Paper summary: Can a decentralized metadata service layer benefit parallel filesystems?
Parallel filesystems do a good job of providing parallel and scalable access to the data transfer, but, due to consistency concerns, the metadata accesses are still directed to one metadata server (MDS) which becomes a bottleneck. This is a problem for scalability because studies show that over 75% of all filesystem calls require access to file metadata.
This paper proposes to adopt ZooKeeper as a decentralized MDS for parallel filesystems and test whether that improves performance. You can ask, what is decentralized about ZooKeeper, and you would be right about the update requests. But for read requests, ZooKeeper helps by allowing any ZooKeeper server to respond while guaranteeing consistency. (You would still need to do a sync operation if the request needs the read to be freshest and satisfy precedence order.)
If you recall, ZooKeeper uses a filesystem API to enable clients to build higher-level coordination primitives (group membership, locking, barrier sync). This paper is interesting because it takes ZooKeeper and uses it directly as a metadata server for a filesystem leveraging the filesystem API ZooKeeper exposes in a literal manner. FUSE is used to act as a glue between the ZooKeeper as MDS and the underlying physical storage filesystem.

A DUFS client instance does not interact directly with other DUFS clients; Any necessary interaction is made through ZooKeeper service. The figure shows the basic steps required to perform an open() operation on a file using DUFS.
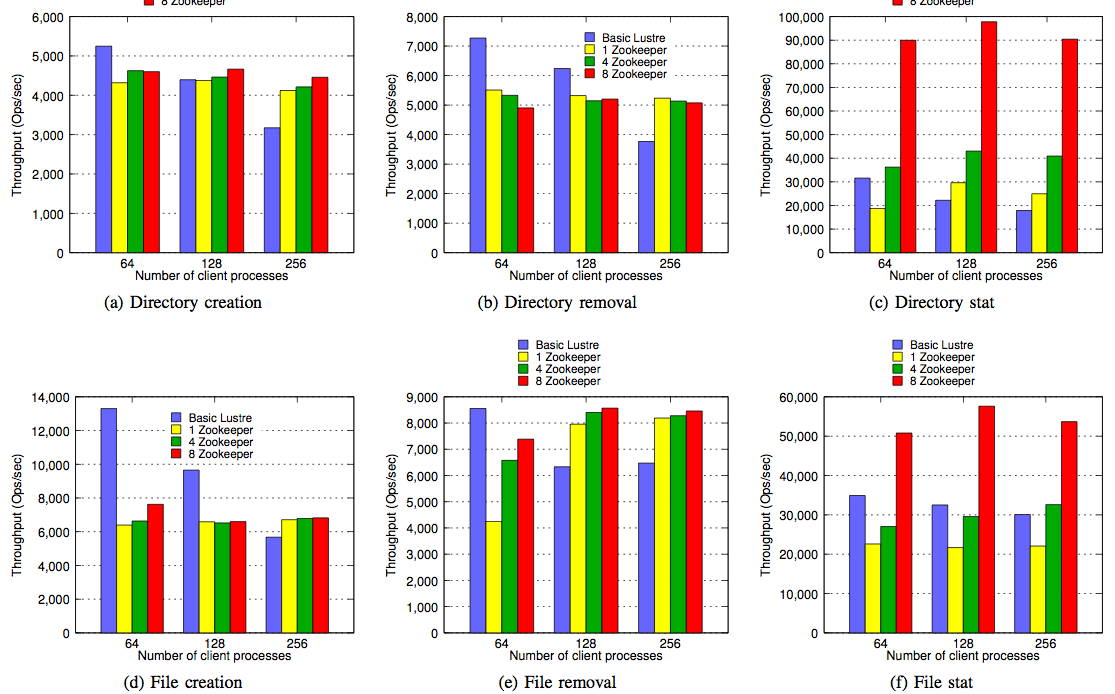
Alternatively, directory operations take place only at the metadata level, so only ZooKeeper is involved and not the back-end storage. For example, the directory stat() operation is satisfied at the Zookeeper itself (the back-end storage is not contacted) since we maintain the entire directory hierarchy in Zookeeper.
I am bugged by some of the limitations of the evaluation. In these tests the ZooKeeper servers are colocated (running on the same node) as the DUFS client. This naturally achieves wonders for read request latencies! But this is not a very reasonable set up. Moreover, the clients are not under the control of DUFS, so it is not a good idea to deploy your ZooKeeper servers on clients which are uncontrolled and can disconnect any time. Finally, this disallows clients from faraway. Of course ZooKeeper does not scale to WAN environment, and all the tests are done in a controlled cluster environment.

We are working on a scalable WAN version of ZooKeeper, and we will use the parallel filesystems as our application to showcase a WAN filesystem leveraging our prototype coordination system.
This paper proposes to adopt ZooKeeper as a decentralized MDS for parallel filesystems and test whether that improves performance. You can ask, what is decentralized about ZooKeeper, and you would be right about the update requests. But for read requests, ZooKeeper helps by allowing any ZooKeeper server to respond while guaranteeing consistency. (You would still need to do a sync operation if the request needs the read to be freshest and satisfy precedence order.)
If you recall, ZooKeeper uses a filesystem API to enable clients to build higher-level coordination primitives (group membership, locking, barrier sync). This paper is interesting because it takes ZooKeeper and uses it directly as a metadata server for a filesystem leveraging the filesystem API ZooKeeper exposes in a literal manner. FUSE is used to act as a glue between the ZooKeeper as MDS and the underlying physical storage filesystem.
Distributed Union FileSystem (DUFS) architecture
A DUFS client instance does not interact directly with other DUFS clients; Any necessary interaction is made through ZooKeeper service. The figure shows the basic steps required to perform an open() operation on a file using DUFS.
- A. The open() call is intercepted by FUSE which gives the virtual path of the file to DUFS.
- B. DUFS queries ZooKeeper to get the Znode based on the filename and to retrieve the file id (FID).
- C. DUFS uses the deterministic mapping function to find the physical path associated to the FID.
- D. Finally, DUFS opens the file based on its physical path. The result is returned to the application via FUSE.
Alternatively, directory operations take place only at the metadata level, so only ZooKeeper is involved and not the back-end storage. For example, the directory stat() operation is satisfied at the Zookeeper itself (the back-end storage is not contacted) since we maintain the entire directory hierarchy in Zookeeper.
Evaluation
These tests were performed on a Linux cluster. Each node has a dual Intel Xeon E5335 CPU (8 cores in total) and 6GB memory. A SATA 250GB hard drive is used as the storage device on each node. The nodes are connected with 1GigE.I am bugged by some of the limitations of the evaluation. In these tests the ZooKeeper servers are colocated (running on the same node) as the DUFS client. This naturally achieves wonders for read request latencies! But this is not a very reasonable set up. Moreover, the clients are not under the control of DUFS, so it is not a good idea to deploy your ZooKeeper servers on clients which are uncontrolled and can disconnect any time. Finally, this disallows clients from faraway. Of course ZooKeeper does not scale to WAN environment, and all the tests are done in a controlled cluster environment.
Conclusion
This paper investigates an interesting idea, that of using ZooKeeper as MDS of parallel filesystems to provide some scalability to the MDS. Thanks to the advantages of ZooKeeper, this allows improved read access because those can be served consistently from any ZooKeeper server. And, due to limitations of the ZooKeeper, this fails to address the scalability of update requests (throughput of update operations actually decrease as the number of ZooKeeper replicase increase) and also lacks the scalability needed for WAN deployments. Another limitation of this approach is that the metadata need to be able to fit into a single ZooKeeper server (and of course also the ZooKeeper replicas), so there is a scalability problem with respect to the filesystem size as well.We are working on a scalable WAN version of ZooKeeper, and we will use the parallel filesystems as our application to showcase a WAN filesystem leveraging our prototype coordination system.




Comments