Paper summary. Cloud programming simplified: A Berkeley view on Serverless Computing
This position paper by UC Berkeley RISE lab is about serverless computing, its shortcomings, and its potential. It is easy reading, and is still useful even if you have a pretty good understanding about serverless computing due to some insights and forecasts in the paper. As you will read below, the paper provides a very strong endorsement for serverless computing.
Instead of explaining the paper in my terms, I quote some of my highlights from the paper below, and at the end, in the MAD questions section, I discuss some of my thoughts on serverless computing.
To set up your own environment in cloud (using virtual machines), you need to address these 8 issues.
Compared to what it takes to set up the servers with the proper environment to run the code, the code to accomplish application logic might be dozens of lines of JavaScript.
In our definition, for a service to be considered serverless, it must scale automatically with no need for explicit provisioning, and be billed based on usage. Cloud functions are the general purpose element in serverless computing today, and lead the way to a simplified and general purpose programming model for the cloud.
While we are unsure which solutions will win, we believe all issues will all be addressed eventually, thereby enabling serverless computing to become the face of cloud computing.
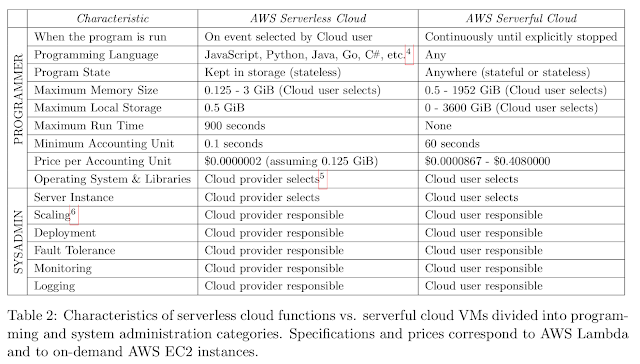
Serverless programming provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages. Automated memory management relieves programmers from managing memory resources, whereas serverless computing relieves programmers from managing server resources.
There are three critical distinctions between serverless and serverfull computing:
We believe serverless computing represents significant innovation over platform as a service (PaaS) and other previous models. Among these factors, the autoscaling offered by AWS Lambda marked a striking departure from what came before. It tracked load with much greater fidelity than serverful autoscaling techniques, responding quickly to scale up when needed and scaling all the way down to zero resources, and zero cost, in the absence of demand. It charged in a much more fine-grained way, providing a minimum billing increment of 100 ms at a time when other autoscaling services charged by the hour.

Cloud functions, or functions as a service (FaaS), provide general compute and are complemented by an ecosystem of specialized Backend as a Service (BaaS) offerings such as object storage, databases, or messaging.

Unlike serverless computing, Kubernetes is a technology that simplifies management of serverful computing. Kubernetes can provide short-lived computing environments, like serverless computing, and has far fewer limitations, e.g., on hardware resources, execution time, and network communication. It can also deploy software originally developed for on-premise use completely on the public cloud with little modification. Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplexing.
Recent surveys found that about 24% of serverless users were new to cloud computing and 30% of existing serverful cloud customers also used serverless computing.
\\ Murat's note: While 24% is an impressive number, what is the control here? Maybe traditional cloud computing is also getting new users at that rate?

\\ Murat's note: Chat bots are very popular use case of serverless, even more than IoT in total. They are sneaking under the radar, but are worth watching for their future ubiquitous applications.

Serverless SQLite: Databases. A strawman solution would be to run common transactional databases, such as PostgreSQL, Oracle, or MySQL inside cloud functions. However, that immediately runs into a number of challenges. First, serverless computing has no built-in persistent storage, so we need to leverage some remote persistent store, which introduces large latency. Second, these databases assume connection-oriented protocols, e.g., databases are running as servers accepting connections from clients. This assumption conflicts with existing cloud functions that are running behind network address translators, and thus don't support incoming connections. Finally, while many high performance databases rely on shared memory, cloud functions run in isolation so cannot share memory. While shared-nothing distributed databases do not require shared memory, they expect nodes to remain online and be directly addressable.
Lack of fine-grained coordination. Applications are left with no choice but to either (1) manage a VM-based system that provides notifications, as in ElastiCache and SAND, or (2) implement their own notification mechanism, such as in ExCamera, that enables cloud functions to communicate with each other via a long-running VM-based rendezvous server. This limitation also suggests that new variants of serverless computing may be worth exploring, for example naming function instances and allowing direct addressability for access to their internal state (e.g., Actors as a Service).
Networking challenges. There may be several ways to address this challenge:
We predict that serverless use will skyrocket.
The first step is Serverless Ephemeral Storage, which must provide low latency and high IOPS at reasonable cost, but need not provide economical long term storage. A second class of applications would benefit from Serverless Durable Storage, which does demand long term storage. New non-volatile memory technologies may help with such storage systems. Other applications would benefit from a low latency signaling service and support for popular communication primitives.
Two challenges for the future of serverless computing are improved security and accommodating cost-performance advances that are likely to come from special purpose processors.
The future of serverful computing will be to facilitate BaaS. Applications that prove to be difficult to write on top of serverless computing, such as OLTP databases or communication primitives such as queues, will likely be offered as part of a richer set of services from all cloud providers.
The paper gives very strong endorsements for serverless:
First of all, we need to quantify and limit the claim. What does skyrocket mean? What does it mean for serverless to become the face of cloud computing? And finally what does serverless mean? Is this claim true of today's cloud functions? If we don't have a stable definition of serverless, this claim is prone to the No True Scotsman fallacy. If serverless use does not skyrocket, it will be because we don't have "true" serverless yet.
Ok, assuming that the claim is quantified, what may be some reasons it could fail?
Serverless improves greatly on ease of use, and that alone may warrant a lot of use for serverless. But ease-of-use is not necessarily exclusive to serverless. BaaS managed services, like distributed databases, can get even easier to use. And some even support stored procedures, which helps meet some of the serverless needs.
When comparing with PaaS, the paper said that serverless differentiates itself due to its very quick autoscaling. But, this may not be such a strong differentiator for the customers. Most customers may not have very bursty workloads that require quick and extreme scaling.
Another contender for the serverless lunch may be software as a service (SaaS), like instagram, icloud, etc. SaaS can be even simpler to use than serverless, and may be programmed with visual workflows using mouse clicks. SaaS may steal users from serverless would work if SaaS services play well with each other so customers can pipe output from one as input to others.
2. Could serverless ever work for stateful services?
It is easy to make FaaS serverless because it is stateless. But FaaS scalability is limited by the BaaS scalability it depends on. It is easy to scale storage, because it is also stateless. But, the story becomes murkier when it comes to scalability of stateful services. At the limits, this is likely to be impossible: You can't have extreme scalability and extreme state (requiring incessant coordination). But outside the extremes, with good engineering we can get quick scalability for stateful services.
3. "Berkeley view" papers
If you are into this stuff, here are two other Berkeley view papers.
A Berkeley view of systems challenges for AI
Above the Clouds: A Berkeley View of Cloud Computing
Also there was a recent CIDR paper by another group of UC Berkeley researchers on serverless computing titled: "Serverless Computing: One Step Forward, Two Steps Back", which I had covered before. This paper is worth reading for another perspective on serverless.
Instead of explaining the paper in my terms, I quote some of my highlights from the paper below, and at the end, in the MAD questions section, I discuss some of my thoughts on serverless computing.
Introduction
We believe the main reason for the success of low-level virtual machines was that in the early days of cloud computing users wanted to recreate the same computing environment in the cloud that they had on their local computers to simplify porting their workloads to the cloud.To set up your own environment in cloud (using virtual machines), you need to address these 8 issues.
- Redundancy for availability, so that a single machine failure doesn't take down the service.
- Geographic distribution of redundant copies to preserve the service in case of disaster.
- Load balancing and request routing to efficiently utilize resources.
- Autoscaling in response to changes in load to scale up or down the system.
- Monitoring to make sure the service is still running well.
- Logging to record messages needed for debugging or performance tuning.
- System upgrades, including security patching.
- Migration to new instances as they become available.
Compared to what it takes to set up the servers with the proper environment to run the code, the code to accomplish application logic might be dozens of lines of JavaScript.
In our definition, for a service to be considered serverless, it must scale automatically with no need for explicit provisioning, and be billed based on usage. Cloud functions are the general purpose element in serverless computing today, and lead the way to a simplified and general purpose programming model for the cloud.
While we are unsure which solutions will win, we believe all issues will all be addressed eventually, thereby enabling serverless computing to become the face of cloud computing.
Emergence of Serverless Computing

Serverless programming provides an interface that greatly simplifies cloud programming, and represents an evolution that parallels the transition from assembly language to high-level programming languages. Automated memory management relieves programmers from managing memory resources, whereas serverless computing relieves programmers from managing server resources.
There are three critical distinctions between serverless and serverfull computing:
- Decoupled computation and storage. The storage and computation scale separately and are provisioned and priced independently. In general, the storage is provided by a separate cloud service and the computation is stateless.
- Executing code without managing resource allocation. Instead of requesting resources, the user provides a piece of code and the cloud automatically provisions resources to execute that code.
- Paying in proportion to resources used instead of for resources allocated. Billing is by some dimension associated with the execution, such as execution time, rather than by a dimension of the base cloud platform, such as size and number of VMs allocated.
We believe serverless computing represents significant innovation over platform as a service (PaaS) and other previous models. Among these factors, the autoscaling offered by AWS Lambda marked a striking departure from what came before. It tracked load with much greater fidelity than serverful autoscaling techniques, responding quickly to scale up when needed and scaling all the way down to zero resources, and zero cost, in the absence of demand. It charged in a much more fine-grained way, providing a minimum billing increment of 100 ms at a time when other autoscaling services charged by the hour.

Cloud functions, or functions as a service (FaaS), provide general compute and are complemented by an ecosystem of specialized Backend as a Service (BaaS) offerings such as object storage, databases, or messaging.

Unlike serverless computing, Kubernetes is a technology that simplifies management of serverful computing. Kubernetes can provide short-lived computing environments, like serverless computing, and has far fewer limitations, e.g., on hardware resources, execution time, and network communication. It can also deploy software originally developed for on-premise use completely on the public cloud with little modification. Serverless computing, on the other hand, introduces a paradigm shift that allows fully offloading operational responsibilities to the provider, and makes possible fine-grained multi-tenant multiplexing.
Recent surveys found that about 24% of serverless users were new to cloud computing and 30% of existing serverful cloud customers also used serverless computing.
\\ Murat's note: While 24% is an impressive number, what is the control here? Maybe traditional cloud computing is also getting new users at that rate?

\\ Murat's note: Chat bots are very popular use case of serverless, even more than IoT in total. They are sneaking under the radar, but are worth watching for their future ubiquitous applications.
Limitations of today's serverless platforms
In this section, we present an overview of five research projects and discuss the obstacles that prevent existing serverless computing platforms from achieving state-of-the-art performance, i.e., matching the performance of serverful clouds for the same workloads.
Serverless SQLite: Databases. A strawman solution would be to run common transactional databases, such as PostgreSQL, Oracle, or MySQL inside cloud functions. However, that immediately runs into a number of challenges. First, serverless computing has no built-in persistent storage, so we need to leverage some remote persistent store, which introduces large latency. Second, these databases assume connection-oriented protocols, e.g., databases are running as servers accepting connections from clients. This assumption conflicts with existing cloud functions that are running behind network address translators, and thus don't support incoming connections. Finally, while many high performance databases rely on shared memory, cloud functions run in isolation so cannot share memory. While shared-nothing distributed databases do not require shared memory, they expect nodes to remain online and be directly addressable.
Lack of fine-grained coordination. Applications are left with no choice but to either (1) manage a VM-based system that provides notifications, as in ElastiCache and SAND, or (2) implement their own notification mechanism, such as in ExCamera, that enables cloud functions to communicate with each other via a long-running VM-based rendezvous server. This limitation also suggests that new variants of serverless computing may be worth exploring, for example naming function instances and allowing direct addressability for access to their internal state (e.g., Actors as a Service).
Networking challenges. There may be several ways to address this challenge:
- Provide cloud functions with a larger number of cores, similar to VM instances, so multiple tasks can combine and share data among them before sending over the network or after receiving it.
- Allow the developer to explicitly place the cloud functions on the same VM instance. Offer distributed communication primitives that applications can use out-of-the-box so that cloud providers can allocate cloud functions to the same VM instance.
- Let applications provide a computation graph, enabling the cloud provider to co-locate the cloud functions to minimize communication overhead.
Summary and predictions
By providing a simplified programming environment, serverless computing makes the cloud much easier to use, thereby attracting more people who can and will use it. [This is] a maturation akin to the move from assembly language to high-level languages more than four decades ago.We predict that serverless use will skyrocket.
The first step is Serverless Ephemeral Storage, which must provide low latency and high IOPS at reasonable cost, but need not provide economical long term storage. A second class of applications would benefit from Serverless Durable Storage, which does demand long term storage. New non-volatile memory technologies may help with such storage systems. Other applications would benefit from a low latency signaling service and support for popular communication primitives.
Two challenges for the future of serverless computing are improved security and accommodating cost-performance advances that are likely to come from special purpose processors.
The future of serverful computing will be to facilitate BaaS. Applications that prove to be difficult to write on top of serverless computing, such as OLTP databases or communication primitives such as queues, will likely be offered as part of a richer set of services from all cloud providers.
MAD questions
1. Is a very strong endorsement for serverless warranted?The paper gives very strong endorsements for serverless:
We predict that serverless use will skyrocket.Remember, when we read papers, we should fight vigorously with the claims, and play the devil's advocate. So let's challenge this claim. What could be the reasons this claim may not hold?
While we are unsure which solutions will win, we believe all issues will all be addressed eventually, thereby enabling serverless computing to become the face of cloud computing.
First of all, we need to quantify and limit the claim. What does skyrocket mean? What does it mean for serverless to become the face of cloud computing? And finally what does serverless mean? Is this claim true of today's cloud functions? If we don't have a stable definition of serverless, this claim is prone to the No True Scotsman fallacy. If serverless use does not skyrocket, it will be because we don't have "true" serverless yet.
Ok, assuming that the claim is quantified, what may be some reasons it could fail?
Serverless improves greatly on ease of use, and that alone may warrant a lot of use for serverless. But ease-of-use is not necessarily exclusive to serverless. BaaS managed services, like distributed databases, can get even easier to use. And some even support stored procedures, which helps meet some of the serverless needs.
When comparing with PaaS, the paper said that serverless differentiates itself due to its very quick autoscaling. But, this may not be such a strong differentiator for the customers. Most customers may not have very bursty workloads that require quick and extreme scaling.
Another contender for the serverless lunch may be software as a service (SaaS), like instagram, icloud, etc. SaaS can be even simpler to use than serverless, and may be programmed with visual workflows using mouse clicks. SaaS may steal users from serverless would work if SaaS services play well with each other so customers can pipe output from one as input to others.
2. Could serverless ever work for stateful services?
It is easy to make FaaS serverless because it is stateless. But FaaS scalability is limited by the BaaS scalability it depends on. It is easy to scale storage, because it is also stateless. But, the story becomes murkier when it comes to scalability of stateful services. At the limits, this is likely to be impossible: You can't have extreme scalability and extreme state (requiring incessant coordination). But outside the extremes, with good engineering we can get quick scalability for stateful services.
3. "Berkeley view" papers
If you are into this stuff, here are two other Berkeley view papers.
A Berkeley view of systems challenges for AI
Above the Clouds: A Berkeley View of Cloud Computing
Also there was a recent CIDR paper by another group of UC Berkeley researchers on serverless computing titled: "Serverless Computing: One Step Forward, Two Steps Back", which I had covered before. This paper is worth reading for another perspective on serverless.





Comments