A comparison of filesystem workloads
Due to the increasing gap between processor speed and disk latency, filesystem performance is largely determined by its disk behavior. Filesystems can provide good performance by optimizing for common usage patterns. In order to learn and optimize for the common usage patterns for filesystems, this 2000 paper describes the collection and analysis of filesystem traces from 4 different environments. The first 3 environments run HP-UX (a UNIX variant) and are INS: Instructrional, RES: Research, WEB: Webserver. The last group, NT, is a set of personal computers running Windows NT.
Here are the results from their investigation.
Filesystem calls
Notable in all workloads is the high number of requests to read file attributes. In particular, calls to stat (including fstat) comprise 42% of all file-system- related calls in INS, 71% for RES, 10% for WEB, and 26% for NT. There is also a lot of locality to filesystem calls. The percentage of stat calls that follow another stat system call to a file from the same directory to be 98% for INS and RES, 67% for WEB, and 97% for NT. The percentage of stat calls that are followed within five minutes by an open to the same file is 23% for INS, 3% for RES, 38% for WEB, and only 0.7% for NT.
Block lifetime
Block lifetime is the time between a block's creation and its deletion. Knowing the average block lifetime for a workload is important in determining appropriate write delay times and in deciding how long to wait before reorganizing data on disk.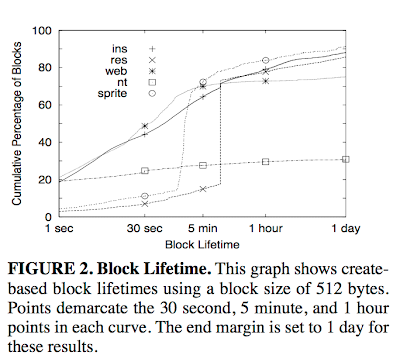 Unlike the other workloads, NT shows a bimodal distribution pattern: nearly all blocks either die within a second or live longer than a day. Although only 30% of NT block writes die within a day, 86% of newly created files die within that timespan, so many of the long-lived blocks belong to large files.
Unlike the other workloads, NT shows a bimodal distribution pattern: nearly all blocks either die within a second or live longer than a day. Although only 30% of NT block writes die within a day, 86% of newly created files die within that timespan, so many of the long-lived blocks belong to large files.
 Unlike the other workloads, NT shows a bimodal distribution pattern: nearly all blocks either die within a second or live longer than a day. Although only 30% of NT block writes die within a day, 86% of newly created files die within that timespan, so many of the long-lived blocks belong to large files.
Unlike the other workloads, NT shows a bimodal distribution pattern: nearly all blocks either die within a second or live longer than a day. Although only 30% of NT block writes die within a day, 86% of newly created files die within that timespan, so many of the long-lived blocks belong to large files. Lifetime locality
Most blocks die due to overwrites. For INS, 51% of blocks that are created and killed within the trace die due to overwriting; for RES, 91% are overwritten; for WEB, 97% are overwritten; for NT, 86% are overwritten.
A closer examination of the data shows a high degree of locality in overwritten files. In general, a relatively small set of files (e.g., 2%) are repeatedly overwritten, causing many of the new writes and deletions.
Effect of write delay The efficacy of increasing write delay depends on the average block lifetime of the workload. For nearly all workloads, a small write buffer is sufficient even for write delays of up to a day. User calls to flush data to disk have little effect on any workload.
The efficacy of increasing write delay depends on the average block lifetime of the workload. For nearly all workloads, a small write buffer is sufficient even for write delays of up to a day. User calls to flush data to disk have little effect on any workload.
 The efficacy of increasing write delay depends on the average block lifetime of the workload. For nearly all workloads, a small write buffer is sufficient even for write delays of up to a day. User calls to flush data to disk have little effect on any workload.
The efficacy of increasing write delay depends on the average block lifetime of the workload. For nearly all workloads, a small write buffer is sufficient even for write delays of up to a day. User calls to flush data to disk have little effect on any workload.Cache efficacy
Even relatively small caches absorb most read traffic, but there are diminishing returns to using larger caches.

Read and write traffic
File systems lay out data on disk to optimize for reads or writes depending on which type of traffic is likely to dominate. The results from the 4 environments do not support the widely-repeated claim that disk traffic is dominated by writes when large caches are employed. Instead, whether reads or writes dominate disk traffic varies significantly across workloads and environments. Based on these results, any general file system design must take into consideration the performance impact of both disk reads and disk writes.
File size
The study found that applications are accessing larger files than previously, and the maximum file size has increased in recent years. It might seem that increased accesses to large file sizes would lead to greater efficacy for simple read-ahead prefetching; however, the study found that larger files are more likely to be accessed randomly than they used to be, rendering such straightforward prefetching less useful.
File access patterns
The study found that for all workloads, file access patterns are bimodal in that most files tend to be mostly-read or mostly-written. Many files tend to be read mostly. A small number of files are write-mostly. This is shown by the slight rise in the graphs at the 0% read-only point. This tendency is especially strong for the files that are accessed most frequently. 

Concluding remarks
The message of the paper is clear. When it comes to filesystem performance, 3 things count: locality, locality, locality. Filesystem call locality, access locality, lifetime locality, read-write bimodality.
Naturally, after reading this paper you wonder if there is a more recent study on filesystem workloads to see which trends continued after this study. This 2008 paper "Measurement and Analysis of Large-Scale Network File System Workloads" provides such a study for a networked filesystem. The summary of its main findings are as follows.
Compared to Previous Studies
1. Both of the newer workloads are more write-oriented. Read to write byte ratios have significantly decreased. 2. Read-write access patterns have increased much more compared to read-only and write-only access patterns. 3. Most bytes are transferred in longer sequential runs. These runs are an order of magnitude larger. 4. Most bytes transferred are from larger files. File sizes are up to an order of magnitude larger. 5. Files live an order of magnitude longer. Fewer than 50% are deleted within a day of creation.
New Observations
6. Files are rarely re-opened. Over 66% are re-opened once and 95% fewer than five times. 7. Files re-opens are temporally related. Over 60% of re-opens occur within a minute of the first. 8. A small fraction of clients account for a large fraction of file activity. Fewer than 1% of clients account for 50% of file requests. 9. Files are infrequently shared by more than one client. Over 76% of files are never opened by more than one client. 10. File sharing is rarely concurrent and sharing is usually read-only. Only 5% of files opened by multiple clients are concurrent and 90% of sharing is read-only. 11. Most file types do not have a common access pattern.
It would be nice exploit the read-write bimodality of files while designing a WAN filesystem. Read-only files are very amenable to caching as they don't change. Write-only files are also good to cache and asynchronously write back to the remote home-server.





Comments