TensorFlow-Serving: Flexible, High-Performance ML Serving
This paper by Google appeared at NIPS 2017. The paper presents a system/framework to serve machine learning (ML) models.
The paper gives a nice motivation for why there is a need for productizing model-serving using a reusable, flexible, and extendable framework. ML serving infrastructure were mostly ad-hoc non-reusable solutions, e.g. "just put the models in a BigTable, and write a simple server that loads from there and handles RPC requests to the models."
However, those solutions quickly get complicated and intractable as they add support for:
+ model versioning (for model updates with a rollback option)
+ multiple models (for experimentation via A/B testing)
+ ways to prevent latency spikes for other models or versions concurrently serving, and
+ asynchronous batch scheduling with cross-model interleaving (for using GPUs and TPUs).
This work reminded me of the Facebook Configerator. It solves the configuration management/deployment problem but for ML models.
(1) a C++ library consisting of APIs and modules from which to construct an ML server,
(2) an assemblage of the library modules into a canonical server binary, and
(3) a hosted service.
The framework can serve TensorFlow models as well as other types of ML models. The libraries, and an instance of the binary, are provided as open-source.
In the model lifecycle management, the paper mentions "the canary and rollback" usecase. By default the Source aspires the latest (largest numbered) version of each /servable/, but you can override it and go with a canary/rollback policy. Here after the newest version is deployed, the system continues to send all prediction request traffic to the (now) second-newest version, while also teeing a sample of the traffic to the newest version to enable a comparison of their predictions. Once there is enough confidence in the newest version, the user would then switch to aspiring only that version and unloads the second-newest one. If a flaw is detected with the current primary serving version (which was not caught via canary), the user can request to rollback to aspiring a specific older version.
While optimizing for fast inference is mentioned as a theme, the paper does not elaborate on this. It just says that the framework can support using TPUs/GPUs by performing inter-request batching similar to the one in https://arxiv.org/pdf/1705.07860.pdf.
While the paper mentions that the framework can serve even lookup tables that encode feature transformations, there is no explanation whether any special optimization is (or can be) employed for improving the performance for serving different types of models. For example, for the nonparametric and sparse models that are popularly used in recommendation systems, would the framework provide optimizations for faster lookup/inference?
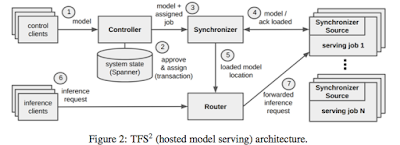
In the figure above, the synchronizer is the master that commands and monitors the workers serving the jobs. The router component is interesting; the paper mentions it uses a hedged backup requests to mitigate latency spikes. This means the request is sent to multiple job servers and the earliest response is used; effective protection against stragglers.
The paper gives a nice motivation for why there is a need for productizing model-serving using a reusable, flexible, and extendable framework. ML serving infrastructure were mostly ad-hoc non-reusable solutions, e.g. "just put the models in a BigTable, and write a simple server that loads from there and handles RPC requests to the models."
However, those solutions quickly get complicated and intractable as they add support for:
+ model versioning (for model updates with a rollback option)
+ multiple models (for experimentation via A/B testing)
+ ways to prevent latency spikes for other models or versions concurrently serving, and
+ asynchronous batch scheduling with cross-model interleaving (for using GPUs and TPUs).
This work reminded me of the Facebook Configerator. It solves the configuration management/deployment problem but for ML models.
"What is even more surprising than daily Facebook code deployment is this: Facebook's various configurations are changed even more frequently, currently thousands of times a day. And hold fast: every single engineer can make live configuration changes! ... Discipline sets you free. By being disciplined about the deployment process, by having built the configerator, Facebook lowers the risks for deployments and can give freedom to its developers to deploy frequently."The paper is also related to the "TFX: A TensorFlow-Based Production-Scale Machine Learning Platform" paper. While that one focused on the data management and model training side of things, this one focuses more on model serving.
The model serving framework
The TensorFlow-Serving framework, the paper presents can be used in any of these ways:(1) a C++ library consisting of APIs and modules from which to construct an ML server,
(2) an assemblage of the library modules into a canonical server binary, and
(3) a hosted service.
The framework can serve TensorFlow models as well as other types of ML models. The libraries, and an instance of the binary, are provided as open-source.
The TensorFlow Serving library
The library has two parts: (1) lifecycle management modules that decide which models to load into memory, sequence the loading/unloading of specific versions, and offer reference-counted access to them; (2) modules that service RPC requests to carry out inference using loaded models, with optional cross-request batching.In the model lifecycle management, the paper mentions "the canary and rollback" usecase. By default the Source aspires the latest (largest numbered) version of each /servable/, but you can override it and go with a canary/rollback policy. Here after the newest version is deployed, the system continues to send all prediction request traffic to the (now) second-newest version, while also teeing a sample of the traffic to the newest version to enable a comparison of their predictions. Once there is enough confidence in the newest version, the user would then switch to aspiring only that version and unloads the second-newest one. If a flaw is detected with the current primary serving version (which was not caught via canary), the user can request to rollback to aspiring a specific older version.
While optimizing for fast inference is mentioned as a theme, the paper does not elaborate on this. It just says that the framework can support using TPUs/GPUs by performing inter-request batching similar to the one in https://arxiv.org/pdf/1705.07860.pdf.
While the paper mentions that the framework can serve even lookup tables that encode feature transformations, there is no explanation whether any special optimization is (or can be) employed for improving the performance for serving different types of models. For example, for the nonparametric and sparse models that are popularly used in recommendation systems, would the framework provide optimizations for faster lookup/inference?
The TensorFlow serving hosted service
With the hosted service, Google likes to capture the users who has money and wants a no-fuss solution. To use the hosted service, the user just uploads her model to it and it gets served. It looks like the hosted service is also integrated with a datacenter resource management and scheduler as well. The hosted service also offers features such as validating model quality before serving a new version, or logging inferences to catch training/serving skew bugs.
In the figure above, the synchronizer is the master that commands and monitors the workers serving the jobs. The router component is interesting; the paper mentions it uses a hedged backup requests to mitigate latency spikes. This means the request is sent to multiple job servers and the earliest response is used; effective protection against stragglers.





Comments