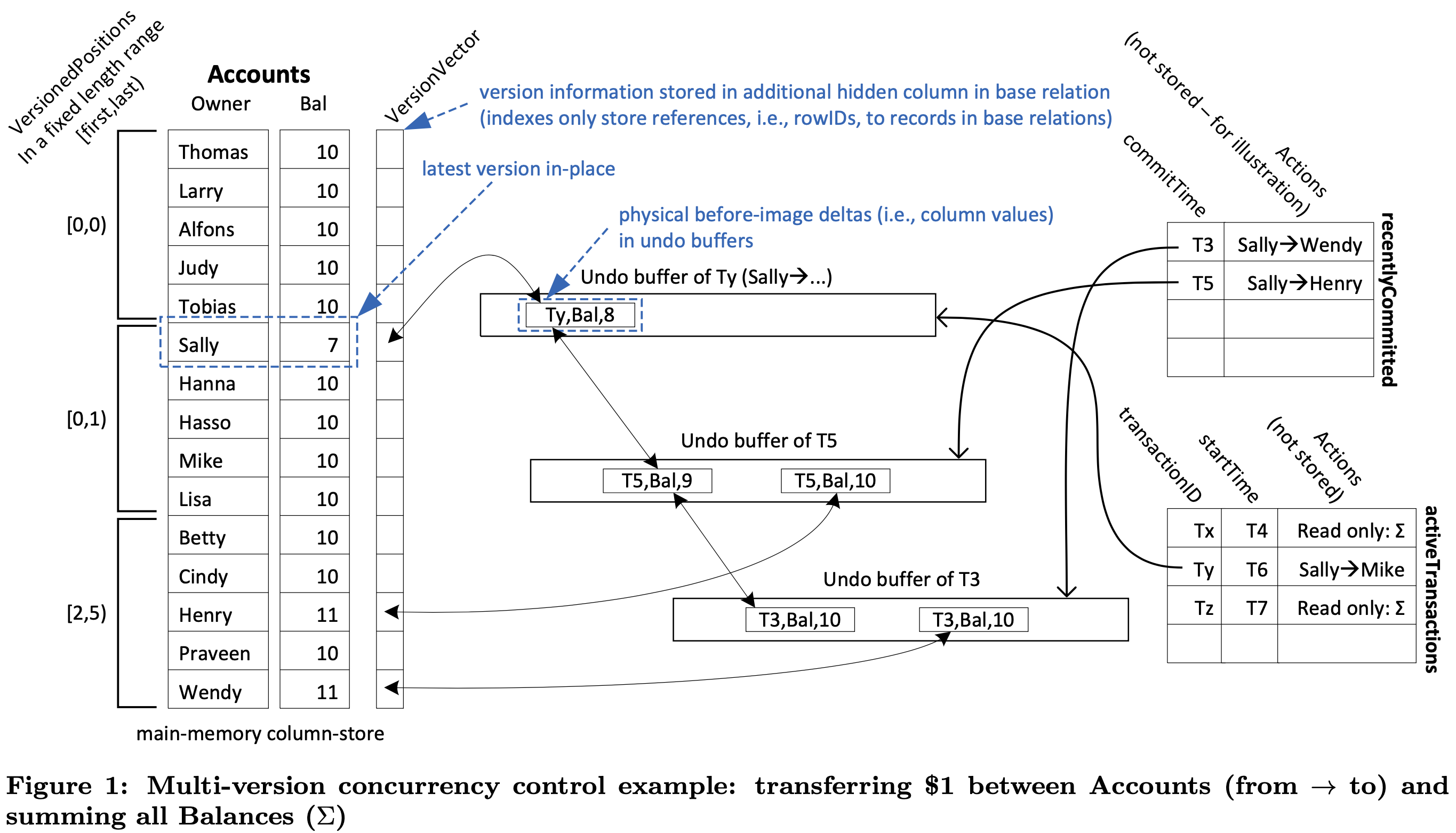
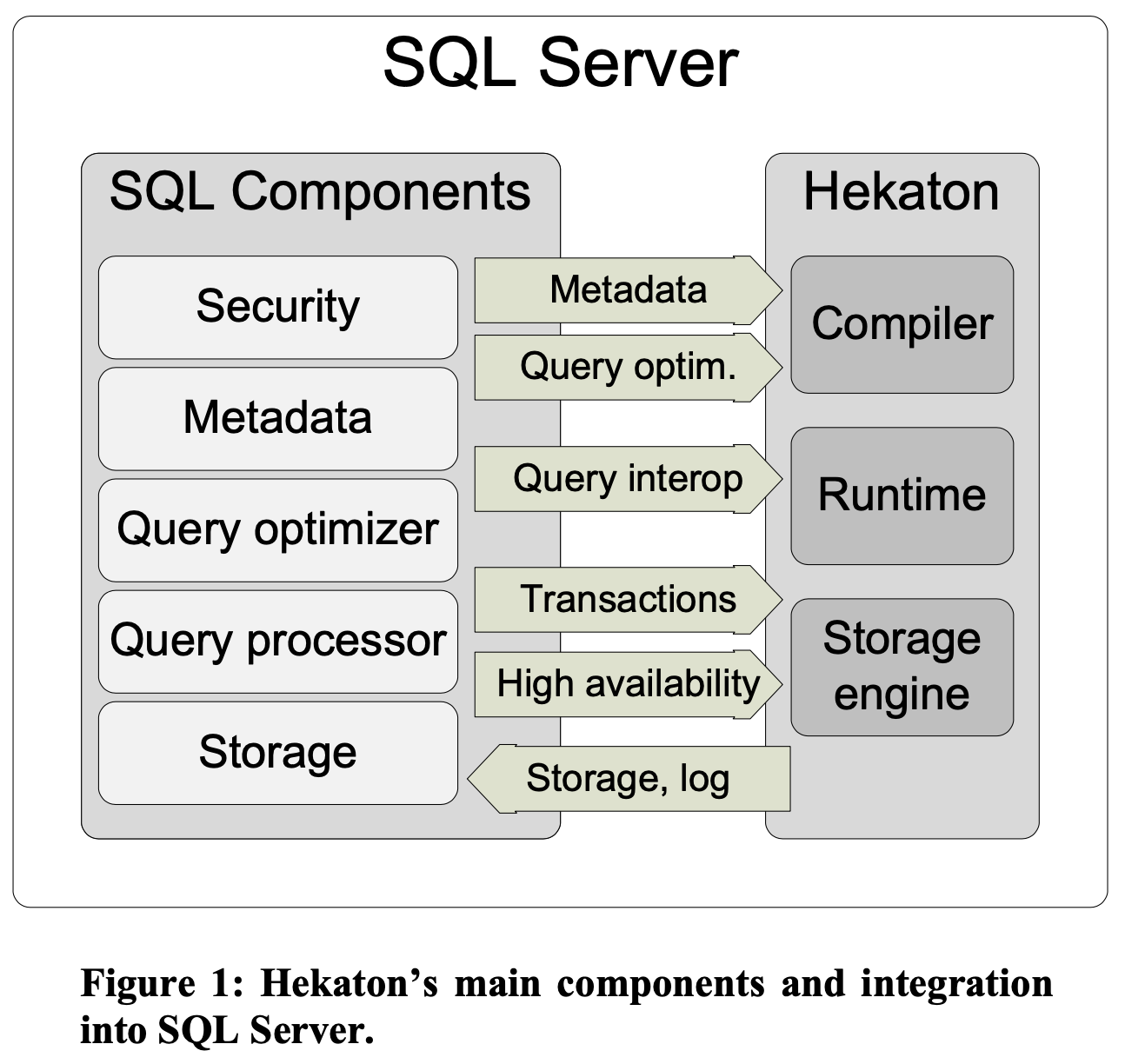
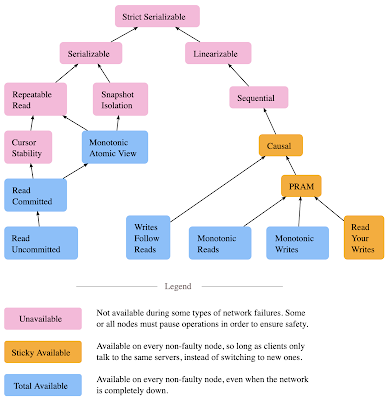
Socrates: The New SQL Server in the Cloud (Sigmod 2019)
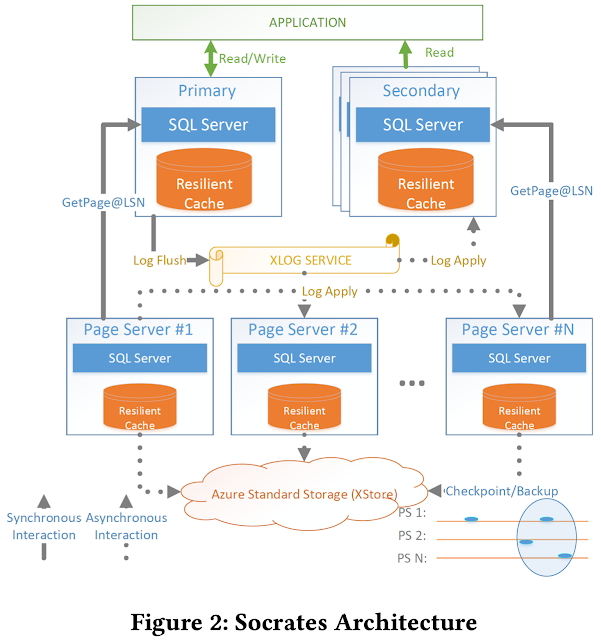
This paper (Sigmod 2019) presents Socrates, the database-as-a-service (DBaaS) architecture of the Azure SQL DB Hyperscale. Deploying a DBaaS in the cloud requires an architecture that is cost-effective yet performant. An idea that works well is to decompose/disaggregate the functionality of a database into two as compute services (e.g., transaction processing) and storage services (e.g., checkpointing and recovery). The first commercial system that adopted this idea is Amazon Aurora. The Socrates design adopts the separation of compute from storage as it has been proven useful. In addition, Socrates separates database log from storage and treats the log as a first-class citizen. Separating the log and storage tiers disentangles durability (implemented by the log) and availability (implemented by the storage tier). This separation yields significant benefits: in contrast to availability, durability does not require copies in fast storage, in contrast to durability, availability do...