Pond: The Oceanstore prototype
This paper details the implementation of Pond, a distributed p2p filesystem for object-storage. Pond is a prototype implementation of Oceanstore, which was described here. Oceanstore is especially notable by its elegant solution to localization of objects in a P2P environment (employing Tapestry and using attenuated Bloom filters as hints for efficient search).
Architecture
The system architecture is two tiered. The first tier consists of well connected hosts which serialize updates (running Byzantine agreement) and archive results. The second tier provides extra storage/cache resources to the system.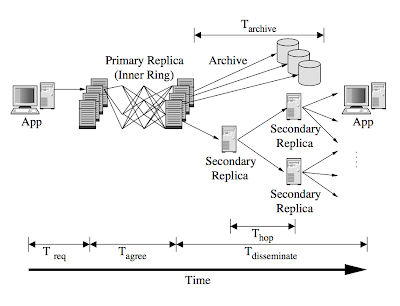
Replication and caching
Pond uses "erasure codes" idea for efficient and robust storage. Given storage is virtually unlimited today, they could as well have used full-replication and saved a lot of headache to themselves. The erasure coding leads to problems when reading. Several machines need to be contacted to reconstruct the block. What Pond does is, after a block is constructed it is kept at cache in the second tier replicas. So, the cost of consequent reads becomes low, and they compensate the initially high cost read.
Storing updates
Updates follow the path in Figure 2. Updates are both archived and cached simultaneously. The primary replica runs a Byzantine agreement, and the paper includes several implementation details related for that.
Implementation and evaluation
Pond is implemented on SEDA. This is a bit curious as Pond does not seem to have a long workflow. Was SEDA necessary? Could it be avoided without loss of much performance? How critical was SEDA for the implementation.
The paper presents comprehensive evaluation results. While Pond does OK for reads (4 times faster than NFS) due to caching, its writes were slow (7 times slower than NFS) understandably due to erasure coding, threshold signed Byzantine agreement, and versioning costs.
Architecture
The system architecture is two tiered. The first tier consists of well connected hosts which serialize updates (running Byzantine agreement) and archive results. The second tier provides extra storage/cache resources to the system.

Replication and caching
Pond uses "erasure codes" idea for efficient and robust storage. Given storage is virtually unlimited today, they could as well have used full-replication and saved a lot of headache to themselves. The erasure coding leads to problems when reading. Several machines need to be contacted to reconstruct the block. What Pond does is, after a block is constructed it is kept at cache in the second tier replicas. So, the cost of consequent reads becomes low, and they compensate the initially high cost read.
Storing updates
Updates follow the path in Figure 2. Updates are both archived and cached simultaneously. The primary replica runs a Byzantine agreement, and the paper includes several implementation details related for that.
Implementation and evaluation
Pond is implemented on SEDA. This is a bit curious as Pond does not seem to have a long workflow. Was SEDA necessary? Could it be avoided without loss of much performance? How critical was SEDA for the implementation.
The paper presents comprehensive evaluation results. While Pond does OK for reads (4 times faster than NFS) due to caching, its writes were slow (7 times slower than NFS) understandably due to erasure coding, threshold signed Byzantine agreement, and versioning costs.






Comments