Clock-SI: Snapshot Isolation for Partitioned Data Stores Using Loosely Synchronized Clocks
This paper appeared in SRDS 2013, and is concerned with the snapshot isolation problem for distributed databases/data stores.
SI is a multiversion concurrency control scheme with 3 properties:
1) Each transaction reads from a consistent snapshot, taken at the start of the transaction and identified by a snapshot timestamp. A snapshot is consistent if it includes all writes of transactions committed before the snapshot timestamp, and if it does not include any writes of aborted transactions or transactions committed after the snapshot timestamp.
2) Update transactions commit in a total order. Every commit produces a new database snapshot, identified by the commit timestamp.
3) An update transaction aborts if it introduces a write-write conflict with a concurrent committed transaction. Transaction T1 is concurrent with committed update transaction T2, if T1 took its snapshot before T2 committed and T1 tries to commit after T2 committed.
When a transaction starts, its snapshot timestamp is set to the current value of the database version. All its reads are satisfied from the corresponding snapshot. To support snapshots, multiple versions of each data item are kept, each tagged with a version number equal to the commit timestamp of the transaction that creates the version. The transaction reads the version with the largest version number smaller than its snapshot timestamp. If the transaction is read-only, it always commits without further checks. If the transaction has updates, its writes are buffered in a workspace. When the update transaction requests to commit, a certification check verifies that the transaction writeset does not intersect with the writesets of concurrent committed transactions. If the certification succeeds, the database version is incremented, and the transaction commit timestamp is set to this value.
Clock-SI, instead, proposes a way to use loosely synchronized clocks to assign snapshot and commit timestamps to transactions. Compared to conventional SI, Clock-SI does not have a single point of failure and a potential performance bottleneck. It saves one round-trip message for a ready-only transaction (to obtain the snapshot timestamp), and two round-trip messages for an update transaction (to obtain the snapshot timestamp and the commit timestamp). A transaction's snapshot timestamp is the value of the local clock at the partition where it starts. Similarly, the commit timestamp of a local update transaction is obtained by reading the local clock.
If you read Google's Spanner paper, you know that Google Spanner solves this problem by introducing TrueTime, which uses atomic clocks.
1) to account for clock synchronization differences (epsilon) as in Fig1, and
2) to account for the pending commit of an update transaction.
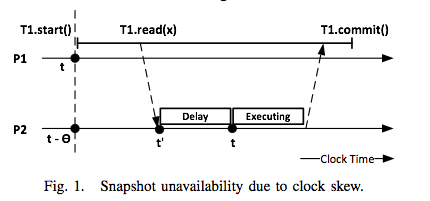
In Fig1, the read arrives at time t′ on P2's clock, before P2’s clock has reached the value t, and thus t′ < t. The snapshot with timestamp t at P2 is therefore not yet available. Another transaction on P2 could commit at time t′′, between t′ and t, and change the value of x. This new value should be included in T1's snapshot.

T2's snapshot is unavailable due to the commit in progress of transaction T1, which is assigned the value of the local clock, say t, as its commit timestamp. T1 updates item x and commits. The commit operation involves a write to stable storage and completes at time t′. Transaction T2 starts between t and t′, and gets assigned a snapshot timestamp t′′, t < t′′ < t′. If T2 issues a read for item x, we cannot return the value written by T1, because we do not yet know if the commit will succeed, but we can also not return the earlier value, because, if T1's commit succeeds, this older value will not be part of a consistent snapshot at t′′.
Here we find that HLC indeed improves the clock-SI problem of snapshot isolation if it is used instead of physical clocks. HLC avoids the delay in Figure 1. HLC would not incur the delay because it also uses happened-before information as encoded in HLC clocks.
What is snapshot isolation (SI)?
(I took these definitions almost verbatim from the paper.)SI is a multiversion concurrency control scheme with 3 properties:
1) Each transaction reads from a consistent snapshot, taken at the start of the transaction and identified by a snapshot timestamp. A snapshot is consistent if it includes all writes of transactions committed before the snapshot timestamp, and if it does not include any writes of aborted transactions or transactions committed after the snapshot timestamp.
2) Update transactions commit in a total order. Every commit produces a new database snapshot, identified by the commit timestamp.
3) An update transaction aborts if it introduces a write-write conflict with a concurrent committed transaction. Transaction T1 is concurrent with committed update transaction T2, if T1 took its snapshot before T2 committed and T1 tries to commit after T2 committed.
When a transaction starts, its snapshot timestamp is set to the current value of the database version. All its reads are satisfied from the corresponding snapshot. To support snapshots, multiple versions of each data item are kept, each tagged with a version number equal to the commit timestamp of the transaction that creates the version. The transaction reads the version with the largest version number smaller than its snapshot timestamp. If the transaction is read-only, it always commits without further checks. If the transaction has updates, its writes are buffered in a workspace. When the update transaction requests to commit, a certification check verifies that the transaction writeset does not intersect with the writesets of concurrent committed transactions. If the certification succeeds, the database version is incremented, and the transaction commit timestamp is set to this value.
What is the innovation in the Clock-SI paper?
The conventional SI implementations use a centralized timestamp authority for consistent versioning. This is because local clocks on different nodes may differ a lot (NTP synchronization may have 10s of ms of inaccuracies), and is not suitable for consistent versioning.Clock-SI, instead, proposes a way to use loosely synchronized clocks to assign snapshot and commit timestamps to transactions. Compared to conventional SI, Clock-SI does not have a single point of failure and a potential performance bottleneck. It saves one round-trip message for a ready-only transaction (to obtain the snapshot timestamp), and two round-trip messages for an update transaction (to obtain the snapshot timestamp and the commit timestamp). A transaction's snapshot timestamp is the value of the local clock at the partition where it starts. Similarly, the commit timestamp of a local update transaction is obtained by reading the local clock.
If you read Google's Spanner paper, you know that Google Spanner solves this problem by introducing TrueTime, which uses atomic clocks.
How does Clock-SI work?
Clock-SI essentially response-delays a read in a transaction1) to account for clock synchronization differences (epsilon) as in Fig1, and
2) to account for the pending commit of an update transaction.
In Fig1, the read arrives at time t′ on P2's clock, before P2’s clock has reached the value t, and thus t′ < t. The snapshot with timestamp t at P2 is therefore not yet available. Another transaction on P2 could commit at time t′′, between t′ and t, and change the value of x. This new value should be included in T1's snapshot.
T2's snapshot is unavailable due to the commit in progress of transaction T1, which is assigned the value of the local clock, say t, as its commit timestamp. T1 updates item x and commits. The commit operation involves a write to stable storage and completes at time t′. Transaction T2 starts between t and t′, and gets assigned a snapshot timestamp t′′, t < t′′ < t′. If T2 issues a read for item x, we cannot return the value written by T1, because we do not yet know if the commit will succeed, but we can also not return the earlier value, because, if T1's commit succeeds, this older value will not be part of a consistent snapshot at t′′.
Evaluation
The paper does not include a performance comparison to Spanner. The NTP synchronized clocks in the evaluation experiments have an NTP offset/epsilon less than 0.1 msec, which is actually more precise than Spanner's atomic clock! I guess this is thanks to the Gigabit Ethernet they use in their LAN deployment.Discussion: Use of Hybrid Logical Clocks (HLC) for the Clock-SI problem
HLC is a hybrid version of logical clocks and physical clocks, introduced by us recently, to combine the advantages of both clocks, while avoiding their disadvantages. Since HLC captures happened-before relationship and uses this extra information in ordering, it does not need to wait out uncertainty regions of physical clock synchronization. Dually, since HLC is related to physical clocks it allows querying with respect to physical time. We had shown HLC's advantages for the consistent snapshot problem in our work.Here we find that HLC indeed improves the clock-SI problem of snapshot isolation if it is used instead of physical clocks. HLC avoids the delay in Figure 1. HLC would not incur the delay because it also uses happened-before information as encoded in HLC clocks.




Comments
style is witty, keep doing what you're doing!