Modular Composition of Coordination Services
This paper appeared in Usenix ATC'16 last week. The paper considers the problem of scaling ZooKeeper to WAN deployments. (Check this earlier post for a brief review of ZooKeeper.)
The paper suggests a client-side only modification to ZooKeeper, and calls the resultant system ZooNet. ZooNet consists of a federation of ZooKeeper cluster at each datacenter/region. ZooNet assumes the workload is highly-partitionable, so the data is partitioned among the ZooKeeper clusters, each accompanied by learners in the remote datacenter/regions. Each ZooKeeper cluster processes only updates for its own data partition and if applications in different regions need to access unrelated items they can also do so independently and in parallel at their own site.
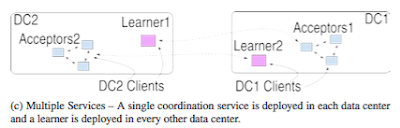
However, the problem with such a deployment is that it does not preserve ZooKeeper's sequential execution semantics. Consider the example in Figure 1. (It is not clear to me why the so-called "loosely-coupled" applications in different ZooKeeper partitions need to be sequentially serialized. The paper does not give an examples/reasons for motivating this.)

Their solution is fairly simple. ZooNet achieves consistency by injecting sync requests. Their algorithm only makes the remote partition reads to be synced to achieve coordination. More accurately, they insert a sync every time a client's read request accesses a different coordination service than the previous request. Subsequent reads from the same coordination service are naturally ordered after the first, and so no additional syncs are needed.

Figure 3 demonstrates the solution. I still have some problems with Figure 3. What if both syncs occur at the same time? I mean what if both occurs after the previous updates complete. Do they, then, prioritize one site over the other and take a deterministic order to resolve ties?
The paper also mentions that they fix a performance bug in ZooKeeper, but the bug is not relevant to the algorithm/problem. It is about more general ZooKeeper performance improvement by performing proper client isolation in the ZooKeeper commit processor.
ZooNet evaluation is done only with a 2-site ZooKeeper deployment. The evaluation did not look at WAN latency and focused on pushing the limits on throughput. Reads are asynchronously pipelined to compensate for the latency introduced by the sync operation. They benchmark the throughput when the system is saturated, which is not a typical ZooKeeper use case scenario.
ZooNet does not support transactions and watches.
Update 7/1/16: Kfir, the lead author of the ZooNet work, provides clarifications for the questions/concerns in my review. See the top comment after the post.
The paper suggests a client-side only modification to ZooKeeper, and calls the resultant system ZooNet. ZooNet consists of a federation of ZooKeeper cluster at each datacenter/region. ZooNet assumes the workload is highly-partitionable, so the data is partitioned among the ZooKeeper clusters, each accompanied by learners in the remote datacenter/regions. Each ZooKeeper cluster processes only updates for its own data partition and if applications in different regions need to access unrelated items they can also do so independently and in parallel at their own site.
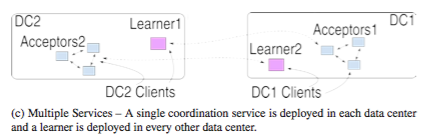
However, the problem with such a deployment is that it does not preserve ZooKeeper's sequential execution semantics. Consider the example in Figure 1. (It is not clear to me why the so-called "loosely-coupled" applications in different ZooKeeper partitions need to be sequentially serialized. The paper does not give an examples/reasons for motivating this.)
Their solution is fairly simple. ZooNet achieves consistency by injecting sync requests. Their algorithm only makes the remote partition reads to be synced to achieve coordination. More accurately, they insert a sync every time a client's read request accesses a different coordination service than the previous request. Subsequent reads from the same coordination service are naturally ordered after the first, and so no additional syncs are needed.
Figure 3 demonstrates the solution. I still have some problems with Figure 3. What if both syncs occur at the same time? I mean what if both occurs after the previous updates complete. Do they, then, prioritize one site over the other and take a deterministic order to resolve ties?
The paper also mentions that they fix a performance bug in ZooKeeper, but the bug is not relevant to the algorithm/problem. It is about more general ZooKeeper performance improvement by performing proper client isolation in the ZooKeeper commit processor.
ZooNet evaluation is done only with a 2-site ZooKeeper deployment. The evaluation did not look at WAN latency and focused on pushing the limits on throughput. Reads are asynchronously pipelined to compensate for the latency introduced by the sync operation. They benchmark the throughput when the system is saturated, which is not a typical ZooKeeper use case scenario.
ZooNet does not support transactions and watches.
Update 7/1/16: Kfir, the lead author of the ZooNet work, provides clarifications for the questions/concerns in my review. See the top comment after the post.





Comments
>Need for serialization
We tried to provide the semantics of ZooKeeper across datacenters. It may be that for some applications ZooKeeper’s semantics are not necessary. But there are others, where clients should see each other’s updates in a consistent manner, even if they are in different data-centers, which is what our solution provides.
>What if both syncs occur at the same time?
Each sync is invoked independently by its respective client and in this example sent to a different zookeeper instance. If both syncs occur after the writes complete, the reads will both see the written value due to linearizability.
>Performance bug in ZooKeeper
We explain this briefly at the end of Section 4.1.1 but perhaps should have elaborated more. In the “usual way” ZooKeeper is deployed across WAN, i.e., voters in one DC and an observer in another, all traffic from the remote DC goes through the observer. Observers experienced the performance issue we found, and hence the improvement of our solution over ZooKeeper was extremely high. We didn’t want to present numbers which are boosted by what we perceived to be a bug in ZooKeeper, so we first fixed the bug, and then compared our solution to ZooKeeper, showing that the improvement is still 7x.
>2-site ZooKeeper deployment.
We evaluated the solution with 5 DCs, and the improvement was even better. This isn’t in the paper, you’re right.
>Reads are asynchronously pipelined to compensate for the latency introduced by the sync operation.
Asynchronous operations is the usual way ZooKeeper is used. There is no reason to wait for completion after each op unless the application requires it. Nevertheless, a large part of the evaluation focuses on the overhead of syncs.
>Benchmark the throughput when the system is saturated.
This is the way ZooKeeper was benchmarked in the original ZooKeeper paper, which allowed us to have a comparison.
>ZooNet does not support transactions and watches.
The only form of transactions in ZooKeeper currently is a multi update operation and indeed, we don’t support multi updates which mix updates to different data-centers. It would be interesting to solve this, in particular if there’s a compelling use-case.
Wrt watches, each client maintains a session with all the zookeeper clusters it operates on, including watches.
Finally, to simplify adoption, we wanted a solution that’s applicable to ZooKeeper with minimal changes. Our solution doesn’t require any server-side changes to ZooKeeper (besides the isolation fix, which we already contributed to ZooKeeper).