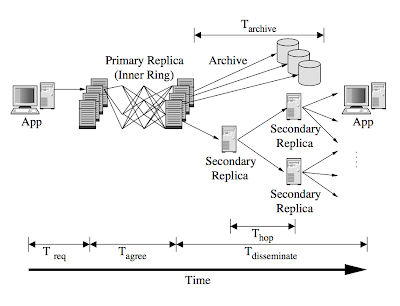
Volley: Automated Data Placement for Geo-Distributed Cloud Services

Datacenters today are distributed across the globe, yet they need to share data with other datacenters as well as their clients. This paper from Microsoft Research presents a heuristic strategy for data placement to these geo-distributed datacenters. While there has been previous work on data placement in LANs and WSNs, Volley is the first heuristic for data placement strategies for WANs. A simple heuristic is to place each data to the datacenter closest to the client of that data. But things are not that simple, there are several additional constraints to be considered, including business constraints, WAN bandwidth costs, datacenter capacity limits, data interdependencies, user-perceived latency, etc. For example, it makes more sense to collocate data that are tightly-coupled/interdependent, such as two friends in Facebook that update each other walls. As another example, the frequency of the clients accessing the data needs to be taken in to account as well. As live mesh and live m...