Paper summary. A Berkeley view of systems challenges for AI
This position paper from Berkeley identifies an agenda for systems research in AI for the next 10 years. The paper also serves to publicize/showcase their research, and steer interest towards these directions, which is why you really write position papers.
The paper motivates the systems agenda by discussing how systems research/development played a crucial role in fueling AI’s recent success. It says that the remarkable progress in AI has been made possible by a "perfect storm" emerging over the past two decades, bringing together: (1) massive amounts of data, (2) scalable computer and software systems, and (3) the broad accessibility of these technologies.
The rest of the paper talks about the trends in AI and how those map to their systems research agenda for AI.
Research: (1) Build systems for RL that fully exploit parallelism, while allowing dynamic task graphs, providing millisecond-level latencies, and running on heterogeneous hardware under stringent deadlines. (2) Build systems that can faithfully simulate the real-world environment, as the environment changes continually and unexpectedly, and run faster than real time.
https://muratbuffalo.blogspot.com/2017/12/paper-summary-real-time-machine.html
Of course, the second part here refers to research described in "Real-Time Machine Learning: The Missing Pieces". Simulated Reality (SR) focuses on continually simulating the physical world with which the agent is interacting. Trying to simulate multiple possible futures of a physical environment in high fidelity within a couple milliseconds is a very ambitious goal. But research here can also help other fields, so this is interesting.
Research: (1) Build fine grained provenance support into AI systems to connect outcome changes (e.g., reward or state) to the data sources that caused these changes, and automatically learn causal, source-specific noise models. (2) Design API and language support for developing systems that maintain confidence intervals for decision-making, and in particular can flag unforeseen inputs.
Research: Build AI systems that can support interactive diagnostic analysis, that faithfully replay past executions, and that can help to determine the features of the input that are responsible for a particular decision, possibly by replaying the decision task against past perturbed inputs. More generally, provide systems support for causal inference.
Research: Build AI systems that leverage secure enclaves to ensure data confidentiality, user privacy and decision integrity, possibly by splitting the AI system’s code between a minimal code base running within the enclave, and code running outside the enclave. Ensure the code inside the enclave does not leak information, or compromise decision integrity.
Research: Build AI systems that are robust against adversarial inputs both during training and prediction (e.g., decision making), possibly by designing new machine learning models and network architectures, leveraging provenance to track down fraudulent data sources, and replaying to redo decisions after eliminating the fraudulent sources.
Research: Build AI systems that (1) can learn across multiple data sources without leaking information from a data source during training or serving, and (2) provide incentives to potentially competing organizations to share their data or models.
Research: (1) Design domain-specific hardware architectures to improve the performance and reduce power consumption of AI applications by orders of magnitude, or enhance the security of these applications. (2) Design AI software systems to take advantage of these domain-specific architectures, resource disaggregation architectures, and future non-volatile storage technologies.
Research: Design AI systems and APIs that allow the composition of models and actions in a modular and flexible manner, and develop rich libraries of models and options using these APIs to dramatically simplify the development of AI applications.
Research: Design cloud-edge AI systems that (1) leverage the edge to reduce latency, improve safety and security, and implement intelligent data retention techniques, and (2) leverage the cloud to share data and models across edge devices, train sophisticated computation-intensive models, and take high quality decisions.
1) In 2009, there was a similar position paper from Berkeley called "Above the Clouds: A Berkeley View of Cloud Computing". That paper did a very good job of summarizing, framing, and selling the cloud computing idea to the academia. But it looks like the research agenda/directions from that report didn't fare very well after 8 years---which is totally expected. Plans are useless but planning is indispensable. The areas of interest change after some time and the research adapts to it. It is impossible to tightly plan and manage exploratory research in CS areas (maybe this is different in biology and sciences areas.)

I think it is a YES for items 4, 5, 6, and partial for the rest, with very little progress in items 2 and 9. While the opportunities did not include them, the following developments have since reshaped the cloud computing landscape:
So even though the AI-systems agenda from Berkeley makes a lot of sense, it will be instructive to watch how these pan out and what unexpected big AI-systems areas open up in the coming years.
2) Stanford also released a similar position paper earlier this year, although theirs was for a limited scope/question for developing a [re]usable infrastructure for ML. Stanford's DAWN project aims to target end-to-end ML workflows, empower domain experts, and optimize end-to-end. This figure summarizes their vision for the reusable ML stack:

Of course, again, this inevitably reflects the strengths and biases of the Stanford team; they are more on the database, datascience, production side of things. It looks like this has some commonalities with the AI-specific architectures section of the Berkeley report, but different approaches are proposed for the same questions.
3) For R2: Robust decisions, it seems like formal methods, modeling, invariant-based reasoning, can be useful, especially when concurrency control becomes an issue in distributed ML deployments.
The paper motivates the systems agenda by discussing how systems research/development played a crucial role in fueling AI’s recent success. It says that the remarkable progress in AI has been made possible by a "perfect storm" emerging over the past two decades, bringing together: (1) massive amounts of data, (2) scalable computer and software systems, and (3) the broad accessibility of these technologies.
The rest of the paper talks about the trends in AI and how those map to their systems research agenda for AI.
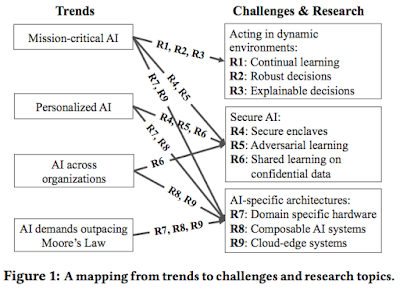
Trends and challenges
The paper identifies 4 basic trends in the AI area:- Mission-critical AI: Design AI systems that learn continually by interacting with a dynamic environment in a timely, robust, and secure manner.
- Personalized AI: Design AI systems that enable personalized applications and services while respecting users’ privacy and security.
- AI across organizations: Design AI systems that can train on datasets owned by different organizations without compromising their confidentiality. (I think it was possible to simplify presentation by combining this with the Personalized AI.)
- AI demands outpacing the Moore’s Law: Develop domain-specific architectures and distributed software systems to address the performance needs of future AI applications in the post-Moore’s Law era.

Acting in dynamic environments
R1: Continual learning
Despite Reinforcement Learning (RL)'s successes (Atari games, AlphaGo in chess and Go games), RL has not seen widescale real-world application. The paper argues that coupling advances in RL algorithms with innovations in systems design will drive new RL applications.Research: (1) Build systems for RL that fully exploit parallelism, while allowing dynamic task graphs, providing millisecond-level latencies, and running on heterogeneous hardware under stringent deadlines. (2) Build systems that can faithfully simulate the real-world environment, as the environment changes continually and unexpectedly, and run faster than real time.
https://muratbuffalo.blogspot.com/2017/12/paper-summary-real-time-machine.html
Of course, the second part here refers to research described in "Real-Time Machine Learning: The Missing Pieces". Simulated Reality (SR) focuses on continually simulating the physical world with which the agent is interacting. Trying to simulate multiple possible futures of a physical environment in high fidelity within a couple milliseconds is a very ambitious goal. But research here can also help other fields, so this is interesting.
R2: Robust decisions
The challenges here are: (1) robust learning in the presence of noisy and adversarial feedback, and (2) robust decision-making in the presence of unforeseen and adversarial inputs.Research: (1) Build fine grained provenance support into AI systems to connect outcome changes (e.g., reward or state) to the data sources that caused these changes, and automatically learn causal, source-specific noise models. (2) Design API and language support for developing systems that maintain confidence intervals for decision-making, and in particular can flag unforeseen inputs.
R3: Explainable decisions
Here we are in the domain of causal inference, a field "which will be essential in many future AI applications, and one which has natural connections to diagnostics and provenance ideas in databases."Research: Build AI systems that can support interactive diagnostic analysis, that faithfully replay past executions, and that can help to determine the features of the input that are responsible for a particular decision, possibly by replaying the decision task against past perturbed inputs. More generally, provide systems support for causal inference.
Secure AI
R4: Secure enclaves
A secure enclave is a secure execution environment—which protects the application running within from malicious code running outside.Research: Build AI systems that leverage secure enclaves to ensure data confidentiality, user privacy and decision integrity, possibly by splitting the AI system’s code between a minimal code base running within the enclave, and code running outside the enclave. Ensure the code inside the enclave does not leak information, or compromise decision integrity.
R5: Adversarial learning
The adaptive nature of ML algorithms opens the learning systems to new categories of attacks: evasion attacks and data poisoning attacks.Research: Build AI systems that are robust against adversarial inputs both during training and prediction (e.g., decision making), possibly by designing new machine learning models and network architectures, leveraging provenance to track down fraudulent data sources, and replaying to redo decisions after eliminating the fraudulent sources.
R6: Shared learning on confidential data
The paper observes that, despite the large volume of theoretical research, there are few practical differential privacy systems in use today, and proposes to simplify differential privacy use for real-world applications.Research: Build AI systems that (1) can learn across multiple data sources without leaking information from a data source during training or serving, and (2) provide incentives to potentially competing organizations to share their data or models.
AI specific architectures
R7: Domain specific hardware
The paper argues that "the one path left to continue the improvements in performance-energy-cost of processors is developing domain-specific processors." It mentions the Berkeley Firebox project, which proposes a multi-rack supercomputer that connects thousands of processor chips with thousands of DRAM chips and nonvolatile storage chips using fiber optics to provide low-latency, high-bandwidth, and long physical distance.Research: (1) Design domain-specific hardware architectures to improve the performance and reduce power consumption of AI applications by orders of magnitude, or enhance the security of these applications. (2) Design AI software systems to take advantage of these domain-specific architectures, resource disaggregation architectures, and future non-volatile storage technologies.
R8: Composable AI systems
The paper says modularity and composition will be key to increasing development speed and adoption of AI. The paper cites the Clipper project.Research: Design AI systems and APIs that allow the composition of models and actions in a modular and flexible manner, and develop rich libraries of models and options using these APIs to dramatically simplify the development of AI applications.
R9: Cloud-edge systems
The paper mentions the need to repurpose code to multiple heterogeneous platforms via re-targetable software design and compiler technology. It says "To address the wide heterogeneity of edge devices and the relative difficulty of upgrading the applications running on these devices, we need new software stacks that abstract away the heterogeneity of devices by exposing the hardware capabilities to the application through common APIs."Research: Design cloud-edge AI systems that (1) leverage the edge to reduce latency, improve safety and security, and implement intelligent data retention techniques, and (2) leverage the cloud to share data and models across edge devices, train sophisticated computation-intensive models, and take high quality decisions.
MAD questions
(The questions that led to these explanations are left as an exercise to the reader.)1) In 2009, there was a similar position paper from Berkeley called "Above the Clouds: A Berkeley View of Cloud Computing". That paper did a very good job of summarizing, framing, and selling the cloud computing idea to the academia. But it looks like the research agenda/directions from that report didn't fare very well after 8 years---which is totally expected. Plans are useless but planning is indispensable. The areas of interest change after some time and the research adapts to it. It is impossible to tightly plan and manage exploratory research in CS areas (maybe this is different in biology and sciences areas.)

I think it is a YES for items 4, 5, 6, and partial for the rest, with very little progress in items 2 and 9. While the opportunities did not include them, the following developments have since reshaped the cloud computing landscape:
- dominance of machine learning workloads in the cloud
- the rise of NewSQL systems, the trend for more consistent distributed databases, and the importance of coordination/Paxos/ZooKeeper in the cloud
- the development of online in-memory dataflow and stream processing systems, such as Spark, which came out of Berkeley
- the race towards finer-granularity virtualization via containers and functions as a service
- the prominence of SLAs (mentioned only once in the paper)
So even though the AI-systems agenda from Berkeley makes a lot of sense, it will be instructive to watch how these pan out and what unexpected big AI-systems areas open up in the coming years.
2) Stanford also released a similar position paper earlier this year, although theirs was for a limited scope/question for developing a [re]usable infrastructure for ML. Stanford's DAWN project aims to target end-to-end ML workflows, empower domain experts, and optimize end-to-end. This figure summarizes their vision for the reusable ML stack:

Of course, again, this inevitably reflects the strengths and biases of the Stanford team; they are more on the database, datascience, production side of things. It looks like this has some commonalities with the AI-specific architectures section of the Berkeley report, but different approaches are proposed for the same questions.
3) For R2: Robust decisions, it seems like formal methods, modeling, invariant-based reasoning, can be useful, especially when concurrency control becomes an issue in distributed ML deployments.






Comments