. Yet, the user is surprised, so this is an anomaly to them. The user will then have to solve the inadequacy of strict-serializability here by realizing that if T2 is semantically related to T1, they should not start T2 before T1 commits. They can insert a synchronization read in T2 to see T1 take effect.
Serializability has the reverse-causal anomaly as we discussed in detail in the T1, T2, T3 example above. There would be no anomaly to user here if the user did not put blind trust in the commit-timestamps. But if this is important to the user, the user will close the gap here, by include a read T1 within T2, if
T2 is semantically related to T1. Another way to have this is use a type system, like parent-child relationship with semantically related keys. In other words, the user makes this semantic relation explicit, and achieve the desired purpose while living in serializability isolation. (Instead of the abstract/conceptual definition of serializability, here I am thinking of the underlying sharded distributed database model including linearizability per key, which gives Strong Partition Serializability.)
Snapshot isolation has write-skew anomaly as we discussed in an earlier post. The solution, is yes, again the same. If T2 is semantically related to T1, include a read of updated key in T1 within T2, and make this semantic relation explicit.
The bottom line is, it is all about managing expectations. You need to choose an isolation level you can live with and learn about the "anomalies" it allows. Remember, even strict-serializability has anomalies if you had different expectations than what it provides. There is no shortcut around being educated about the isolation levels.
Strict-serializability, but at what cost?
At this point, we have a pretty good grounding about what strict-serializability provides and what it does not provide. Now, let's consider the cost of strict-serializability.
Strict serializability is often implemented by imposing a bounded clock skew between any pair of hosts. This assumption is needed to guarantee that if transaction T1 commits before transaction T2 is invoked, then the commit timestamp of T1 precedes the commit timestamp of T2.
Spanner takes this approach with True-Time timestamps which uses atomic clocks. Atomic clocks provide small clock skews, but inevitably networking over switches introduce nondeterminism in timing and increases the clock uncertainty bound. The Spanner paper gave this as 7 milliseconds, even with some networking layer protocol integrations. This has definitely improved in the 10 years since publication of Spanner, but it is expensive to do full stack integration to drive the clock uncertainty bound really low. The protocol cost of using synchronized clocks is that Spanner has to wait for the maximum clock uncertainty bound to pass before committing a transaction. This has to be really pessimistic, worse case clock uncertainty bound. And even then this is essentially a probabilistic guarantee. Due to some faults, it may be possible to violate the maximum clock uncertainty bound and leak a causal reverse.
Another way of implementing this is by having a logically-centralized ordering service. This could be implemented via event dependency graph tracking or via quorum-based timestamping service. In any case, in this approach, you get a timestamp from the ordering service when starting a transaction and check-in back with the ordering service when committing a transaction for the service to keep track of dependencies. So this inevitably introduces coordination (hence latency) across all hosts managing different shards, even when the keys may not be semantically related. I think the clock bounding approach is more preferable to this one. Network latency does not improve well with hardware improvements, but tighter clock synchronization is possible with hardware improvements as we have been witnessing.
Calvin is similar in gist to the second approach of logically centralized ordering, but it comes with deterministic execution twist. Calvin pre-orders transactions in logs in batches, and then deterministically executes this log in the same order in replicas. Deterministic execution helps eliminate the need for distributed commit protocols. The downsides are the loss of conversational transaction execution as in SQL and high latency due to this batch based processing. As the price of determinism, Calvin can only do non-conversational transactions. Transactions which must perform reads in order to determine their full read/write sets are not natively supported in Calvin since Calvin’s deterministic locking protocol requires advance knowledge of all transactions' read/write sets before transaction execution can begin.
Strict-serializability, but for what purpose?
What application requires strict-serializability? What is the business reason to insist on linearizability across all keys? What is the reason to require precise real-time ordering across any item updates, because any update may be semantically related?
If strict-serializability is needed, it is likely applicable to a subset of items. The entire system should not be paying the cost of waiting maximum clock uncertainty bounds just to provide that for a subset of items. The application developer would know those items, and can add synchronization explicitly via a read as we discussed in the "managing expectations" section. (Or, it would be nice if the system can give strict-serializability on demand for certain operation types or data types.)
Is there a graph-based application that may require strict-serializability potentially across all items? I won't argue against a convenience argument. Maybe the customer likes to pay the price of strict serializability at the OLTP service, so they don't need to be bothered with hassles in analytics. But what is that application in real-world? My intuition is that even graph analytics don't go around taking consistent snapshots using timestamps and evaluating predicates on consistent snapshots.
Maybe there is an argument for "build it and they will come" for providing strict-serializability. But, since strict-serializable distributed SQL systems have been around for some time, some applications must have arrived by now, right? Have you seen someone using strict-serializability over a distributed SQL system, whose purpose would not be served by using serializability? I am asking for real-world in production use cases, and not conceptual/hypothetical scenarios. If you know one, DM me on Twitter or email me. We talked about the technical cost of strict-serializability in terms of latency and throughput. There is also a monetary cost associated with it. If you can tell me about your use case, I can tell you whether you really need it or avoid it without any inconvenience and save money by going with lesser isolation level. Win-win, I say.
Appendix: TLA+ model
Here is the TLA+ model for the example I gave above. It uses the client-centric isolation checking module I discussed last time.
You can see that the execution I discussed above satisfies serializability but fails to satisfy strict-serializability.
At the end of the model, check what happens if I make T2 and T3 slightly overlap! With the timestamps2 assignment, strict-serializability of the execution becomes possible again, because it is possible for T3 to update before T2, and for T1 to get serialized for commit in that brief instance. Strict-consistency being this fickle and fragile with respect to ordering requirements, it is hard for applications to take hard-dependencies on real-time requirements.






Comments
[1] Y. Breitbart, H. Garcia-Molina, and A. Silberschatz. Overview of multidatabase transaction management. VLDB Journal, 1(2):181–293, 1992.
[2] Daudjee and Salem, ICDE 2004.