Facebook's Mystery Machine: End-to-end Performance Analysis of Large-scale Internet Services
This paper appeared in OSDI'14, and is authored by Michael Chow, University of Michigan; David Meisner, Facebook, Inc.; Jason Flinn, University of Michigan; Daniel Peek, Facebook, Inc.; Thomas F. Wenisch, University of Michigan.
The goal of this paper is very similar to that of Google Dapper (you can read my summary of Google Dapper here). Both work try to figure out bottlenecks in performance in high fanout large-scale Internet services. Both work use similar methods, however this work (the mystery machine) tries to accomplish the task relying on less instrumentation than Google Dapper. The novelty of the mystery machine work is that it tries to infer the component call graph implicitly via mining the logs, where as Google Dapper instrumented each call in a meticulous manner and explicitly obtained the entire call graph.
The motivation for this approach is that comprehensive instrumentation as in Google Dapper requires standardization....and I am quoting the rest from the paper:
While the paper says it doesn't want to interfere with the instrumentation, of course it has to interfere to establish a minimum standard in the resulting collection of individual software component logs, which they call UberTrace. (Can you find a more Facebooky name than UberTrace---which the paper spells as ÜberTrace, but I spare you here---?)

For the analysis in the paper, they use traces of over 1.3 million requests to the Facebook home page gathered over 30 days. Was the sampling rate enough, statistically meaningful? Figure 3 says yes.

We know that for large scale Internet services, a single request may invoke 100s of (micro)services, and that many services can lead to 80K-100K relationships as shown in Figure 3. But it was still surprising to see that it took 400K traces for the call graph to start to converge to its final form. That must be one heck of a convoluted spaghetti of services.

Figure 5 is why critical path identification is important. Check the ratios on the right side.


And there are also a category of users/requests with no slack. For those, the server time dominates the critical path, as the network- and client-side latencies are very low.
This suggests a potential performance improvement by offering differentiated service based on the predicted amount of slack available per connection:

This approach requires normalizing/synchronizing local clock timestamps across computers. It seems like they are doing offline post-hoc clock synchronization by leveraging the RPC calls. (Does that mean further instrumentation of the RPC calls?)
Scaling Memcache at Facebook
Finding a needle in Haystack: Facebook's photo storage
Google Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
The goal of this paper is very similar to that of Google Dapper (you can read my summary of Google Dapper here). Both work try to figure out bottlenecks in performance in high fanout large-scale Internet services. Both work use similar methods, however this work (the mystery machine) tries to accomplish the task relying on less instrumentation than Google Dapper. The novelty of the mystery machine work is that it tries to infer the component call graph implicitly via mining the logs, where as Google Dapper instrumented each call in a meticulous manner and explicitly obtained the entire call graph.
The motivation for this approach is that comprehensive instrumentation as in Google Dapper requires standardization....and I am quoting the rest from the paper:
[Facebook systems] grow organically over time in a culture that favors innovation over standardization (e.g., "move fast and break things" is a well-known Facebook slogan). There is broad diversity in programming languages, communication middleware, execution environments, and scheduling mechanisms. Adding instrumentation retroactively to such an infrastructure is a Herculean task. Further, the end-to-end pipeline includes client software such as Web browsers, and adding detailed instrumentation to all such software is not feasible.
While the paper says it doesn't want to interfere with the instrumentation, of course it has to interfere to establish a minimum standard in the resulting collection of individual software component logs, which they call UberTrace. (Can you find a more Facebooky name than UberTrace---which the paper spells as ÜberTrace, but I spare you here---?)
UberTrace requires that log messages contain at least:In order not to incur a lot of overhead, UberTrace uses a low sampling rate of all requests to Facebook. But this necessitates another requirement on the logging:
1. A unique request identifier.
2. The executing computer (e.g., the client or a particular server)
3. A timestamp that uses the local clock of the executing computer
4. An event name (e.g., "start of DOM rendering").
5. A task name, where a task is defined to be a distributed thread of control.
UberTrace must ensure that the individual logging systems choose the same set of requests to monitor; otherwise the probability of all logging systems independently choosing to monitor the same request would be vanishingly small, making it infeasible to build a detailed picture of end-to-end latency. Therefore, UberTrace propagates the decision about whether or not to monitor a request from the initial logging component that makes such a decision through all logging systems along the path of the request, ensuring that the request is completely logged. The decision to log a request is made when the request is received at the Facebook Web server; the decision is included as part of the per-request metadata that is read by all subsequent components. UberTrace uses a global identifier to collect the individual log messages, extracts the data items enumerated above, and stores each message as a record in a relational database.
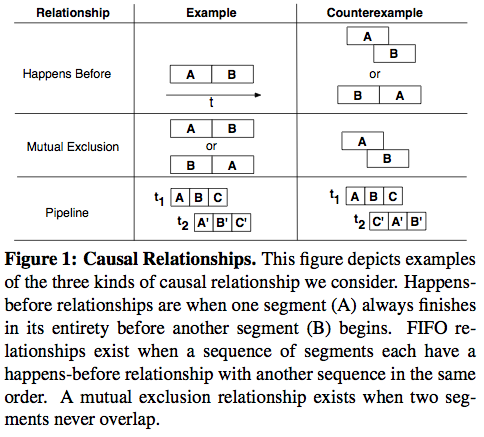
The mystery machine
To infer the call graph from the logs, the mystery machine starts with a call graph hypothesis and refines it gradually as each log trace provides some counterexample. Figure 1 and Figure 2 explain how the mystery machine generates the model via large scale mining of UberTrace.For the analysis in the paper, they use traces of over 1.3 million requests to the Facebook home page gathered over 30 days. Was the sampling rate enough, statistically meaningful? Figure 3 says yes.
We know that for large scale Internet services, a single request may invoke 100s of (micro)services, and that many services can lead to 80K-100K relationships as shown in Figure 3. But it was still surprising to see that it took 400K traces for the call graph to start to converge to its final form. That must be one heck of a convoluted spaghetti of services.
Findings
The mystery machine analysis is performed by running parallel Hadoop jobs.Figure 5 is why critical path identification is important. Check the ratios on the right side.
How can we use this analysis to improve Facebook's performance?
As Figure 9 showed, some users/requests have "slack" (another technical term this paper introduced). For the users/requests with slack, the server time constitutes only a very small fraction of the critical path, which the network- and client-side latencies dominate.And there are also a category of users/requests with no slack. For those, the server time dominates the critical path, as the network- and client-side latencies are very low.
This suggests a potential performance improvement by offering differentiated service based on the predicted amount of slack available per connection:
By using predicted slack as a scheduling deadline, we can improve average response time in a manner similar to the earliest deadline first real-time scheduling algorithm. Connections with considerable slack can be given a lower priority without affecting end-to-end latency. However, connections with little slack should see an improvement in end-to-end latency because they are given scheduling priority. Therefore, average latency should improve. We have also shown that prior slack values are a good predictor of future slack [Figure 11]. When new connections are received, historical values can be retrieved and used in scheduling decisions. Since calculating slack is much less complex than servicing the actual Facebook request, it should be feasible to recalculate the slack for each user approximately once per month.
Some limitations of the mystery machine
This approach assumes that the call graph is acyclic. With their request id based logging, they cannot handle the same event, task pair to appear multiple times for the same request trace.This approach requires normalizing/synchronizing local clock timestamps across computers. It seems like they are doing offline post-hoc clock synchronization by leveraging the RPC calls. (Does that mean further instrumentation of the RPC calls?)
Since all log timestamps are in relation to local clocks, UberTrace translates them to estimated global clock values by compensating for clock skew. UberTrace looks for the common RPC pattern of communication in which the thread of control in an individual task passes from one computer (called the client to simplify this explanation) to another, executes on the second computer (called the server), and returns to the client. UberTrace calculates the server execution time by subtracting the latest and earliest server timestamps (according to the server's local clock) nested within the client RPC. It then calculates the client-observed execution time by subtracting the client timestamps that immediately succeed and precede the RPC. The difference between the client and server intervals is the estimated network round-trip time (RTT) between the client and server. By assuming that request and response delays are symmetric, UberTrace calculates clock skew such that, after clock-skew adjustment, the first server timestamp in the pattern is exactly 1/2 RTT after the previous client timestamp for the task.This work also did not consider mobile users; 1.19 billion of 1.39 billion users are mobile users.
Related links
Facebook's software architectureScaling Memcache at Facebook
Finding a needle in Haystack: Facebook's photo storage
Google Dapper, a Large-Scale Distributed Systems Tracing Infrastructure





Comments