Decoupled Transactions: Low Tail Latency Online Transactions Atop Jittery Servers (CIDR 2022)
This is a CIDR22 paper by Pat Helland. It is a long paper at 18 pages, followed by 12 pages of appendix. Since he wrote such a long paper, I won't apologize for writing a long review.
This is a Pat Helland paper, so it is full of Hellandisms. Pat's papers are always remarkable, distinct. There is a lot of wisdom in them. So, in case there could be any doubt about this, let me preface this review by saying that I learn a lot from Pat's papers, and I am grateful to Pat for teaching me and the community.
UPDATE: This is a very technical and dense paper, despite the colloquial writing
style. Appendix D, Sections 15.3 and 15.4 show how to address the jitter
free liveness check via log and the jitter free concurrent log fencing.
I had gotten these wrong about the paper, and criticized the paper with
my limited understanding of the design. It took many hours of
discussion with Pat to get a better understanding of the protocols in
the paper. I owe Pat a revised write-up but I have been procrastinating
on this. This paper deserves very
careful studying.
Problem and scope
Jitter refers to probabilistic response times, message latencies in networks. In big data processing systems it is easy to deal with jitter by retrying stragglers, in fact this has been suggested in the MapReduce paper.
But the same approach does not apply to databases, where we don't have the same idempotency affordances. Databases should be transactionally correct!
The paper presents a hypothetical design (meaning this is not implemented). The design explores techniques to dampen application visible jitter in a database system running in a cloud datacenter where most of the servers are responsive. The goal of the paper is not to define a super-scalable SQL system, but to scale to tens of servers with predictable response time while running in a largely unpredictable environment.
The design further restricts the question to transactions using snapshot isolation. Snapshot isolation transactions can do independent changes to the database as long as there are no conflicting updates and each transaction sees only snapshot reads. The question then becomes, can these two things be accomplished without stalling behind jittery servers?
In distributed systems, even (especially?) when you forget the question, quorums are the answer. This design also leverages quorums right and left to solve the jitter problem. If all but the recent data is kept in shared storage in the cloud and we can read it without jittering (thanks to quorums), and that already solves the jitter-free snapshot reads (with respect to a past/old time) aspect of snapshot isolation. Let's jump into the architecture to see where else it uses quorums. Answer, almost everywhere.
Then we will discuss the other pieces of the puzzle, seniority timestamps (hybrid logical clocks really) generated via synchronized clocks, and confluence to deal with partially-ordered updates.
Architecture
In this architecture, five different types of servers do different jobs. (That's too much for my taste, and I will discuss about this after introducing these.) Work happens by generating new record-versions and reading the correct record-versions for snapshot reads.
Worker servers are database servers. Incoming DB-connections feed in SQL requests. Execution, reads, and updates happen in worker servers. Workers log to their own log in shared storage.
Coordinator servers help avoid conflicting updates as transactions commit and help locate recent changes for snapshot reads.
Data storage servers hold replicas of data files with DB data.
Log storage servers hold replicas of the log extents used for appending to the logs.
As data ages, it migrates to a key-value store in shared storage implemented as an LSM (Log Structured Merge System). The catalog maps key-ranges to stored data and its location in shared-storage. Catalog servers track metadata for workers, log-storage and data-storage. They manage worker's log extents and replicas.
In this decoupled transactions database architecture, each record update creates a new record-version that layers atop earlier record-versions and is visible to transactions with later snapshot times. Record-versions older than a few minutes or so are in shared storage and are visible to all database servers in the database. Recent record-versions are found within the worker performing the transaction that created them. Snapshot read semantics are provided by reading the latest record-version that committed prior to the reader’s snapshot time.
Whereabouts of recent updates are obtained from coordinators at the beginning of each transaction. Each whereabouts entry describes a possible recent update made by a worker-server. Coordinators provide guidance to locate recent record-versions within worker server(s).
Tables are implemented by creating record-versions with unique primary keys for each row by concatenating Table-ID for the table, and the SQL defined unique primary-key comprising an ordered set of the table's columns. Finding record-versions for a snapshot is described but I was unable to get a clear picture of how this works as Sections 2.3 to 2.7 were not easy to follow.
This is of course first cut architecture figure. The paper identifies many risks for jitter in this architecture.
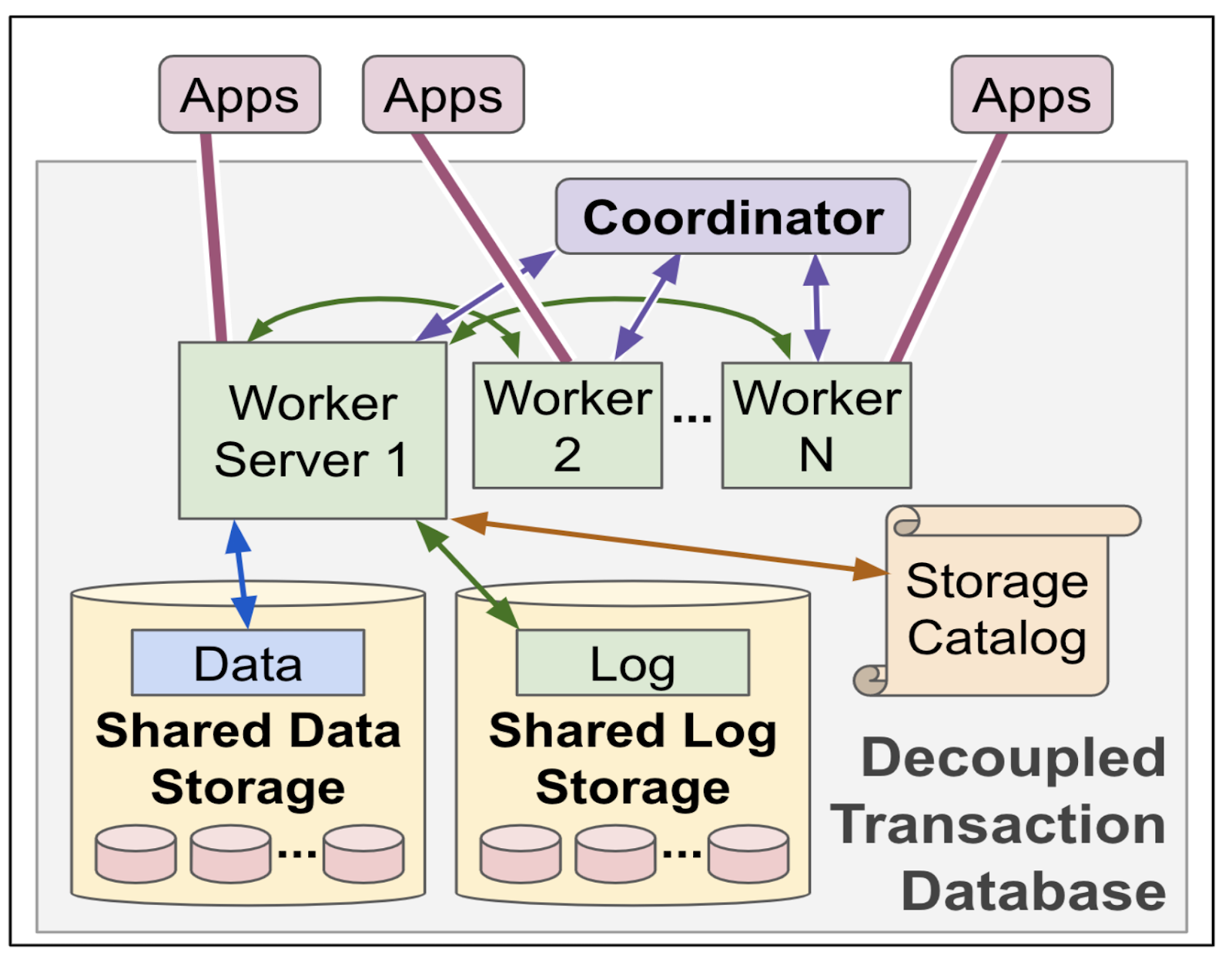
- Risk #1: Worker to coordinator
- Risk #2: Workers appending to their log
- Risk #3: Workers reading data-files
- Risk #4: Worker to catalog
- Risk #5: Asking other workers for recent record-versions
- Risk #6: Reading a slow worker's log to side-step it. If a worker can't respond about its recent updates, we look in its log. This, too, has risks of jitter we must avoid.
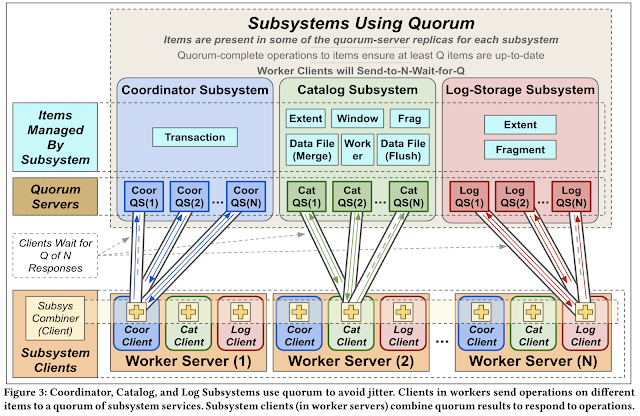
The solution? Quorum the shit out of each component. Here is the updated diagram. Note that coordinator, catalog, and log storage subsystems are all quorumed.

Discussion about the architecture
Here is what I think about the architecture.
Workers are a good idea for horizontally scaling the compute. Coordinator (coordinator quorum) is a good idea to manage the transaction disputes.
The thing I don't like is having separate data storage servers, log storage servers, and catalog servers? The dual nature of recent data versus old data complicates the design unnecessarily. Most recent data is in workers and workers learn this from coordinators and talk to other workers to get them when needed? This workers-to-workers communication is a source of bottleneck, and also a big jitter risk due to a worker being unavailable. (The paper tries to address this, but I don't buy the arguments, and will discuss why at the end.)
Why not just use learner servers implemented as a distributed key-value store which we can partition (via distributed hash tables) for horizontal scaling. That will simplify the architecture significantly. Just put a durable distributed journal before hitting these learners. (Delos work is just one example. Note that it is also implemented via quorums at loglet level.)
Another advantage of the journal approach is that it is more scalable for reading. Quorum reads do not scale. Reading from majority (if you define quorum as majority as in most work) of nodes keeps the load on each node (fine majority, but at limit we cannot overrun the capacity of single node which majority quorums intersect). You can beat this limit by dividing the shard smaller, but that also gets cumbersome and has costs. Instead journal approach helps here, you can read from one node and scale the reads better. Many systems use this approach.
Seniority: a disorderly order
Ok, moving on to the other pieces of the puzzle: Seniority.
The paper says: "Happened before is always jittery! Messages between servers flow through single servers. Each server may possibly jitter." I don't get this, actually. It would be nice to explain the perceived problem in more detail. Using happened before (e.g., via vector clocks) you can have causal-consistency in an available manner.
The paper says: "Seniority of transactions can be jitter-free!" While Section 3 keeps the reader in the dark about what this "seniority" might be, finally in Section 4 it is defined as follows: "Seniority in our system comes from transactions and their commit time. Commit time is a logical time that advances without jitter and without any special hardware in servers or the network. Worker servers and coordinator servers have their own clocks that may be out of sync. Logical time is calculated at each server based on the time from their own clocks along with an adjustment to align the server’s local clock to the system-wide logical time. Logical time is monotonic."
This sounds similar to hybrid logical clocks. While the paper calls this loosely synchronized clocks, at some point it is revealed that the precision is not that loose, and may not be available in many deployments. "Decoupled transactions needs less precision, perhaps 10s to 100s of microseconds."
The transaction commit time is the same as the permission-to-commit logical time. It is written in the transaction’s commit record. This becomes the transaction’s seniority. Seniority uses quorum to know a fuzzy beginning and a fuzzy retirement of items in the system. Transactions are partially ordered by seniority. Requests arriving too late are rejected. To commit: workers guess a transaction's seniority and coordinators confirm that seniority.
Clock skew does not cause incorrect behavior. Partial order is guaranteed by messages that happened before each other. When coordinators' logical times have large skew, some coordinators may receive requests for operations too late. The operation still may become complete-quorum if Q of N coordinator process it on time. Either the N coordinators' jitter resistance tolerates this or the worker is forced to select a time farther in the future, impacting the latency of operations. For this reason, the decoupled transactions database behaves best when the coordinators have a small skew between their logical times.
Confluence: adding clarity to fuzzy quorums
"Quorum is awesome : It's fast even when servers jitter.
Quorum is also awful : It's messy, fuzzy, and jumbled."
Here the paper double-clicks on the second part. Quorums can show some surprising results. Subsytem quorum-servers may see weird things: Quorum-servers each see only some of the successful operations. Subsystem clients (inside workers) may see weird things: Servers may give very different answers to an operation (because they've seen different things). There is a need to cope with intermittently included operations, and confluence comes to the rescue.
Confluence (using seniority) is the lynchpin of this design. Quorum avoids jitter but creates a jumbled execution. Confluence (via seniority) resolves the confusion of the jumbled execution. Three tricks are used to build confluent operations:
- Disjoint: If two operations have nothing to do with each other, they are reorderable.
- Sent by a single client
- Some intrinsic partial order
Quorum confluent solutions understand does not exist. Items can be retired using their seniority. As far as I can understand this is just the low-watermark idea. As quorum-clients and quorum-servers track retirement age, retired items can be reclaimed.
Discussion about seniority and confluence
Distributed systems community have been doing this for a while now. This type of doing transactions has been very popular after the TAPIR paper, "Building Consistent Transactions with Inconsistent Replication (SOSP'15)". There have been several followup work (Google Scholar shows 180+ citations) to the TAPIR idea where the data is first replicated to a quorum of replicas for durable multiversion storage (timestamped with loosely synchronized clocks), and order is derived from the quorums nodes post facto. Using low watermark for retiring things have been also explored in depth in these work.
The paper does not cite the TAPIR work. Pat has not followed up with distributed systems literature on this, but it is great that he is coming to the same conclusions coming from databases side.
Flipping FLP and Paxos comparison discussion
The paper discusses about how this architecture can sidestep Fischer-Lynch-Patterson(FLP) impossibility result and avoid drawbacks of Paxos. I will, of course, take issue with these.
Pat finishes his presentation with this line. "I don't agree with consensus: total order is brittle -> partial order provides more robust solutions."
Consensus/Paxos doesn't mean total order. It just means durable consistent decision on something. Partial order is OK in many Paxos variants, going as far back as to the Generalized Paxos paper in 2004.
It is also possible to have client-side (opportunistic leader single decree) Paxos consensus+commit protocol for implementing those workers. Paxos doesn't prescribe going with the same stable leader. Not at all.
Now let's move on to the flipping FLP discussion.
The paper says: "While FLP, the Fischer-Lynch-Patterson Impossibility Result remains undeniably true, we can build systems that sidestep the problem. FLP assumes that all visibility into the server is via direct messaging. For cases, like database worker-servers, where the server must log its progress to a replicated log before responding, we can see the health of the server by looking at its log. The log uses quorum and we can check its progress without jitter. We can deterministically know if a server is sick or dead in an asynchronous network."
This is simply assuming the issue affects only F out of N nodes. FLP asynchrony window does not work like that. It is also hard to make a practical case for that since "Network is [not] reliable" as Bailis and Kingsbury argue in detail. FLP asynchrony window talks about that worse case windows when normal message latencies on network channels don't apply.
The paper says: "Paxos ensures a single new value is agreed across a quorum of servers. This is a linear order of new values. Paxos is safe because any new agreed value will be seen by all participants. It is not live since agreeing on a new value cannot be guaranteed in bounded time. Paxos leverages quorum and confluence but does so in a jittery fashion. Confluence comes from the order of proposals within the Paxos algorithm. Paxos uses both quorum and confluence but makes a different tradeoff than we do here. We choose to have fuzzy state transitions as items come into existence and retire. Paxos chooses to have crisp and clear transitions to new values at the expense of introducing liveness challenges."
Paxos is live outside a full asynchrony window that may occasionally occur in any distributed system. I am assuming the paper says Paxos is not live, because of the leader dueling under that transitory asynhrony window in FLP. Even in that fully asynchronous period, it is possible that probabilistic single leader may sneak in and finish. It is just not guaranteed. In that fully asynchronous window, nothing can be guaranteed anyways. The decoupled transactions architecture explained here is bound by the same laws of distributed systems in this asynchronous window.
FLP does not apply to atomic storage, but is this just atomic storage? There is some learning that needs to happen to solve the transaction commit problem, and that requires consensus. So this cannot escape what FLP incurs on Paxos. You will be bitten. The question is where will you get bitten?
I think in this architecture it is the worker. The worker is doing the learning and closing the deal. This is still consensus and governed by FLP, asynchronous impossibility. Worker may die, they may not figure it out for sometime, and they start it again at another worker, and transaction happens. The paper acknowledges this and says: If the worker jitters, kill the worker, fence & repair log, read record. How do you detect if it jitters in an asynch system? What is the cut-off point to detect this? Let me repeat that, in asynchronous system how do you identify the slow worker, what is the cut-off point to detect this? This is where the FLP rears its head again. Maybe some of this progress argument is also swept to clock synchronization, that is just relegating the problem to another level of indirection. FLP is still there in that asynchronous window. In that window, you are under FLP jurisdiction. Absolutely the same deal with Paxos! Gray failure for the leader in Paxos is just transposed to the gray failure in worker problem. (As I mentioned above many Paxos variants don't use a stable leader, but use clients/workers in a leaderless/opportunistic manner in leader role. This makes the transposition much clearer.)





Comments
Great blog post. I wanted to ask if you understood how the paper deals with aborts; I understand from quorum confluence that once a worker sees a quorum of coordinators accept a transaction, the transaction is committed. But what if it sees a single coordinator abort?
Then it's no longer sure if there is a quorum or not, so the transaction might've been either committed or aborted. In a non-distributed system, this might happen due to failure, but then you can just wait for recovery to see the final abort/commit result.
Here, assuming f failures, we might never know. Does the paper assume that all coordinators will eventually respond? (If so, I'm confused about its reference to Paxos and FLP).
Thanks,
David