Paper review: Measuring and Understanding Consistency at Facebook
I have reviewed many Facebook papers in this blog before (see the links at the bottom for full list). Facebook papers are simple (in the good sense of the word) and interesting due to the huge scale of operation at Facebook. They are testaments of high scalability in practice. This one here is no different.
This paper investigates the consistency of the Facebook TAO system. The TAO system is a replicated storage system for Facebook's social graph of billion vertices. In theory, TAO provides only eventual consistency. The interesting result in this paper is this: In practice, Facebook's TAO system is highly consistent, with only 5 inconsistency violations out of a million read requests!
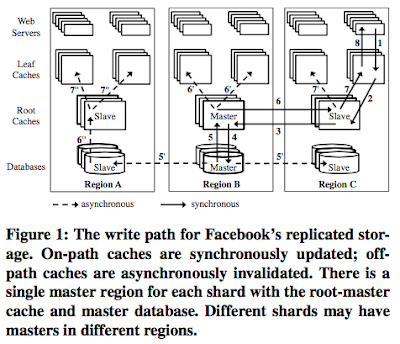
Read requests from web servers are served by the corresponding leaf cache in the local region (the cache-hit ratios are very high), and if that fails it progresses down the stack to be served by the root cache, and if that also fails, by the local database.
Write requests are complicated. The update needs to be reflected at the master database so the write is routed all the way to the master database and back, following the path 1, 2, 3, 4, 5, 6, 7, 8 in Figure 1. Each of those caches in that route applies the write when it forwards the database's acknowledgment back towards the client.
When the data is updated at the master database, the old data in other caches (those not in the route to the writing client) need to be updated as well. TAO does not go for the update, but goes for the lazy strategy: invalidation of those old data in the other caches. When a read comes from those other paths, the read will cause a miss, and later populate the caches with the updated value learned from the regional database. This lazy strategy also has the advantage of being simple and avoiding inadvertantly messing things (such as ordering of writes). TAO chooses to delete cached data instead of updating it in cache because deletes are idempotent. The database is the authoritative copy, and caches, are just, well, caches.
So, how does the invalidation of caches in other routes work. This proceeds in an asynchronous fashion. The root caches in the master (6') and originating regions (7') both asynchronously invalidate the other leaf caches in their region. The master database asynchronously replicates the write to the slave regions (5'). When a slave database in a region that did not originate the write receives it, the database asynchronously invalidates its root cache (6'') that in turn asynchronously invalidates all its leaf caches (7'').
This asynchronous invalidation of caches result in a "vulnerability time window" where inconsistent reads can happen. In theory, TAO provides per-object sequential consistency and read-after-write consistency within a cache, and only eventual consistency across caches.
Well, that is in theory, but what about in practice? How can one quantify the consistency of Facebook TAO?
Here are the consistency properties considered (going from stronger to weaker): linearizability, per-object sequential consistency, read-after write consistency, and eventual consistency. Linearizability means that there exists a total order over all operations in the system (where each operation appears to take effect instantaneously at some point between when the client invokes the operation and it receives the response), and that this order is consistent with the real-time order of operations. Per object-sequential consistency means that there exists a legal, total order over all requests to each object that is consistent with client’s orders. Read-After-Write means that when a write request has committed, all following read requests to that cache always reflect this write or later writes.

The offline checker converts dependencies between reads and writes into a dependency graph and checks for cycles in the dependency graph. Cycle means a linearizability anomaly. The same technique is also used for checking weaker local-consistency models, per-object consistency, and read-after write consistency. They check for total ordering versus real-time ordering and can process these weaker local-consistency models accordingly.

How come inconsistencies are so rare considering TAO provides only eventual consistency in theory? What gives? This stems from the following feature of Facebook TAO: "writes are rare". (Check Table 2.) In the traces you need both write and reads to an object to see inconsistency. And only 10%-25% of objects has both. Even then, a write is rare, and a read does not immediately follow write. Even when a read immediately follows write there is access locality, the read comes from the same region where the cache is already updated. These all contribute to keep inconsistency rate very low, at 4 in a million.

The paper also considers edge update consistency, which return similar results to vertex consistency. An interesting finding here is that 60% of all observed edge anomalies are related to ‘like’ edges.
Phi consistency is an incomparable query with linearizability and other local-consistency queries, because it is an instant-query, and does not depend on history like the former. So what good is it? It is still good for catching errors. If for some reason (bad configuration, operator error) caches are not maintained properly (e.g., cache invalidations screw up, etc) these phi queries will catch that problem in real-time and warn.

How generalizable is this finding to other eventual-consistency systems? Of course we need to understand this finding with its limitations. This finding applies for a social network system updated with real-time human actions, so the data does not change very fast. And when it does, usually there is no immediate read request from other regions due to access locality, so we don't see much inconsistency. Another limitation to the study is that the way they sample ~1000 vertices out of a billion may not capture the power law model of the social graph. What about celebraties that have many followers, their posts are bound to see more traffic and prone to more inconsistency problems, no? I think the paper should have investigated the vertices with respect to their popularity tiers: high, medium, low.
Finally another limitation is this. This work considers local consistency model. Local consistency means whenever each individual object provides C, the entire system also provides C. This property is satisfied by linearizability, per-object sequential consistency, read-after write consistency, and eventual consistency, but is not satisfied by causally-consistent and transactional consistency models. The paper has this to say on the topic: "Transactional isolation is inherently a non-local property and so we cannot measure it accurately using only a sample of the full graph. This unfortunately means we cannot quantify the benefits of consistency models that include transactions, e.g., serializability and snapshot isolation, or the benefit of even read-only transactions on other consistency models. For instance, while our results for causal consistency bound the benefit of the COPS system, they do not bound the benefit of the COPS-GT system that also includes read-only transactions."

Probabilistically bounded staleness
Facebook's software architecture
Facebook's Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
Holistic Configuration Management at Facebook
Scaling Memcache at Facebook
Finding a Needle in Haystack: Facebook's Photo Storage
One Trillion Edges, Graph Processing at Facebook-Scale
This paper investigates the consistency of the Facebook TAO system. The TAO system is a replicated storage system for Facebook's social graph of billion vertices. In theory, TAO provides only eventual consistency. The interesting result in this paper is this: In practice, Facebook's TAO system is highly consistent, with only 5 inconsistency violations out of a million read requests!
Facebook's TAO system
TAO is basically 2-level memcached architecture backed by a database, as first discussed in NSDI'13 paper. TAO architecture is given in Figure 1. As a prerequisite to TAO consistency discussion in the next section, it will be enough to review how TAO serves read and write requests below.
Read requests from web servers are served by the corresponding leaf cache in the local region (the cache-hit ratios are very high), and if that fails it progresses down the stack to be served by the root cache, and if that also fails, by the local database.
Write requests are complicated. The update needs to be reflected at the master database so the write is routed all the way to the master database and back, following the path 1, 2, 3, 4, 5, 6, 7, 8 in Figure 1. Each of those caches in that route applies the write when it forwards the database's acknowledgment back towards the client.
When the data is updated at the master database, the old data in other caches (those not in the route to the writing client) need to be updated as well. TAO does not go for the update, but goes for the lazy strategy: invalidation of those old data in the other caches. When a read comes from those other paths, the read will cause a miss, and later populate the caches with the updated value learned from the regional database. This lazy strategy also has the advantage of being simple and avoiding inadvertantly messing things (such as ordering of writes). TAO chooses to delete cached data instead of updating it in cache because deletes are idempotent. The database is the authoritative copy, and caches, are just, well, caches.
So, how does the invalidation of caches in other routes work. This proceeds in an asynchronous fashion. The root caches in the master (6') and originating regions (7') both asynchronously invalidate the other leaf caches in their region. The master database asynchronously replicates the write to the slave regions (5'). When a slave database in a region that did not originate the write receives it, the database asynchronously invalidates its root cache (6'') that in turn asynchronously invalidates all its leaf caches (7'').
This asynchronous invalidation of caches result in a "vulnerability time window" where inconsistent reads can happen. In theory, TAO provides per-object sequential consistency and read-after-write consistency within a cache, and only eventual consistency across caches.
Well, that is in theory, but what about in practice? How can one quantify the consistency of Facebook TAO?
Consistency analysis setup
To answer this question, the authors develop an offline checker-based consistency analysis. A random subset of the Facebook graph is chosen for monitoring. Random sampling is done for 1 vertex out of a million, so this is for ~1000 vertices. Every request for these ~1000 vertices are logged during their 12 day experiment (the trace contains over 2.7 billion requests), and later analyzed by the offline checker they developed for consistency violations.Here are the consistency properties considered (going from stronger to weaker): linearizability, per-object sequential consistency, read-after write consistency, and eventual consistency. Linearizability means that there exists a total order over all operations in the system (where each operation appears to take effect instantaneously at some point between when the client invokes the operation and it receives the response), and that this order is consistent with the real-time order of operations. Per object-sequential consistency means that there exists a legal, total order over all requests to each object that is consistent with client’s orders. Read-After-Write means that when a write request has committed, all following read requests to that cache always reflect this write or later writes.

The offline checker converts dependencies between reads and writes into a dependency graph and checks for cycles in the dependency graph. Cycle means a linearizability anomaly. The same technique is also used for checking weaker local-consistency models, per-object consistency, and read-after write consistency. They check for total ordering versus real-time ordering and can process these weaker local-consistency models accordingly.
Consistency evaluation results
Check Table 3 for the consistency evaluation results. It turns out the linearizability inconsistencies are very low: 0.0004% And this gets even lower if you consider read-after-write within a single region/cluster: 0.00006%.
How come inconsistencies are so rare considering TAO provides only eventual consistency in theory? What gives? This stems from the following feature of Facebook TAO: "writes are rare". (Check Table 2.) In the traces you need both write and reads to an object to see inconsistency. And only 10%-25% of objects has both. Even then, a write is rare, and a read does not immediately follow write. Even when a read immediately follows write there is access locality, the read comes from the same region where the cache is already updated. These all contribute to keep inconsistency rate very low, at 4 in a million.

The paper also considers edge update consistency, which return similar results to vertex consistency. An interesting finding here is that 60% of all observed edge anomalies are related to ‘like’ edges.
The high update and request rate of “likes” explains their high contribution to the number of overall anomalies. The high update rate induces many vulnerability windows during which anomalies could occur and the high request rate increases the likelihood a read will happen during that window. The top 10 types (of edges) together account for ~95% of the anomalies. These most-anomalous edge types have implications for the design of systems with strong consistency.
Online practical consistency monitoring for Facebook TAO
Offline checker is expensive so it cannot be used as online. For online, Facebook uses a heuristic to monitor the consistency of their TAO system in production: phi consistency checking. This is is a snapshot query to check if all caches return the same result for a given object. This is basically a measure of how closely synchronized the caches are within regions (phi(R)) and globally (phi(G)).Phi consistency is an incomparable query with linearizability and other local-consistency queries, because it is an instant-query, and does not depend on history like the former. So what good is it? It is still good for catching errors. If for some reason (bad configuration, operator error) caches are not maintained properly (e.g., cache invalidations screw up, etc) these phi queries will catch that problem in real-time and warn.

So, what did we learn?
Although TAO provides only eventual-consistency in theory, it turns out TAO is highly consistent in practice, with only 5 out of a million read-requests resulting in a linearizability violation.How generalizable is this finding to other eventual-consistency systems? Of course we need to understand this finding with its limitations. This finding applies for a social network system updated with real-time human actions, so the data does not change very fast. And when it does, usually there is no immediate read request from other regions due to access locality, so we don't see much inconsistency. Another limitation to the study is that the way they sample ~1000 vertices out of a billion may not capture the power law model of the social graph. What about celebraties that have many followers, their posts are bound to see more traffic and prone to more inconsistency problems, no? I think the paper should have investigated the vertices with respect to their popularity tiers: high, medium, low.
Finally another limitation is this. This work considers local consistency model. Local consistency means whenever each individual object provides C, the entire system also provides C. This property is satisfied by linearizability, per-object sequential consistency, read-after write consistency, and eventual consistency, but is not satisfied by causally-consistent and transactional consistency models. The paper has this to say on the topic: "Transactional isolation is inherently a non-local property and so we cannot measure it accurately using only a sample of the full graph. This unfortunately means we cannot quantify the benefits of consistency models that include transactions, e.g., serializability and snapshot isolation, or the benefit of even read-only transactions on other consistency models. For instance, while our results for causal consistency bound the benefit of the COPS system, they do not bound the benefit of the COPS-GT system that also includes read-only transactions."

Related links
Conference presentation video of this paperProbabilistically bounded staleness
Facebook's software architecture
Facebook's Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
Holistic Configuration Management at Facebook
Scaling Memcache at Facebook
Finding a Needle in Haystack: Facebook's Photo Storage
One Trillion Edges, Graph Processing at Facebook-Scale



Comments
but i have question about the consistency model using within each cluster.
Could you please help me to understand them?
thanks in advance..